字节流和字符流
-
IO流技术
-
IO流的分类
-
File类,它可以操作文件或文件夹,但是它不能操作(读写)文件中的数据。
如果程序中需要读写文件中的数据,这时需要使用Java提供的专门负责读写数据的IO流对象。
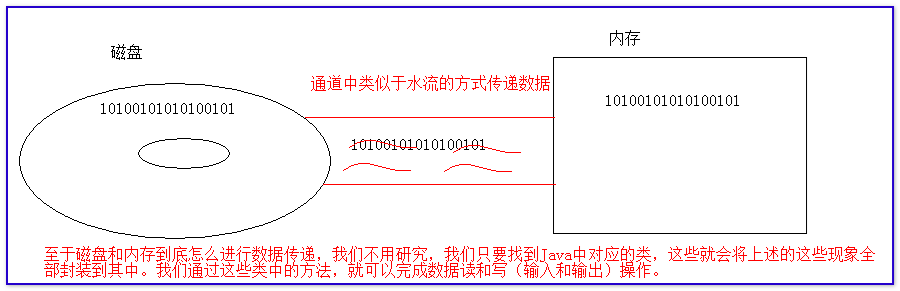
IO流:以水流的方式来操作文件中的数据。在内存和我们持久设备之间如果要进行数据读写操作,那么我们就需要和持久设备之间建立数据传输的通道。在这个通道中传输的数据可以称为通道中的真正的数据。而这个数据以字节(10101001010010101)的形式传递。
File:只能操作文件或文件夹。
IO流:它是专门读写文件中的数据。
IO流对应的类或接口很多,这时我们可以按照操作的数据的特点将IO流分成:
-
字节流
-
字符流
也可以按照IO流的方向:
-
输入流
-
输出流
我们上课采用数据的特点:字节流和字符流方式学习。
数据在持久设备上全部是1010010100101 方式存储,二进制方式。8个二进制数位和在一起,恰好是一个字节。字节也是存储设备中的最小的单位。
所以我们先按照字节的方式操作。永远不会出现数据的错乱问题。
在整个IO流中,只要学会字节流的操作,其他任何流的操作规律完全一致。
-
字节流介绍
字节流:它是以字节的方式读写文件中的数据。
字节流:
字节输入流:
以字节的方式从文件中读取字节,将字节数据读取到计算机的内存(Java程序)中。
字节输出流:
以字节的方式将内存(程序)中数据写到文件中。
字节输入流:
InputStream
字节输出流:
OutputStream
IO流中公共操作行为:
在操作数据之前,肯定需要和设备之间有个数据交互的通道(其实就是让我们的Java代码可以间接和被操作的文件关联上)。记住,在操作之后,必须人为的书写代码,将我们的程序和文件之间的关联断开。
断开和文件的关联:在IO流中有一个统一的方法close。
IO流中写的方法write ,读的方法 read。
-
字节输出流


使用完流,一定要记得调用close方法,关闭资源。

write( byte[] b ) : 在调用write方法的时候,会将传递的整个byte数组中的数据写到关联的文件中。
write( byte[] b , int off , int len ) : 将byte数组中从off位置开始共计写出len个字节。
write( int b ) : 写出一个字节。
-
文件字节输出流


FileOutputStream它是OutputStream的子类,它可以直接将数据以字节的方式写到文件中。
// 写出数据
public static void demo1() throws IOException {
// 创建输出流对象 FileOutputStream(String name)
FileOutputStream fos = new FileOutputStream("e:/1.txt");
String s = "覆盖掉啦!!!";
// 写数据
fos.write( s.getBytes() );
// 关流
fos.close();
}
注意:FileOutputStream,在创建的时候,如果关联的文件不存在,它会自动的创建。如果文件存在,会覆盖掉文件中原有的数据。
如果指定的文件所在目录不存在FileOutputStream不会帮助创建,这时会直接发生异常
-
追加数据和换行
// 在输出的数据后面换行
public static void demo3() throws IOException {
FileOutputStream fos = new FileOutputStream("e:/11.txt" , true);
/*
* 换行符,windows和linux系统也不同:
* windows:
* linux: /n
* 如果我们在程序中需要使用换行符的时候,不建议直接书写换行符号,
* 其实在Java中的System类中,有个方法可以获取和系统相关 的分隔符号:
* System.getProperty("line.separator") 获取系统相关的换行符
*/
String s = "第一节课,有同学就想睡觉!!!" + System.getProperty("line.separator");
fos.write(s.getBytes());
fos.close();
}
// 演示在文件的末尾追加数据
public static void demo2() throws IOException {
/*
* 创建字节输出流对象
* FileOutputStream(String name, boolean append)
* String name : 指定的文件
* boolean append : 这个boolean如果是true,就表示在原有的文件后面继续追加数据
* 如果指定的文件不存在,这时它会创建文件,如果文件存在,在文件中追加数据
*
*/
FileOutputStream fos = new FileOutputStream("e:/11.txt" , true);
String s = "这是追加的数据";
fos.write(s.getBytes());
fos.close();
}
-
字节输入流

