一般情况下,我们建立数据库表时,表数据都存放在一个文件里。
但是如果是分区表的话,表数据就会按照你指定的规则分放到不同的文件里,把一个大的数据文件拆分为多个小文件,还可以把这些小文件放在不同的磁盘下由多个cpu进行处理。这样文件的大小随着拆分而减小,还得到硬件系统的加强,自然对我们操作数据是大大有利的。这样的话我们的数据表逻辑上仍然是一张表,但是物理上其实是多张表。
所以大数据量的数据表,对分区的需要还是必要的,因为它可以提高select效率,还可以对历史数据经行区分存档等。但是数据量少的数据就不要凑这个热闹啦,因为表分区会对数据库产生不必要的开销,除啦性能还会增加实现对象的管理费用和复杂性。
接下来按照步骤来试试,顺便测试下同样的数据,分区表和非分区表的效率对比:
1.创建文件组
可以点击数据库属性在文件组里面添加
T-sql语法:
alter database <数据库名> add filegroup <文件组名>

---创建数据库文件组 alter database testSplit add filegroup ByIdGroup1 alter database testSplit add filegroup ByIdGroup2 alter database testSplit add filegroup ByIdGroup3
2.创建数据文件到文件组里面
可以点击数据库属性在文件里面添加
T-sql语法:
alter database <数据库名称> add file <数据标识> to filegroup <文件组名称> --<数据标识> (name:文件名,fliename:物理路径文件名,size:文件初始大小kb/mb/gb/tb,filegrowth:文件自动增量kb/mb/gb/tb/%,maxsize:文件可以增加到的最大大小kb/mb/gb/tb/unlimited)
alter database testSplit add file (name=N'ById1',filename=N'E:SQLDataById1.ndf',size=5Mb,filegrowth=5mb) to filegroup ByIdGroup1 alter database testSplit add file (name=N'ById2',filename=N'E:SQLDataById2.ndf',size=5Mb,filegrowth=5mb) to filegroup ByIdGroup2 alter database testSplit add file (name=N'ById3',filename=N'E:SQLDataById3.ndf',size=5Mb,filegrowth=5mb) to filegroup ByIdGroup3
执行完成后,右键数据库看文件组跟文件里面是不是多出来啦这些文件组跟文件。
3.使用向导创建分区表
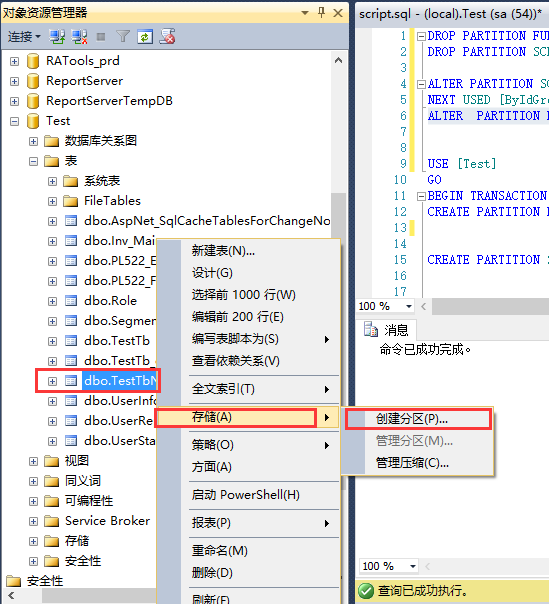
此操作可能会有朋友会遇到有邮件数据表没有储存选项,这个原因目前笔者发现是SQL版本的问题,目前只有专业版和开发版的才支持,你可以如果没有这个选项,你可以查看下自己的SQL版本,运行脚本
SELECT @@version
如果是标准版的,升级下SQL版本即可,怎么升级?百度一下有很多,笔者在此就一笔带过说下具体步骤:SQL安装文件夹》setup.exe》升级版本》下一步》到输入秘钥的时一定记得输入企业版或者开发版秘钥,稍等片刻就会提示升级成功

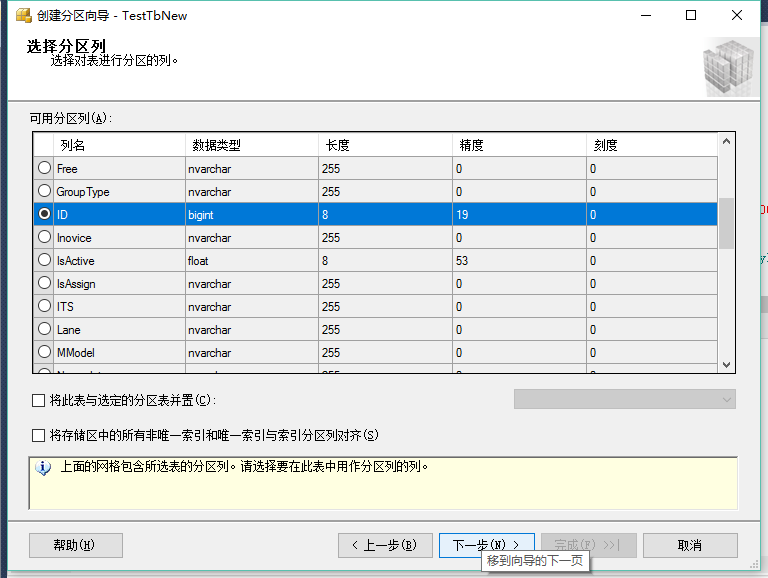
这里举例说下选择列的意思:
假如你选择的是int类型的列:那么你的分区可以指定为1--20W是一个分区,20W--40W是一个分区....
假如你选择的是datatime类型:那么你的分区可以指定为:2014-01-01--2014-01-31一个分区,2014-02-01--2014-02-28一个分区...
根据这样的列数据规则划分,那么在那个区间的数据,在插入数据库时就被指向那个分区存储下来。

