首先我们来了解一些Spark的优势:
1.每一个作业独立调度,可以把所有的作业做一个图进行调度,各个作业之间相互依赖,在调度过程中一起调度,速度快。
2.所有过程都基于内存,所以通常也将Spark称作是基于内存的迭代式运算框架。
3.spark提供了更丰富的算子,让操作更方便。
4.更容易的API:支持Python,Scala和Java
其实spark里面也可以实现Mapreduce,但是这里它并不是算法,只是提供了map阶段和reduce阶段,但是在两个阶段提供了很多算法。如Map阶段的map, flatMap, filter, keyBy,Reduce阶段的reduceByKey, sortByKey, mean, gourpBy, sort等。
那么话不多说,上源码~~~

上面是源代码中对RDD的解释:
1、是一个有分区的集合
2、在每一个切片(分区)上都有一个相应的函数,一一对应的
3、每个RDD都会依赖的上一个RDD
4、(可选)如果是(K,V)类型的RDD,会采用分区器(默认的是Hash-Partitioner,规则是key的hashCode 值除以下游模的数量)
RDD是一个抽象的数据集,并不是用来装真正要计算的数据,而装的是处理数据的描述信息(即,对哪个文件进行计算,该怎么计算),任何数据在Spark中都被表示为RDD,从编程角度来看,RDD可以简单的看成一个数组,和普通的数组的区别是,RDD中的数据是分布式存储的,这样不同分区的数据就可以分布在不同的机器上,同时可以被并行化处理。因此,Spark应用程序所做的无非是把需要处理的数据转换成RDD,(在这个过程一定要学会区分transformation和action)然后RDD进行一系列的变换和操作从而得到结果。
那么我们该如何创建RDD呢?
RDD可以从普通数组创建出来,也可以从文件系统或者HDFS的文件创建出来。
方式1、举例:从普通数组创建RDD,里面包含了1到9这9个数字,他们分别在3个分区中。
scala>val a=sc.parallelize(1 to 9, 3) //3是指有三个分区,parallelize是把数据并行化 a:org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[1] at parallelize at <console>:12
方式2、举例:读取文件README.md来创建RDD,文件中的每一行就是RDD中的一个元素
scala> val b = sc.textFile("README.md")
b: org.apache.spark.rdd.RDD[String] = MappedRDD[3] at textFile at <console>:12
