本次作业在要求来自:https://edu.cnblogs.com/campus/gzcc/GZCC-16SE2/homework/3319
1.用自己的话阐明Hadoop平台上HDFS和MapReduce的功能、工作原理和工作过程。
1)HDFS
HDFS是分布式文件系统,用来存储海量数据。HDFS中有两类节点:NameNode和DataNode。
NameNode是管理节点,存放文件元数据。也就是存放着文件和数据块的映射表,数据块和数据节点的映射表。也就是说,通过NameNode,我们就可以找到文件存放的地方,找到存放的数据。DataNode是工作节点,用来存放数据块,也就是文件实际存储的地方。
工作原理:客户端向NameNode发起读取元数据的消息,NameNode就会查询它的Block Map,找到对应的数据节点。然后客户端就可以去对应的数据节点中找到数据块,拼接成文件就可以了,这就是读写的流程。
2)MapReduce
MapReduce是并行处理框架,实现任务分解和调度。
工作原理:将一个大任务分解成多个小任务(map),小任务执行完了之后,合并计算结果(reduce)。也就是说,JobTracker拿到job之后,会把job分成很多个maptask和reducetask,交给他们执行。 MapTask、ReduceTask函数的输入、输出都是的形式。HDFS存储的输入数据经过解析后,以键值对的形式,输入到MapReduce()函数中进行处理,输出一系列键值对作为中间结果,在Reduce阶段,对拥有同样Key值的中间数据进行合并形成最后结果。
2.HDFS上运行MapReduce
1)准备文本文件,放在本地/home/hadoop/wc
先准备一个大一点英文文本文件,我这里准备的是一个名为Mrstandfast.txt的文本文件,放在了下载目录下,如下图所示。
使用 mkdir wc 命令新建一个名为wc的文件夹,再使用 mv /home/chen/下载/MrStandfast.txt MrStandfast.txt 命令把MrStandfast.txt文件复制到wc中,如下图所示。

2)编写mapper函数和reducer函数,在本地运行测试通过
首先,我们可以先编写 mapper函数和reducer函数,使用 gedit mapper.py 命令建立mapper.py文件,在其中插入所要执行的语句,并保存关闭。同理,reducer.py也是这样。
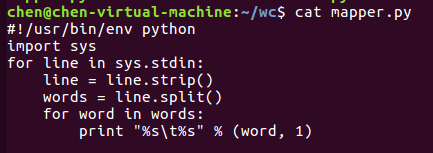
mapper.py
#!/usr/bin/env python import sys for line in sys.stdin: line = line.strip() words = line.split() for word in words: print "%s %s" % (word, 1)
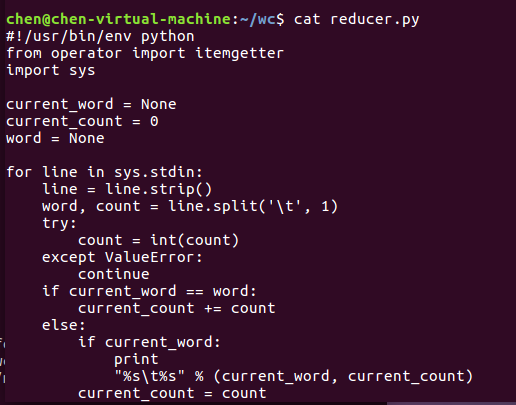
reducer.py
#!/usr/bin/env python from operator import itemgetter import sys current_word = None current_count = 0 word = None # input comes from STDIN for line in sys.stdin: # remove leading and trailing whitespace line = line.strip() # parse the input we got from mapper.py word, count = line.split(' ', 1) # convert count (currently a string) to int try: count = int(count) except ValueError: # count was not a number, so silently # ignore/discard this line continue # this IF-switch only works because Hadoop sorts map output # by key (here: word) before it is passed to the reducer if current_word == word: current_count += count else: if current_word: # write result to STDOUT print '%s %s' % (current_word, current_count) current_count = count current_word = word # do not forget to output the last word if needed! if current_word == word: print '%s %s' % (current_word, current_count)