InputStream:它是字节输入流的超类(根类、基类、公共父类)。它中定义字节输入流最基本的读取字节的方法

释放资源,在操作完文件之后,一定要关闭流和文件之间的关联。

上面的三个read方法都可以从底层读取字节数据。
read() : 这个方法只要被调用一次,就会从底层读取一个字节数据,并将读取到这个字节数据返回。
read( byte[] b ) : 这个方法调用一次,它会从底层读取多个字节数据,将读取到的字节数据保存到方法上接收的byte数组中。 返回的int值表示的是给byte数组中存储的字节个数(方法在执行的时候,从底层读取的字节个数)。
-
文件字节输入流

FileInputStream:它是文件字节输入流,可以从文件中按照字节的方法读取字节数据。

-
一次读取一个字节
InputStream类中三个read方法:
其中read() 方法是每次读取一个字节数据,并返回读取到的这个字节数据。如果读取到文件末尾,这时会返回-1,因此我们可以通过返回的结果是否为-1判断read有没有将文件中的数据读取结束。在真正读取文件中的数据的时候,需要使用循环读取,循环的判断条件就是读取内容不等于-1.
// 使用循环读取文件中的数据
public static void demo2() throws IOException{
// 创建字节输入流对象
FileInputStream fis = new FileInputStream("e:/11.txt");
/*
* 由于 输入流的read() 它一次只能读取一个字节数据,并且返回这个字节数据,
* 类型恰好是int类型,因此我们可以自己定一个变量保存每次读取的字节数据
*/
int ch = 0;
/*
* 执行流程:
* while( ( ch = fis.read() ) != -1 )
* 先执行:( ch = fis.read() )
* 小括号中是一个赋值表达式,这时就需要先执行赋值号右边的代码,将结果赋值给左边的变量
* 右边的代码是使用输入流从底层读取一个字节数据。最后将这个字节数据赋值给ch变量
* 最后是将ch变量中的数据和-1 进行判断,只要不是-1,循环就会成立,而不是-1,恰好表示没有读取到文件的末尾
*/
while( ( ch = fis.read() ) != -1 ){
System.out.println(ch);
}
// 关流
fis.close();
}
// 简单演示读取数据
public static void demo1() throws IOException {
// 创建字节输入流对象
FileInputStream fis = new FileInputStream("e:/11.txt");
// 读取数据
System.out.println(fis.read());
System.out.println(fis.read());
System.out.println(fis.read());
System.out.println(fis.read());
// 关流
fis.close();
}
-
一次读取多个字节数据
在InputStream类中,read(byte[] b) : 它可以从底层读取多个字节数据,将数据存储在传递的byte数组中。返回给数组中存储的字节个数,同样如果这个read方法读取到文件末尾,也会返回-1.
// 一次读取多个字节数据
public static void demo3() throws IOException {
// 创建字节输入流对象
FileInputStream fis = new FileInputStream("e:/11.txt");
/*
* 需要定一个byte数组,作为临时存储读取的字节数据的容器
* 一般定义的用于存储读取的字节数据的byte数组的长度
* 为1024的整数倍。
* 1字节 = 8 二进制位数
* 1kb = 1024byte
* 1mb = 1024kb
* 1gb = 1024mb
* 1tb = 1024 gb
* 1pb = 1024 tg
*/
byte[] buf = new byte[1024];
// 定义一个用于接收到底读取了多少个字节数据的变量
int len = 0;
/*
* 使用循环读取字节数据
* ( len = fis.read(buf) ) != -1
* 1、fis.read(buf)
* 从关联的文件中读取字节数据,将读取的字节数据存储到指定的byte数组buf中。
* 2、len = fis.read( buf )
* 输入流将读取的字节数据存储到字节数组中之后,它需要将读取的字节个数存储在len中。
* 3、将len中的数据和-1进行比较,如果可以读取到数据len中的值肯定不是-1,如果读取到文件末尾
* read方法 将会返回-1,肯定数组中是不会再存储任何数据,这时就代表文件中的数据被读取完了。
*/
while( ( len = fis.read(buf) ) != -1 ){
/*
* 数据已经在定义的字节数组中,我们只要去处理数组即可
* 假设现在需要:将存储在数组中的数据打印,
* 注意:由于定义的数组容量比较大,不一定会将数组中的所有空间全部存放数据,
* InputStream中的read方法在读取多个字节的时候,只要read方法执行一次,它每次都会将
* 读取到的字节数据从指定的数组的0位置开始存储。
* 处理保存读取的字节数据的数组空间,没有必要每次都将整个数组进行处理,因为数组有可能存储不满
* 所以在处理的时候,一般仅仅只处理的到len即可。
*
* 后期处理读取到的字节数据的时候,最常用的处理方法之一:
* 将字节数中的所有数据转成String,然后处理这个字符串
*/
String s = new String( buf , 0 , len );
System.out.println(s);
}
// 关流
fis.close();
注意:主要是输入流的read方法,当它读取到文件最后的位置(末尾、结束)统一返回-1.
-
复制文件练习(重点练习)
-
分析文件复制的过程
-
复制文件的原理:
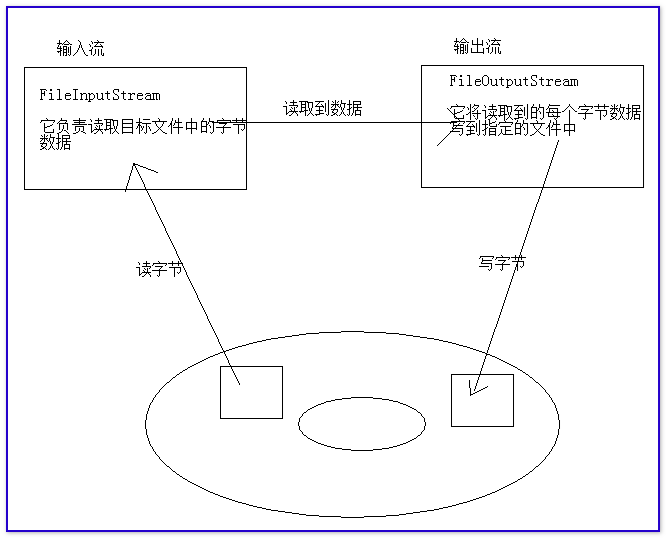
-
Java实现文件复制(两种复制方式必须知道它们效率高低的原因)
/*
* 方式一复制文件,由于是按照一个一个字节的方式读写,这种效率很低,因此我们建议使用第二种方式
* 定义一个数组,然后一次可以从底层读取多个字节数据,然后将多个字节数据一次写到目标文件中
*/
public static void demo2() throws IOException {
// 创建输入流,读取文件
FileInputStream fis = new FileInputStream("e:/1.exe");
