统计学中,Huber损失是用于鲁棒回归的损失函数,与平方误差损失相比,对数据中的游离点较不敏感。 也有时使用分类的变体。
1.定义
胡伯损失函数描述估计方法F招致的惩罚。Huber(1964)通过分段定义了损失函数。
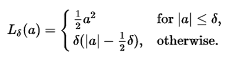
当a的值较小时,该函数为二次函数,当a的值较大时,该函数为线性函数,当|a|=delta时两函数具有相等的值和不同的斜率。变量a通常是指残差,即观测值和预测值之间的差值a=y-f(x)。所以上面的式子可以被扩展为:
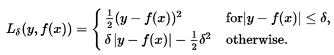
两个非常常用的损失函数是平方丢失,L(a)= a ^ 2,和绝对损失L(a)= | a |。 平方损失函数导致算术平均无偏估计,并且绝对值损失函数导致中值无偏估计量(在一维情况下,多维情况下的几何中位数 - 无偏估计量)。 平方损失的缺点是,它具有被异常值支配的倾向 - 当对一组a进行求和时(如L(a1)+...L(an).当分布很重时,样本平均值受到一些特别大的a值的影响太大.:在估计理论方面,平均值的渐近相对效率对于重尾分布是很差。
如上所述,Huber损失函数在其最小值a = 0的均匀邻域中是凸的,在该均匀邻域的边界处,Huber损失函数在点处具有可微分的仿射函数的扩展a=-delta和 a=delta。 这些属性允许它将平均无偏差的最小方差估计器(使用二次损耗函数)和中值无偏估计器的鲁棒性(使用绝对值函数)的大部分灵敏度相结合。
2.Pseudo-Huber loss 函数
Pseudo-Huber loss 函数可以用作Huber loss 函数的平滑近似,并确保派生物在所有程度上是连续的。 它被定义为

因此,对于a的小值,该函数近似于a ^ 2 / 2, 对于a的大值该函数近似于具有斜率delta。
虽然上述是最常见的形式,但是还存在Huber损失函数的其他平滑近似
3.用于分类的变体
为了分类,有时使用Huber损失的变体。 给定预测值f(x)(一个实值分类器得分)和一个真正的二进制类标签 y in (+ 1,-1),修改后的Huber损失定义为
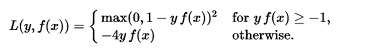
术语max(0,1-y.(f(x)^2))是支持向量机使用的铰链损失; 二次平滑的铰链损失L的泛化
4.应用
Huber损失函数用于鲁棒统计,M估计和加法建模