scala>val distFile = sc.textFile("data.txt")
distFile:RDD[String]= MappedRDD@1D4CEE08
distFile.map(s =>s.length).reduce((a+b) =>a+b)
虽然还有别的方式可以创建RDD,但在本文中我们主要使用上述两种方式来创建RDD以说明RDD的API.
下面带给大家一个WordCount例子的图解
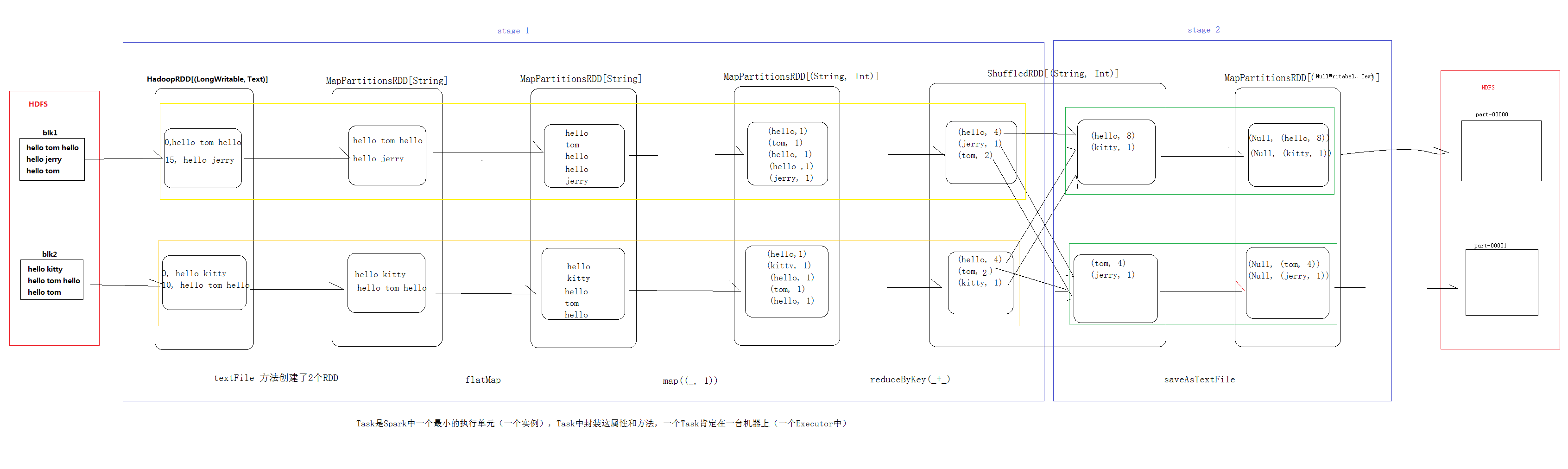
分区和分区器的区别:
分区代表并行度,分区越多,并行度越高,一个分区相当于一个task
自定义分区器,决定了在shuffle时候,上游的数据要到下游的哪一个分区
数据均匀分散在多个分区里,每个分区会对应一个task进行计算

在这里,再次描述Spark任务执行流程:
1.把一个Spark程序打成一个Jar包,然后用spark-submit运行,提交到集群 --> Application
2.RDD经过一些转换后,触发Action,这样就形成一个完整的DAG --> Job
3.对DAG根据窄宽依赖(shuffle)进行切分,会生成很多阶段 --> Stage
4.一个Stage会生成多个任务(任务就是一个Java实例,里面有属性和方法)--> Task
注:Task是Spark中最小的执行单元,在资源充足的情况下,Task数量越多(并行),任务执行的越快
Task中方法的计算逻辑是串行的(严格遵循调用顺序)
一个Job(DAG)可以有一个到多个Stage,Stage的提交,要严格的按照先后顺序
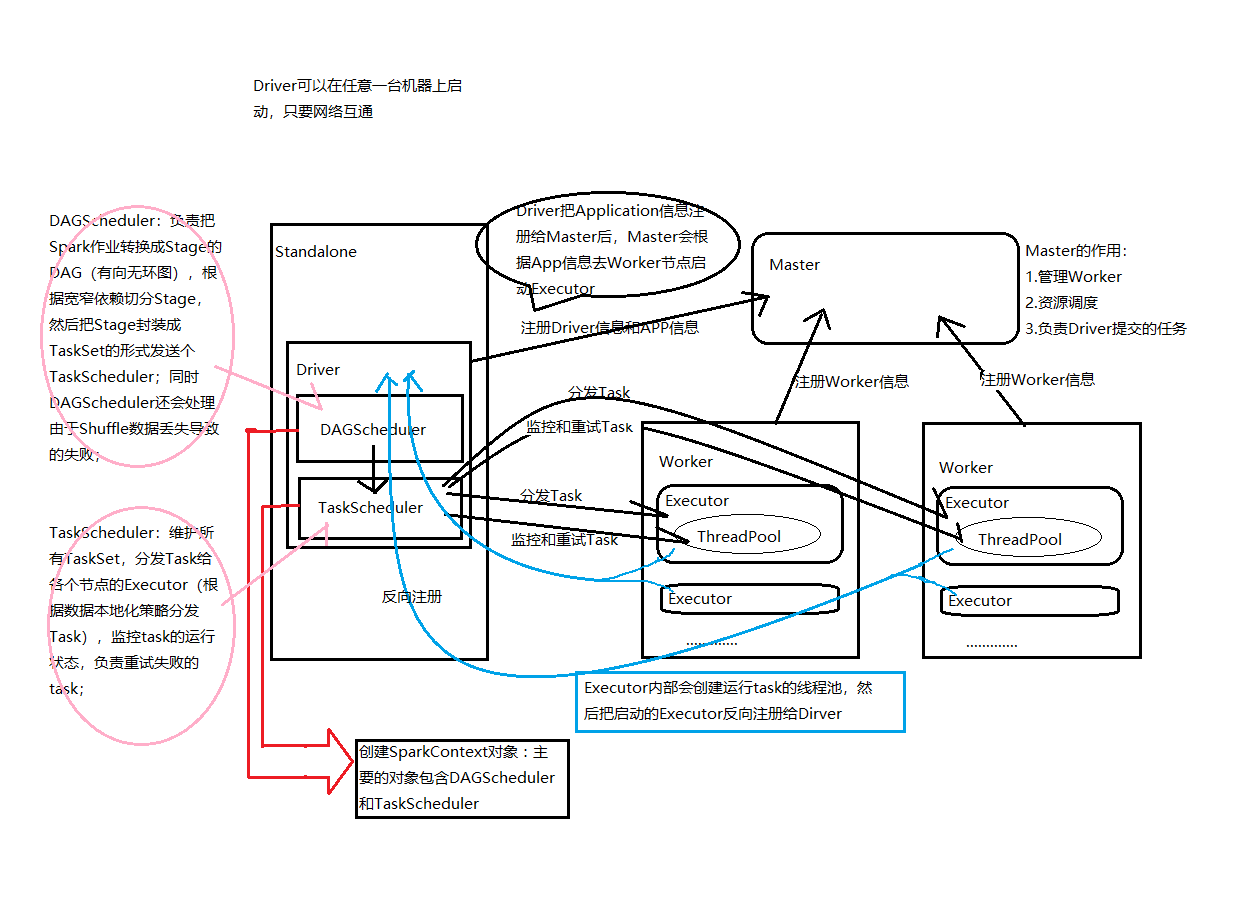
具体流程
1、构建DAG:DAGScheduler负责把Spark作业转换成Stage的DAG(Directed Acyclic Graph有向无环图)
2、DAGScheduler根据宽窄依赖切分Stage,然后把Stage封装成TaskSet的形式发送个TaskScheduler;
3、TaskScheduler:维护所有TaskSet,分发Task给各个节点的Executor,spark在提交Application时,可以指定总共占用的内核数(可以简单理解为线程数量),同时也可以指定task的数量,一个task占用一个线程,如果,task的数量大于内核的数量,则没有占用到内核的task会等待其他的task执行完毕,释放资源后,再占用。(原谅我举个不雅的例子,仔细想有没有就像厕所入坑的一样,所有坑被占用时,其他人会等待....)