// 创建输出流,用户写字节数据
FileOutputStream fos = new FileOutputStream("c:/1.exe");
// 在复制之前获取系统的时间
long start = System.currentTimeMillis();
// 定义字节数组
byte[] buf = new byte[8192];
int len = 0;
while ((len = fis.read(buf)) != -1) {
// 将读取的字节数据写到文件中
fos.write(buf, 0, len);
}
// 在复制之前获取系统的时间
long end = System.currentTimeMillis();
System.out.println("复制文件所需的时间:" + (end - start));
// 关流
fis.close();
fos.close();
}
// 演示复制文件
public static void demo1() throws IOException {
// 创建输入流,读取文件
FileInputStream fis = new FileInputStream("e:/1.exe");
// 创建输出流,用户写字节数据
FileOutputStream fos = new FileOutputStream("c:/1.exe");
// 在复制之前获取系统的时间
long start = System.currentTimeMillis();
// 演示按照读取一个字节的方式复制文件
int ch = 0;
while ((ch = fis.read()) != -1) {
// 在循环中,将读取的字节数据使用输出流写到文件中
fos.write(ch);
}
// 在复制之前获取系统的时间
long end = System.currentTimeMillis();
System.out.println("复制文件所需的时间:" + (end - start));
// 关流
fis.close();
fos.close();
}
}
-
IO流中的异常处理模版
在IO技术中,我们需要使用流对象和持久设备上文件进行关联,然后读写文件中的数据。由于操作的数据不是Java程序中自己本身的数据,因此在操作的过程中难免会发生其他的一些无法预知的问题。
例如:正在写的时候,磁盘被写满了。读取文件的时候,文件不存在。读写文件的时候,指定的目录不存在。这些情况都会发生异常。
如果在程序中发生了异常,在发生异常的位置程序就会直接终止运行,就会导致关闭流的代码有可能无法被执行。那么流就会和文件一直关联着。
/*
* 演示IO流中的异常模版处理代码
*/
public class IOExceptionDemo {
public static void main(String[] args) {
demo2();
}
public static void demo2() {
// 创建输入流,读取文件
FileInputStream fis = null ;
// 创建输出流,用户写字节数据
FileOutputStream fos = null ;
try{
fis = new FileInputStream("e:/1.exe");
fos = new FileOutputStream("c:/1.exe");
// 在复制之前获取系统的时间
long start = System.currentTimeMillis();
// 定义字节数组
byte[] buf = new byte[8192];
int len = 0;
while ((len = fis.read(buf)) != -1) {
// 将读取的字节数据写到文件中
fos.write(buf, 0, len);
}
// 在复制之前获取系统的时间
long end = System.currentTimeMillis();
System.out.println("复制文件所需的时间:" + (end - start));
}catch( IOException e ){
System.out.println("复制文件挂啦!!!");
e.printStackTrace();
// 后期开发在catch到异常之后,需要使用IO流将异常的信息写到指定的文件(日志)中
}finally{
// 关流
if( fis != null ){
try {
fis.close();
} catch (IOException e) {
e.printStackTrace();
}
}
// 强制将fis赋值为null
fis = null ;
if( fos != null ){
try {
fos.close();
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
fos = null;
}
}
}
-
输入流读取数据模版代码(必须记住)
InputStream类中提供read方法可以读取字节数据,根据read方法的特点,将读取字节数据分成两种方案:
1、一次读取一个字节模版代码
// 创建流对象
FileInputStream fis = new FileInputStream("文件");
// 定义变量,保存每次读取到的那个字节数据
int ch = 0;
// 使用循环读取数据
while( ( ch = fis.read() ) != -1 ){
在循环中处理读取到的字节数据,字节数据就存在ch中。
}
// 关流
fis.close();
2、一次读取多个字节的模版代码
// 创建流对象
FileInputStream fis = new FileInputStream("文件");
// 定义字节数组,用于存储每次读取到的多个字节数据
byte[] buf = new byte[1024];
// 定义变量,用于记录每次读取的字节个数
int len = 0;
// 使用循环读取数据
while( ( len = fis.read( buf ) ) != -1 ){
在循环中处理读取到的字节数据,数据存储在字节数组中buf中,其中共计存储len个字节
}
// 关流
fis.close();
-
字节流练习(切割合并文件)
-
切割文件介绍
-
切割文件应用场景:有些网站上传文件的时候对文件大小有限制。
例如:假设有一个网站它允许上传的文件单个大小比如2M。这时如果有一个5M的文件需要上传。这时我们可以将5M的文件进行切割,这时可切割为2M或者更小的多个子文件,将这些子文件上传。
切割原理:
一般切割方式有两种:
1、限定可以切割子文件个数。
2、限定子文件的大小。

