一、字节、三元运算、进制
1、字节
首先要说明得是,python2 默认是 ASCII,python 3默认是 unicode。Python 3最重要的新特性就是对文本和二进制数据作了更为清晰的区分。文本总是Unicode,由str类型表示,二进制数据则由bytes类型表示。但是在Python2中文本和二进制数据没有做清晰的区分。
1个中文字符 = 2个字节
1个英文字符(string) = 1个字节
1个字节(bytes) = 8个bite
网络实际传输过程中用的 bit, 1000bit/s,1000/8 为实际传过来字节数,在python中的socket网络传输中,用的是字节,而不是字符。
字符串可以编码(encode)成字节包,字节包也可以解码(decode)成字符串。
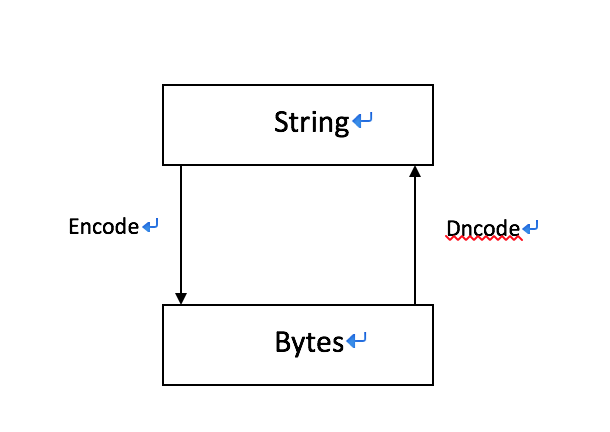
Python3中编码和解码,默认字符编码是utf-8,如果想在编码或者解码中起其他字符编码,则换成其他编码。但是在Python2中,默认字符是系统编码,需要自己手动输入字符编码。
>>> a = "我叫便便"
>>> a.encode('utf-8')
b'xe6x88x91xe5x8fxabxe4xbexbfxe4xbexbf'
>>> a.encode('utf-8').decode('utf-8')
'我叫便便'
2、三元运算
result = 值1 if 条件 else 值2
如果条件为真:result = 值1
如果条件为假:result = 值2
a,b,c = 1,2,5
d = a if a > b else c
a > b 为True的话 d = a
a > b 为Falsec的话 d = c
注:1、条件语句的值,都是布尔类型的值,如:if 条件, while 条件等;
2、python 中没有 case
3、进制
二进制: 0 1
八进制: 0~7 000 001 010 011 100 101 110 111 3位
十进制:0~9 0000 0001 0010 0011 0100 0101 0110 0111 1000 1001
十六进制: 0~F 0000 0001 0010 0011 0100 0101 0110 0111 1000 1001 1010 1011 1100 1101 1110 1111
进制用在IP地址中:IP地址:255.255.255.255 11111111.11111111.11111111.11111111 8位
IPv4地址分为A,B,C,D,E类:
A类:1.0.0.0~126.255.255.255,默认子网掩码/8,即255.0.0.0 (其中127.0.0.0~127.255.255.255为环回地址,用于本地环回测试等用途;
B类:128.0.0.0~191.255.255.255,默认子网掩码/16,即255.255.0.0;
C类:192.0.0.0~223.255.255.255,默认子网掩码/24,即255.255.255.0;
D类:224.0.0.0~239.255.255.255,一般于用组播
E类:240.0.0.0~255.255.255.255(其中255.255.255.255为全网广播地址,E类地址一般用于研究用途。
二、列表
1、列表特点
列表是Python最常用的数据类型之一,通过列表可以对数据实现最方便的存储、修改等操作。
不管列表中的元素是简单的数据类型还是复杂数据类型,都可以增加,修改,删除,查询等操作。
2、定义列表
列表在python中属于复杂数据类型(列表、元祖、字典),简单数据类型指:字符串、数字、布尔值.....
names = list()
names = [] #定义空列表
names = ['a','b','c'] #定义非空列表
3、列表的属性
type() : 查看是属于哪个类的,属于哪个数据类型
>>> name=['a','b','c']
>>> type(name)
<class 'list'>
id() : 查看变量的内存地址
>>> id(name)
4536524616
dir() : 查看对象的属性和方法
>>> dir(name) ['__add__', '__class__', '__contains__', '__delattr__', '__delitem__', '__dir__', '__doc__', '__eq__',
'__format__', '__ge__', '__getattribute__', '__getitem__', '__gt__', '__hash__', '__iadd__', '__imul__',
'__init__', '__init_subclass__', '__iter__', '__le__', '__len__', '__lt__', '__mul__', '__ne__', '__new__',
'__reduce__', '__reduce_ex__', '__repr__', '__reversed__', '__rmul__', '__setattr__', '__setitem__', '__sizeof__',
'__str__', '__subclasshook__', 'append', 'clear', 'copy', 'count', 'extend', 'index', 'insert', 'pop', 'remove', 'reverse', 'sort']
name = ['a','b','c']
列表的取值:是从第0个元素开始取值 names[0]、names[1].....
