查看python已安装模块的方法小结
一、命令行下使用pydoc命令
在命令行下运行$ pydoc modules即可查看
二、在python交互解释器中使用help()查看
在交互式解释器中输入>>> help("modules")即可,效果跟在命令行下输入$ pydoc modules是一样的
三、在python交互是解释器下导入sys模块查看
python的sys模块也是可以用来查看模块信息的
>>> import sys
>>> sys.modules.keys()
四、命令行下使用pip查看
如果你使用的是pip来作为你的python包管理器的话,可以在命令行下直接运行$ pip freeze或者$ pip list来查看安装包的信息,当然其它的包管理器也有类似的功能,同时,你也可以在python交互式解释器中导入pip模块来查看包信息
numpy
np_city=np.array([[1.64,71.78],[1.37.63.35],...]) np.mean(np_city[:,0]) --计算numpy数组中中第一列的平均值,即平均身高 --1.7472 np.median(np_city[:,0]) --身高的中位数,即按身高由低到高排列,处于中间的那个人的身高值 --1.75
数据的产生
height=np.round(np.random.normal(1.75,0.20,5000),2)//随机产生5000个身高值
weight=np.round(np.random.normal(60.32,15,5000),2)//随机产生5000个体重值
np_city=np.column_stack((height,weight))//列连接
matplotlib
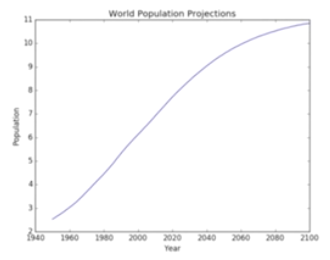
import matplotlib.pyplot as plt year=[1950,1970,1990,2010] pop=[2.519,3.692,5.263,6.972]
pop=[1.0,1.262.1.650]+pop --加上历史数据
year=[1800,1850,1900]+year plt.plot(year,pop) --第1个list作为x轴,第2个list作y轴
plt.fill_between(year,population,0,color='green') --填充为绿色
plt.xlabel('Year') --给x轴加标签
plt.ylabel('Population') --给y轴加标签,加标签一定要在show之前完成
plt.title('World Population Projections') --加标题
plt.yticks([0,2,4,6,8,10],['0','2B','4B','6B','8B','10B']) --给y轴标出刻度,第2个参数为单位
plt.show()

python的Re库的使用
编译正则表达式:
re.compile(pattern,flags=0):编译正则表达式,返回RegxObject对象
查找和匹配:
re.match(pattern,string,flags=0):从字符串的开头是否匹配正则表达式,匹配则返回MatchObject,如果不能匹配返回None
re.search(pattern,string,flags=0):在字符串中任意的位置查找,是否匹配正则表达式,匹配则返回MatchObject,反之,返回None
re.findall(pattern,string,flags=0):找到匹配的所有子串,并把它们作为一个列表返回,这个匹配是从左至右有序地返回。
group()用来提出分组截获的字符串(MatchObject)
字符串分离:
re.split(pattern,string,maxsplit=0):通过正则表达式将字符串分离
检索和替换:
re.sub() 将字符串中所有匹配正则表达式模式的部分进行替换,返回替换后的字符串。
re.subn() 将字符串中所有匹配正则表达式模式的部分进行替换,返回替换后的字符串和替换的次数。
其他:
re.finditer(pattern,string,flags=0):找到RE匹配的所有子串,并把它们作为一个迭代器返回。
re.escape(string):对字符串的非字母数字进行转义
re.purge():清空缓存中的正则表达式
修饰符:
re.I:忽略大小写
re.L:做本地化识别(locale-aware)匹配
re.M:多行匹配
re.S:匹配包括换行在内的所有字符
# coding:utf-8 import re if __name__=='__main__': #match匹配 # str1="helloworld" # an=re.match('[a-z]+$',str1) # if an: # print "全是小写" # else: # print "不全是小写" #search匹配 # str1="hello world" # an=re.search('^[a-z]+$',str1) # if an: # print "全是小写" # else: # print "不全是小写" ''' match表示从字符串开始的位置开始匹配, 而search表示从任意的位置开始匹配 ''' #regx对象匹配 # str1="helloworld" # regx=re.compile('^[a-z]+$') # # 对正则表达式进行编辑得到一个正则表达式对象 # an=regx.search(str1) # if an: # print "全是小写" # else: # print "不全是小写" #提取分组的字符串 # str1="1234abcd5678efgh91011ijkm" # obj=re.search('([0-9]+)([a-z]+)([0-9]+)([a-z]+)',str1) # print obj.group() #1234abcd5678efgh 相当于obj.group(0) # print obj.group(3) #5678 str1='peter:15905535003julia:18055381024' pattern='(0?(?:13|14|15|18)[0-9]{9})' # (后加?:表示查找时不分组,不加则表示分组 regex_phone=re.compile(pattern) print regex_phone.findall(str1)
类的定义
# 在定义类的函数时第1个参数必须是self class student: def __init__(self,id,name): self.id=id self.name=name def display_info(self): print("id:"+self.id+",name:"+self.name) student1=student('1001','jack') student2=student('1002','joan') student1.display_info() student2.display_info()
参数个数不定的函数定义