-
切割文件实现
/*
* 切割文件实现
*/
public class CutFile {
public static void main(String[] args) throws IOException {
// 创建一个输入流,用于读取被切割的文件
FileInputStream fis = new FileInputStream("./files/2.jpg");
// 定义字节数组,用于保存读取的字节数据
byte[] buf = new byte[102400]; // 100KB
// 定义变量,记录读取的字节个数
int len = 0;
// 定义临时变量作为 临时子文件的名称
int temp = 1;
while( ( len = fis.read(buf) ) != -1 ){
// 在循环中创建输出流对象,用于将本次循环读取的100KB的字节数据写到一个子文件中
FileOutputStream fos = new FileOutputStream("./parts/"+temp+".jpg");
temp++;
// 将100KB的数据写到文件中
fos.write(buf, 0, len);
// 写完之后就需要关闭输出流
fos.close();
}
// 在循环结束之后,就表示整个原始文件被切割完成
fis.close();
}
}
-
合并文件介绍
合并文件:将多个碎片文件的数据合并到一个文件中。
思路:
多个碎片文件就需要多个输入流,合并的过程是先用一个输入流读取第一个碎片文件中的字节数据,读取到的数据使用输出流写到文件中,然后接着使用第二个输入流读取第二个碎片文件中的数据,还是使用同一个输出流继续写出。以此类推。最后就可以将所有的碎片文件中的数据合并到同一个文件中。
-
合并文件实现
/*
* 演示合并文件
*/
public class MergeFile {
public static void main(String[] args) throws IOException {
// 定义输出流,用于将读取到的不同文件中的数据写到同一个文件中
FileOutputStream fos = new FileOutputStream("./files/3.jpg");
// 使用for循环提供碎片文件的名称
for( int i = 1 ; i <= 5 ; i++ ){
// 定义输入流,读取碎片文件的数据
FileInputStream fis = new FileInputStream("./parts/"+i+".jpg");
// 使用输入流的模版代码读数据
byte[] buf = new byte[1024];
int len = 0;
while( ( len = fis.read(buf) ) != -1 ){
// 使用统一的输出流将数据写到文件中
fos.write(buf, 0, len);
}
// 上面的while循环结束,就意味着某个碎片文件中的数据读写结束
fis.close();
}
// 外层for循环结束,所有碎片文件全部合并完成
fos.close();
}
}
-
available()