完成上述步骤后,可以使用 cat mapper.py 命令和 cat reducer.py 命令来查看,如下图所示。
分别使用 chmod a+x /home/chen/wc/mapper.py 和 chmod a+x /home/chen/wc/reducer.py 命令修改mapper和reducer的权限。
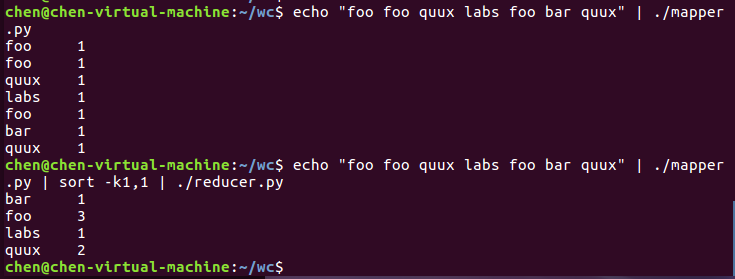
分别使用 echo "foo foo quux labs foo bar quux" | ./mapper 命令和 echo "foo foo quux labs foo bar quux" | ./mapper.py | sort -k1,1 | ./reducer.py 命令在本地测试python代码是否可执行,如下图所示。
3)启动Hadoop:HDFS, JobTracker, TaskTracker
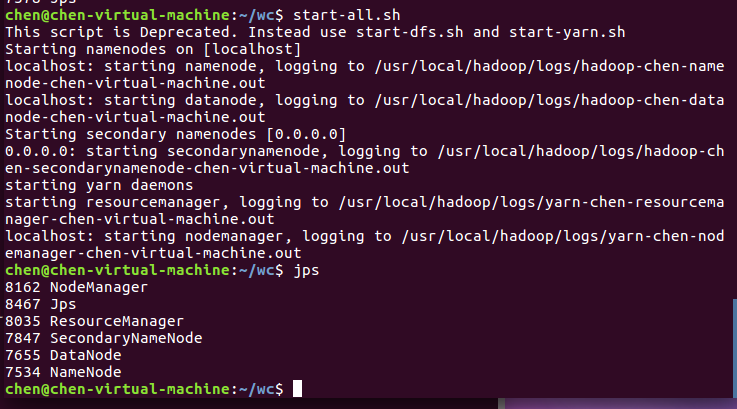
使用 start-all.sh 命令启动hadoop,再使用 jps 命令查看是否启动成功,如下图所示。
4)把文本文件上传到hdfs文件系统上 user/chen/input
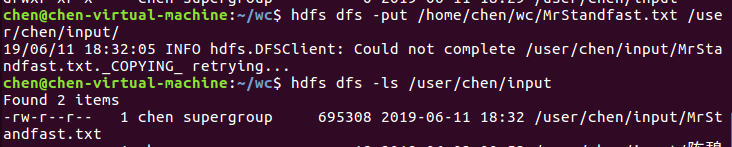
由于我先前做实验时已经创建了 /user/chen/input 这个文件夹了,所以在这里我就直接将本地文件上传即可,使用 hdfs dfs -put /home/chen/wc/MrStandfast.txt /user/chen/input/ 命令把本地的MrStandfast.txt上传至hdfs文件系统上 user/chen/input上,再使用 hdfs dfs -ls /user/chen/input/ 命令来查看文件,如下图所示。
注意:如果先前还没有创建文件夹的,可以使用 hdfs dfs -mkdir -p /user/chen/input 命令来创建文件夹,详见https://www.cnblogs.com/bhuan/p/10964927.html
5)streaming的jar文件的路径写入环境变量,让环境变量生效
使用 vim ~/.bashrc 命令将streaming的jar文件的路径写入~/.bashrc中,并使用 source ~/.bashrc 让环境变量生效,如下图所示。

streaming的jar文件的路径:
export STREAM=$HADOOP_HOME/share/hadoop/tools/lib/hadoop-streaming-*.jar
6)建立一个shell脚本文件:streaming接口运行的脚本,名称为run.sh
使用 vim run.sh 命令或者 gedit run.sh 命令添加streaming接口运行的脚本,再使用 source run.sh 命令使其生效,如下图所示。
run.sh文件内容
hadoop jar $STREAM -file /home/chen/wc/mapper.py -mapper /home/chen/wc/mapper.py -file /home/chen/wc/reducer.py -reducer /home/chen/wc/reducer.py -input /user/chen/input/*.txt -output /user/chen/wcountput
7)source run.sh来执行mapreduce
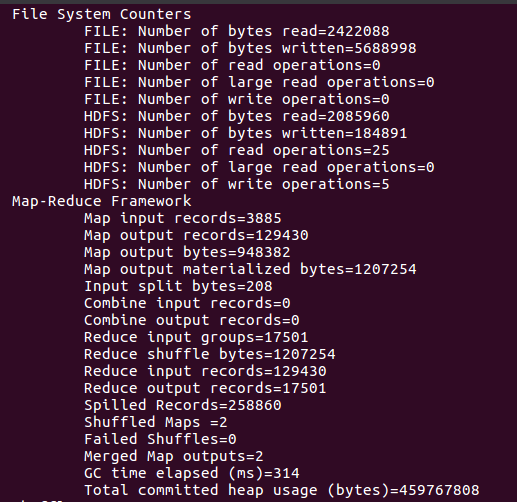
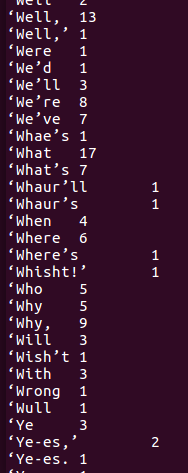
8)查看运行结果
使用 hdfs dfs -cat /user/chen/wcountput/* 命令来查看运行结果,如下图所示。