# coding:utf-8 def test1(arg1,*args): print("第1个参数:"+arg1) i=1 for arg in args: print("第"+str(i)+"个参数:"+arg) i=i+1 #不定长的参数(键值对) def test2(**kwargs): for key in kwargs: print(key,kwargs[key]) #不定长的参数和不定长的kvp参数 def test3(*args,**kwargs): print(args) print(kwargs) test1("hello","world","zyz") # 第1个参数:hello # 第1个参数:world # 第2个参数:zyz #方法1 test2(mike=23,kobe=24,james=6) # ('kobe', 24) # ('mike', 23) # ('james', 6) #方法2 player_infos={"Cury":31,"toms":11,"wall":12} test2(**player_infos) #注意这个实参需要加** # ('wall', 12) # ('toms', 11) # ('Cury', 31) #test3 args=[1,2,3] kwargs={"owen":21,"haden":13,"green":6} test3(*args,**kwargs) #注意实参前必须加* # (1, 2, 3) # {'green': 6, 'haden': 13, 'owen': 21}
map、filter、reduct函数、集合和三元运算
# encoding:utf-8 import numpy as np #将一个列表的所有数的平方根存入另一个列表 #1.使用for循环 list1=[1,4,9,16,25] sqrt1=[] #声明一个列表变量 for i in list1: sqrt1.append(np.sqrt(i)) print sqrt1 #----结果如下: # [1.0, 2.0, 3.0, 4.0, 5.0] #1.使用map list2=[1,4,9,16,25] sqrt2=[] #声明一个列表变量 sqrt2=map(lambda x:np.sqrt(x),list2) #对于list2中的每一个x都映射成它的平方根 #如果是python3版本,映射后还要转换为列表,如:sqrts=list(map(lamda x:np.sqrt(x),list2)) print sqrt2 #----结果如下: # [1.0, 2.0, 3.0, 4.0, 5.0] #map函数 def func1(x): return np.sqrt(x) def func2(x): return x*x funcs=[func1,func2] for i in range(1,9): val=map(lambda x:x(i),funcs) print list(val) #----结果如下: # [1.0, 1] # [1.4142135623730951, 4] # [1.7320508075688772, 9] # [2.0, 16] # [2.2360679774997898, 25] # [2.4494897427831779, 36] # [2.6457513110645907, 49] # [2.8284271247461903, 64] #filter函数 numbers=[1,-2,3,-5.5,4,6,0,9] positive_numbers=filter(lambda x:x>0,numbers) #从numbers列表中将符合条件的元素筛选出来组成一个列表 print positive_numbers #----结果如下: # [1, 3, 4, 6, 9] #reduce函数 product=reduce(lambda x,y:x*y,[3,4,5,6]) print product #----结果如下: # 360 # 使用集合 a_list=[1,2,3,1,5,3,6] a_set=set(a_list) print a_set # set([1, 2, 3, 5, 6]) set1=set([1,2,3,4,5,6,7]) set2=set([9,8,7,6,5]) print set1.intersection(set2) #交集 # set([5, 6, 7]) print set1.difference(set2) #差集 # set([1, 2, 3, 4]) #使用三元运算符 hungry=True action="lunch" if hungry else "work" print action #----结果如下: # lunch
装饰器
# encoding:utf-8 from functools import wraps #定义一个装饰器 def a_decorator(func): @wraps(func) #防止被装饰的函数的属性被修改。加入此句后,被装饰的函数名能正确显示,不再显示wrap_func, def wrap_func(): print("调用前...") func() print("调用后...") return wrap_func #定义一个要装饰的函数 def a_func(): print("this is a function!") a_func()#装饰之前 # this is a function! a_func=a_decorator(a_func)#装饰 a_func()#装饰之后 # 调用前... # a_func to be decorated! # 调用后... #改进装饰 @a_decorator def b_func(): print("this is b function!") b_func() # 调用前... # this is b function! # 调用后... #获取函数名 def c_func(): print("this is c function!") print(c_func.__name__)#未装饰的函数的函数名 #c_func print(b_func.__name__)#装饰后的函数的函数名 #warp_func #可以在装饰器里的定义的函数前加@warps(func) #加上@wraps(func)后输出: b_func #demo def b_decorator(f): @wraps(f) def decorated(*args,**kwargs): if not can_run: return "function will not run!" return f(*args,**kwargs) return decorated @b_decorator def bb_func(): return("Function is running!") can_run=False print(bb_func()) #demo:在日志中记录这个函数被调用的信息 def e_decorator(func): @wraps(func) def logging(*args,**kwargs): print(func.__name__+" was called!") return(func(*args,**kwargs)) return logging @e_decorator def e_func(x): return x*x result=e_func(5) print result # e_func was called! # 25
可变数据类型、推导式、lambda表达式