如果取值>= len(names) 就会报错。
>>> name[3]
Traceback (most recent call last):
File "<pyshell#8>", line 1, in <module>
name[3]
IndexError: list index out of range
注:列表元素支持的数据类型:
-
支持简单的数据类型: 字符串、数字、布尔值、日期等等
-
支持复杂的数据类型: 列表、元祖、字典
3、切片
列表、元祖、字符串都支持切片。
>>> names[1:]
['b', 'c', 'd', 'a']
>>> names[1:-1]
['b', 'c', 'd']
>>> names[1:4]
['b', 'c', 'd']
>>> names[-1]
'a'
>>> names[-4:-1]
['b', 'c', 'd']
>>> name = names[-4:-1]
>>> name
['b', 'c', 'd']
>>> name.append('e')
>>> name
['b', 'c', 'd', 'e']
切片小结:
-
序列始终都是从左向右切片的,不能是从右向左
-
列表切片时,起始位的元素是包括的,结束位的元素是不包括(又叫顾头不顾尾),最后一个位置表示步长(names[开始位:结束位:步长])
-
如果从0位置取值,0可以省略
-
想取最后一个值时,结束位不能是-1,因为结束位的元素不包括,所以只能留空
4、列表属性和方法
(1)append(element) 追加
>>> name.append('d')
>>> name
['a', 'b', 'c', 'd']
(2)clear() 清除列表中的所有元素
>>> name.clear()
>>> name
[]
(3)count(element) 统计某个元素在列表中出现的次数
>>> name.count('a')
1
>>> name.append('a')
>>> name.count('a')
2
# 统计某个切片中元素个数
>>> name[1:].count('a')
1
(4)extend(list) 把两个列表 整合成一个列表
>>> age = [19,20,21,22]
>>> name.extend(age)
>>> name
['a', 'b', 'c', 'd', 'a', 19, 20, 21, 22]
(5)index(element) 查看某个元素的第一个值的下标值
>>> name.index('a')
0
>>> name[1:].index('a')
3
(6)insert(index,element) 在某个位置上插入一个元素
>>> name.insert(1,'bianbian')
>>> name
['a', 'bianbian', 'b', 'c', 'd', 'a', 19, 20, 21, 22]
(7) pop 默认删除最后一个元素,并且把最后一个元素赋值出来
>>> name.pop()
22
>>> name
['a', 'bianbian', 'b', 'c', 'd', 'a', 19, 20, 21]
>>> a = name.pop()
>>> name
['a', 'bianbian', 'b', 'c', 'd', 'a', 19, 20]
>>> a
21
#删除某个下表下的元素
>>> b = name.pop(1)
>>> name
['a', 'b', 'c', 'd', 'a', 19, 20]
>>> b
'bianbian'
(8) remove(element) 删除某个元素,但是不会把值赋值出来
>>> name
['a', 'b', 'c', 'd', 'a', 19, 20]
>>> name.remove('a')
>>> name
['b', 'c', 'd', 'a', 19, 20]
>>> name.remove('a')
>>> name
['b', 'c', 'd', 19, 20]
(9) reverse() 反转列表中的元素
>>> name
['b', 'c', 'd', 19, 20]
>>> name.reverse()
>>> name
[20, 19, 'd', 'c', 'b']
(10) sort() 排序
>>> name
['b', 'a', 'm', 'd']
>>> name.sort()
>>> name
['a', 'b', 'd', 'm']
(11) del 既可以删除元素、也可以删除 内存对象
>>> name = ['a','b','c','d']
>>> id(name)
2754836098312
>>> del name[0]
>>> id(name)
2754836098312
>>> del name
三、元组
元组跟列表差不多,也是存一组数,只不是它一旦创建,便不能再修改,所以又叫只读列表。
用途:一般情况下用于自己写的程序能存下数据,但是又希望这些数据不会被改变,比如:数据库连接信息等。
1、元祖特点
-
根本特点:元素的内存的地址,不可以被修改
-
简单的数据类型:可以查看、统计
-
复杂数据类型:列表和字典
2、定义元祖
#定义空元祖
names = ()
names = tuple()
#定义一个非空元祖
names = ('a','b','c','d')
3、访问元祖中的元素
>>> name = ('a','b','c','d')
>>> name[0]
'a'
>>> name[1]
'b'
>>> name[-1]
'd'
3、切片
切片参考列表切片。
>>> name[1:]
('b', 'c', 'd')
4、方法
-
count()统计元组中一个元素出现的次数
>>> names = ('a','b','c','d','a','b','a')
>>> names.count('a')
3
-
index()
index() 确认元组中一个元素出现第一次的下标值。
>>> names.index('a')
0
5、元素类型为复杂数据类型
>>> name = ([1,2,3,4],'a','b')
>>> name[0].append(5)
>>> name
([1, 2, 3, 4, 5], 'a', 'b')
>>> id(name[0])
2754836098312
>>> name[0].append(6)
>>> name
([1, 2, 3, 4, 5, 6], 'a', 'b')
>>> id(name[0])
2754836098312
可以看出元组的元素类型为复杂数据类型,元组一样可以做追加、统计等操作,且元组的内存地址不变。
6、enumenrate()用法
enumenrate()是Python自带的函数,主要用于列表或者元组,功能:是在for循环时,获取列表或者元组的下标值和元素
-
下标和元素以元组形式输出
>>> name_list = [('a',1),('b',2)]
>>> for index in enumerate(name_list):
... print(index)
#输出结果,获取到的是以元组形式输出,每个元组第一个值表示name_list下标值,第二个值表示name_list的元素
(0, ('a', 1))
(1, ('b', 2))
-
下标值和元素分开输出
>>> name_list = [('a',1),('b',2)]
>>> for index,name in enumerate(name_list):
... print(index,name)
...
#第一个值name_list的下标值,第二个是name_list的元素
0 ('a', 1)
1 ('b', 2)
7、isdigit()用法
判断输出的数值是否是数字类型的变量。
age=input("age:")
if age.isdigit():
age = int(age)
print('your age is:{0}',format(age))
else:
print('input is not digit!')