4、excutor根据数据本地化策略分发Task到线程池,开始执行run方法
5、TaskScheduler监控task的运行状态,负责重试失败的task;
6、所有task运行完成后,SparkContext向Master注销,释放资源;
那么现在我们理解了RDD,也理解了Spark执行流程,最后,我们再把RDD放在流程中,相信你可以有所收获的
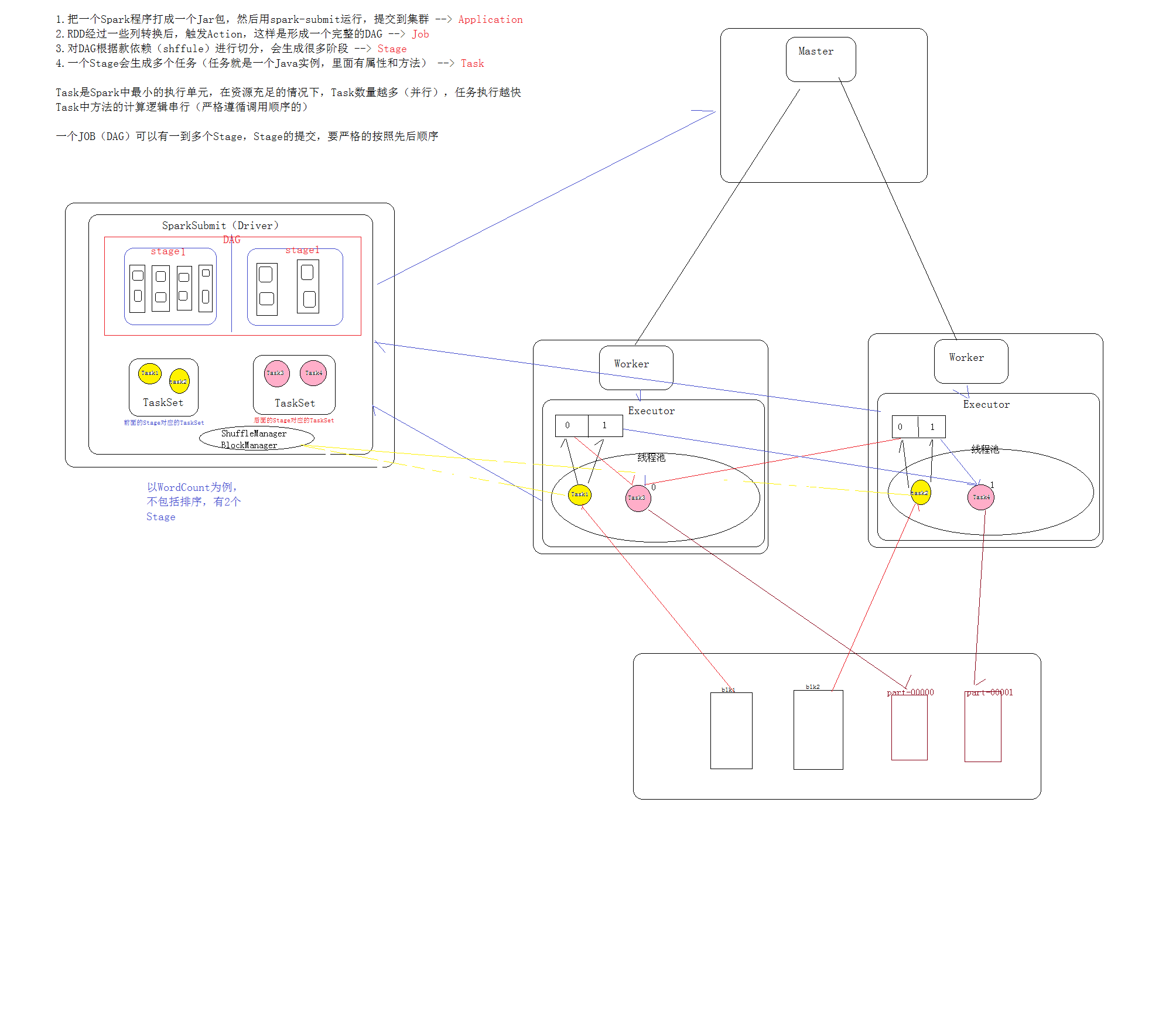
坚持资源共享的原则,写的有错的地方多谢指正。。。。。