/*
* 演示输入流中的available()方法
* 它的功能:
* 如果在刚刚创建输入流直接调用available方法,那么得到的就是文件的大小。
* 如果调用一个次read方法,那么available获取到的是就是文件中剩余还没有被读取的字节个数
*/
public class AvailableDemo {
public static void main(String[] args) throws IOException {
// 创建输入流
FileInputStream fis = new FileInputStream("e:/11.txt");
System.out.println(fis.available());
fis.read();
System.out.println(fis.available());
fis.read();
fis.read();
fis.read();
System.out.println(fis.available());
// 关流
fis.close();
// 演示File类中的length方法,这个方法仅仅可以获取到文件的大小,不能获取文件夹下的所有文件大小
File file = new File("e:/api");
System.out.println(file.length());
}
}
面试题:
获取指定文件夹下所有文件的大小。
思路:可以使用递归的方式获取到这个文件下的所有文件和文件夹,调用File类中的length方法得到每个文件的大小,如果文件夹,继续递归。在每个得到文件的大小的时候,将和值全部累加起来。
-
Apache的工具类
-
Apache介绍
-

-
复制和目录介绍
apache的IO工具包下载:
http://commons.apache.org/proper/commons-io/download_io.cgi

下载:

解压:

解压后:

api:

用法:
项目中引入其他非sun(oracle)公司的jar包,这时需要在项目下创建一个lib的文件夹,将需要的jar包拷贝到这个文件夹下。
需要将导入的jar添加到当前项目的路径中:右击