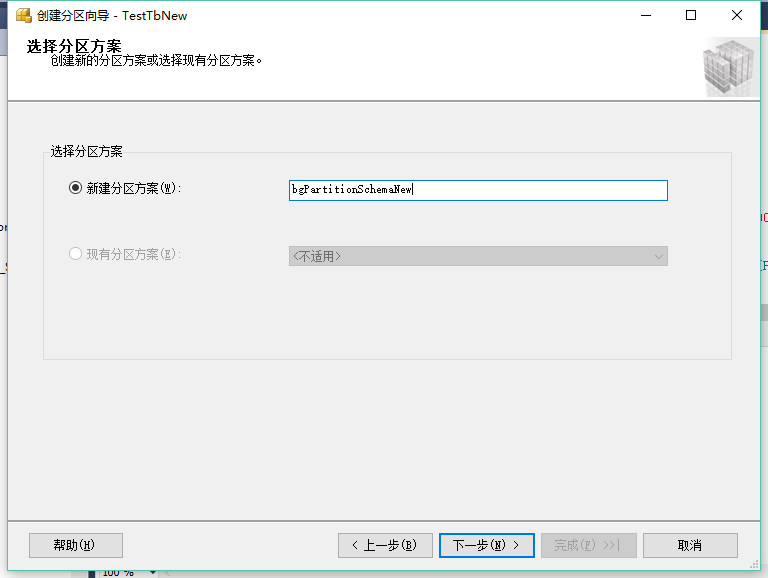
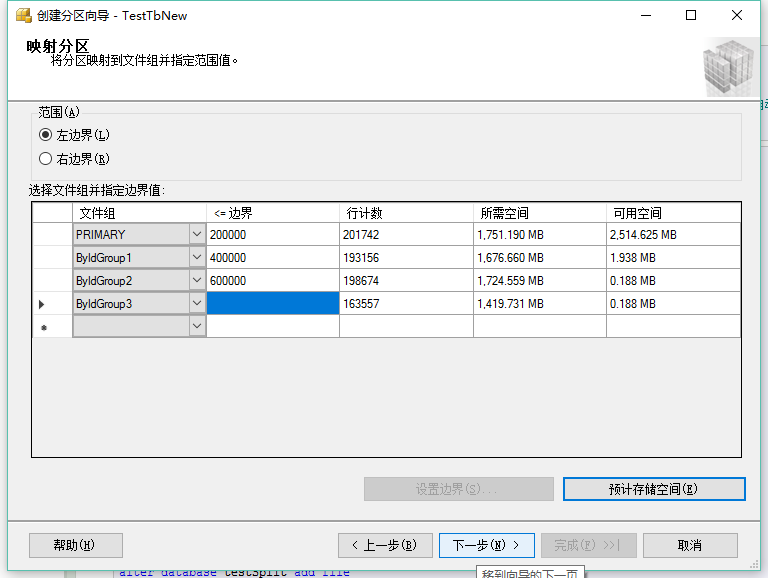
左边界右边界:就是把临界值划分给上一个分区还是下一个分区。一个小于号,一个小于等于号。
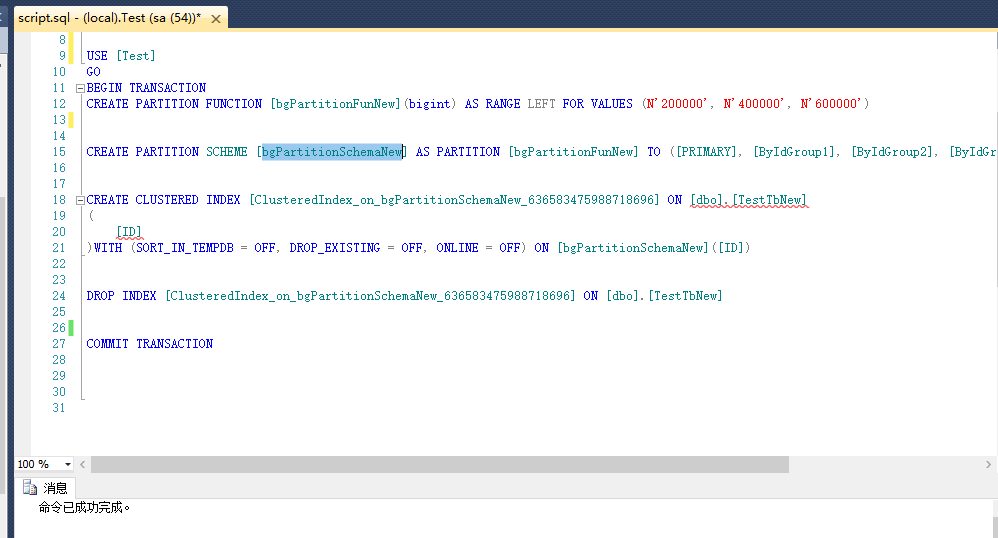
执行上面向导生成的语句。分区完成。此时可以右键表,看下属性和其他未做分区的表有所不同。
4.对比下同样的数据,分区前和分区后的执行效率
分区表执行情况(值得注意的是右下角执行时间):

未分区执行情况(值得注意的是右下角执行时间):

为了方便对比查看,将两个情况执行结果放到一起

可见一个反常现象,分区表扫描次数跟逻辑读取次数都是无分区表的2倍之多,但查询速度却是快了不少啊。这就是分区的神奇之处啊,所以要相信这世界一切皆有可能。
表数据量越大和查询数据越多,此结论越明显。就笔者测试,按照以上例子,如果只查询>400000 and <= 401000的数据时,此结论并不是太明显。