# encoding:utf-8 a=["hello"] print a #['hello'] b=a b.append("world") print a #['hello', 'world'] #列表是可变类型,相当于C#和java中引用类型,a,b指向的是同一对象。 #使用列表作为默认参数 def add_to(num,target=[]): target.append(num) return target t=add_to(1) print t #[1] t=add_to(2) print t #[1, 2] t=add_to(3) print t #[1, 2, 3] #在python中默认参数只是计算一次,不是每次调用时都要重新计算,所以我们要避免使用可变类型作为默认参数 #改进后 def add_to(num,target=None): if target is None: target=[] target.append(num) return target t=add_to(1) print t #[1] t=add_to(2) print t #[2] t=add_to(3) print t #[3] #---------推导式可以使用我们的代码更加简洁 #1.列表推导式 a_list=[i for i in range(30) if i % 3==0] print a_list # [0, 3, 6, 9, 12, 15, 18, 21, 24, 27] #注意range函数不包含终值(30) b_list=[x**2 for x in range(10)] print b_list # [0, 1, 4, 9, 16, 25, 36, 49, 64, 81] #字典推导式 a_dict={'a':3,'b':4,'c':5,'A':11,'C':13} b_dict={k.lower():a_dict.get(k.lower(),0)+a_dict.get(k.upper(),0) for k in a_dict.keys()} print b_dict # {'a': 14, 'c': 18, 'b': 4} #集合推导式 a_set={x**2 for x in [1,2,1]} print a_set # set([1, 4]) #lambda表达式:也叫匿名函数, add=lambda x,y:x+y #x,y相当于函数的参数,x+y相当于函数的返回值。 print add(3,4) # 7
python web.py
djanggo支持python2和python3
djanggo是一个重量级的框架,自动化程度很高,我们甚至只需要写视图就可以了。
flask也支持python2和python3
web.py轻量级的开发框架,支持 pyhton2
web.py2支持python3
# -*- coding:utf-8 -*-
其中coding:utf-8两边加“-*-”这是业界公认一种习惯
python是完全依靠路由来定义页面,它没有传统的页面文件,如:index.php
ORM模型
环境搭建:
1、安装 web.py
pip install web.py #pip是python的包管理工具
2、下载安装MySQL for python
MySQl database connector for python programming
https://sourceforge.net/projects/mysql-python/
# -*- coding:utf-8 -*- import web urls=( '/','Index', '/reg','Reg', '/login','Login' ) render=web.template.render('templates')#jinja2的模板引擎,templates为模板文件所在文件夹 # /表示网站根目录,也就是首页,index表示处理首页请求的一个方法 db=web.database( dbn='mysql', host='localhost', port=3306,#不能写成字符串的形式 user='root', pw='root', db='news', charset='utf8', ) class Index: def GET(self): #根据用户的请求方式来确定方法名,如:GET、POST return render.header() #header为"header.html"的主文件名,它是作为一方法来调用,所以有括号 class Reg: def GET(self): return render.reg(render.header()) def POST(self): web.header('Content-Type','text/html;charset=UTF-8') #设置响应头的字符编码为UTF-8,否则中响应的中文会乱码 i=web.input()#可以用于GET或POST请求,i得到的是一个字典 # web.data()#可用于POST请求 # print i # roleName=i['roleName']#这种方法可以得到,但如果key值不存在,就可以会报异常 roleName=i.get('roleName')#这种方式即使key值不存在,也不会报异常 if len(roleName)==0: return u'角色名不能为空!' db.query("insert into role(roleName) values('%s')"%(roleName)) #%s为占位符,其后应该有%(值)来替代 return u'添加成功!' class Login: def GET(self): return render.login(render.header()) def POST(self): i=web.input() roleName=i.get('roleName') data=db.query("select * from role where roleName='%s'"%(roleName)) if not data: return u'没有此角色' web.seeother("/") app=web.application(urls,globals()) if __name__=='__main__': app.run() #运行web应用程序,然后就可以发出http请求
查看python已安装模块的方法小结
随着使用python的时间越来越长,安装的python模块也越来越多,时间久了都不记得自己之前到底对自己的电脑做过些什么了,于是乎就想要查看一下自己安装的python模块,现将查看方法总结如下
一、命令行下使用pydoc命令
在命令行下运行
$ pydoc modules即可查看
二、在python交互解释器中使用help()查看
在交互式解释器中输入
>>> help("modules")即可,效果跟在命令行下输入$ pydoc modules是一样的
三、在python交互是解释器下导入sys模块查看
python的sys模块也是可以用来查看模块信息的
>>> import sys
>>> sys.modules.keys()- 1
- 2
- 3
四、命令行下使用pip查看
如果你使用的是pip来作为你的python包管理器的话,可以在命令行下直接运行
$ pip freeze或者$ pip list来查看安装包的信息,当然其它的包管理器也有类似的功能,同时,你也可以在python交互式解释器中导入pip模块来查看包信息