/*
* 在项目中引入导入的第三方的api
*/
public class Test {
public static void main(String[] args) throws IOException {
// 创建原始文件对象
File srcFile = new File("e:/1.exe");
// 创建目标文件对象
File destFile = new File("c:/1.exe");
long s = System.currentTimeMillis();
// 演示复制文件
FileUtils.copyFile(srcFile, destFile);
long e = System.currentTimeMillis();
System.out.println("所需时间:"+(e-s));
// 创建原始文件夹对象
File srcDir = new File("d:/test");
// 创建目标文件夹对象
File destDir = new File("e:/test");
// 复制目录
FileUtils.copyDirectory(srcDir, destDir);
}
}
-
字符流
-
字符流介绍
-
我们使用IO流读写数据的时候,有时会出现部分的字节合并在一起,它们表示的是应字符数据。
/*
* 演示使用字节流读取汉字
*/
public class Demo {
public static void main(String[] args) throws IOException {
// 创建文件字节输入流
FileInputStream fis = new FileInputStream("e:/11.txt");
System.out.println(fis.read());
System.out.println(fis.read());
System.out.println(fis.read());
System.out.println(fis.read());
System.out.println(fis.read());
System.out.println(fis.read());
fis.close();
}
}
文件中的数据:
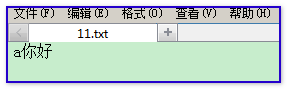
读取的结果:
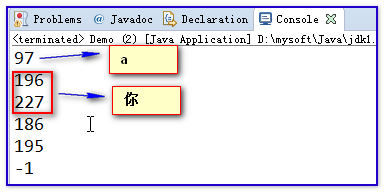
我们使用字节流读取文本文件中的字符内容的时候,是按照文件中的一个一个字节在读取数据。而拿到读取到的每个字节数据并不知道这些数字背后对应的字符是什么?
相当于我们如果使用字节流操作某些字符数据,就可能导致操作的数据不利于程序对这些结果的处理。这时Java又给出另外一组IO流:
字符流:它们专门来读写字符数据。
数据在任何的存储设备上,肯定是二进制形式保存,那么sun公司给出的字符流底层肯定还是在读取这些二进制数据,只是它们内部会将这些二进制给我们转成对应的字符内容。
其实字符流它的本质依然是在操作字节数据,只是字符流在内部会自动的将字节转成字符,最后使用字符流的程序得到是字符而不是字节。
字符流 = 字节流 + 转换的编码表。
-
编码表介绍
计算机是老美他们发明的。而计算机的底层是以二进制的形式保存数据。
老美他们就想办法需要将自己的文字(英文字母、数字、标点符号等)输入到计算机中,可以让计算机处理生活中的文字。
于是 老美他们发明了一个表格:表格中有生活中的文字,还有数字,以及所有的符号,将这些所有的数据与每个数字进行一一对应,然后将数字转成二进制,最后将二进制保存在计算机中。
表格:
生活中的文字 十进制值 二进制值
0 49 0011 0001
1 50 0011 0010
A 65 0100 0001
B 66 0100 0010
a 97 0110 0001
b 98 0110 0010
上面的这个表格它就是全球通用的ASCII(国际信息交易码)编码表。
编码表:将生活中的文字与计算机可以识别的文字进行一一对应的数字的编号(编码)。
ASCII 编码表:它规定所有的字符全部使用一个字节表示,并且要求这个字节的最高位必须是0开始,
例如: A 0100 0001
欧洲的编码表:
拉丁文编码表: ISO-8859-1 它也规定使用一个字节表示数据,但是最高位可以是零也可以是1,一次这个编码表中有负数表示生活中的数据。
中国的编码表:
GB2312 : 它可以识别大约六千到七千的中国文字。
升级:GBK,它大约识别两万多。目前主流的汉字的编码表。
GB18030 : 它识别就更多了。
上述的编码统一采用的是2个字节表示汉字。
国际计算机协会就站出来指定了一个全球通用的编码表:
unicode:它兼容全球大部分国家的通用的字符。这个编码表它也采用2个字节表示一个字符。JDK目前内置的这个编码表。
JDK中的char类占用2个字节的内存。
升级UTF-8 编码表: 它是目前全球主流的通用的编码表。
UTF-8的特点:
1个字节可以表示的数据,就采用1个字节
2个字节可以表示的数据,就采用2个字节
3个字节可以表示的数据,就采用3个字节
必须记住的编码表名称:
ASCII:任何编码表都兼容
ISO-8859-1 : 拉丁文编码表
可以识别中文的编码表:
GB2312、GBK、unicode、utf-8.
-
字符输出流
-
文件字符输出流
-
字符输入流
-
文件字符输入流
-
字符流读取非字符数据的问题分析
-
转换流
-
转换流介绍
-
-
字节转换字符的输入转流
-
字符转字节的输出转换流
-
转流的使用细节
-
编码解码乱码
-
编码
-
-
解码
-
乱码
-
编码解码相关的类
-
字符流缓冲区
-
字符缓冲区介绍
-
-
字符缓冲区演示
-
BufferedReader演示
-
-
BufferedWriter演示