这里感谢百度文库,百度百科,维基百科,还有算法导论的作者以及他的小伙伴们......
最短路是现实生活中很常见的一个问题,之前练习了很多BFS的题目,BFS可以暴力解决很多最短路的问题,但是他有一定的局限性,该算法只能用于无权重即权重为单位权重的图,那么下面我们会介绍五种用途更广泛的算法......
最短路径的几个变体
单源最短路径问题:我们希望找到从源结点s到其它所有结点的最短路径。
单目的地最短路径问题:找到从每个结点v到目的u的最短路径,如果将图中每条边的方向翻转过来,我们就可以将这个问题转换为单源最短路径问题。
单结点对最短路径问题:该类问题的求解方法和单源最短路径相似,相比之下还有更多的优化算法。
所有结点对的最短路径问题:对于每个结点u和v,找到从结点u到v的最短路径。虽然可以对每个结点运行一次单源最短路径算法,但是我们有更好的算法来解决这类问题,就是后面讲到的Floyd-Warshall算法。
最短路满足最优子结构,最优子结构是运用贪心算法和动态规划的一个重要指标,我们即将了解的Dijkstra算法就是一个贪心算法,Floyd-Warshall算法就是一个动态规划算法,下面我们贴出一段算法导论上面对该定理的证明。

Single Sourse Shortest Path
Bellman-Ford:
一般用于解决单源最短路问题,这里权值可以为负值,给定一个有向图G(V, E)和一个权重函数w : E -> R,该算法返回一个布尔值,以表明是否存在一个从源结点可以到达的权重为负值的环路。如果存在这样的回路,
该算法将告诉我们不存在解决方案,否则该算法会给出最短路径和他们的权重。
该算法通过对边进行松弛操作来逐渐降低从源结点到每个结点v的最短路径的估计值v.d,直到获得最短路径为止。
下面给出算法导论上面的伪代码,由于在进行该算法之前要对每个结点的初始状态进行初始化,所以给出一个初始化操作。
初始化操作就是对于每个结点,将其到所有结点的最短路径初始化为正无穷,将他们的父亲结点初始化为NULL,并将源结点到自己的最短路径初始化为0。
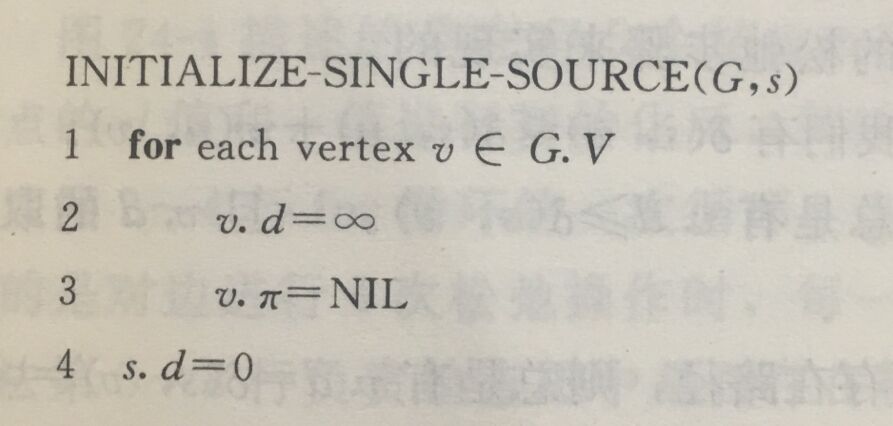
松弛操作就是对于每条边,如果发现当前边终点处对应的最短路径v.d比起点处u.d + w(u, v) 大,则将其更新,由于最短路径问题满足最优子结构,并在最短路径树中将u记录为v的父亲结点。
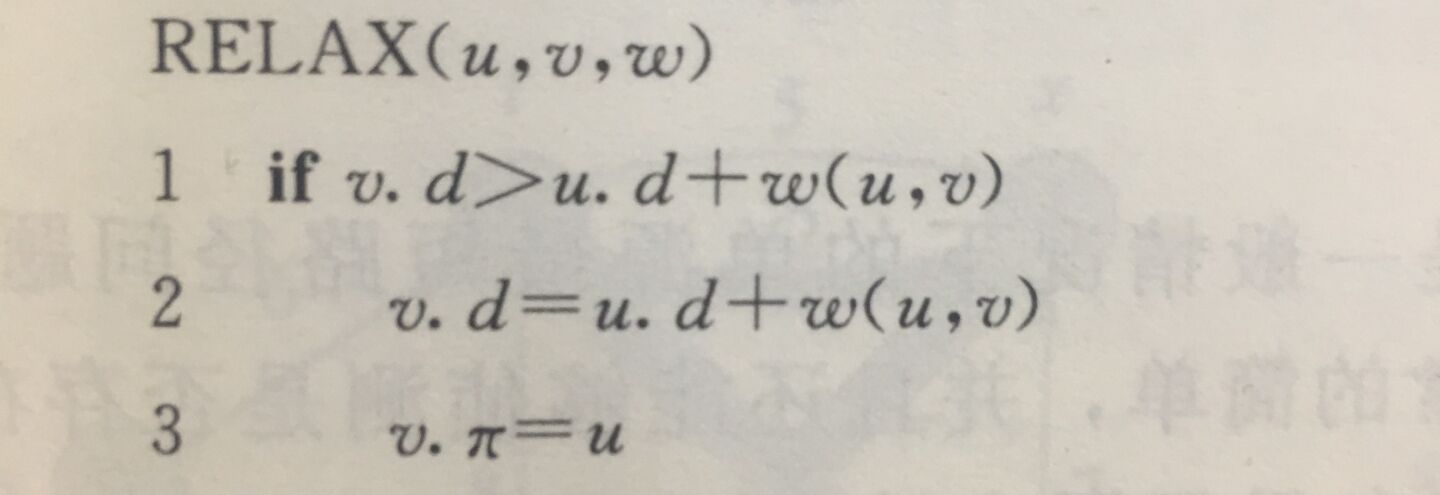
整个Bellman-Ford算法就是先对图中的结点进行初始化,然后对于每个结点v进行松弛操作,松弛时对每个v为起点的边进行松弛操作,之后再检查是否满足最短路问题的最优子结构性质,如果发现违背这个性质,则说明图中存在负权环。

下面我们介绍一种Bellman-Ford算法的优化算法SPFA算法......
SPFA:
SPFA算法全称为Shortest Path Fast Algorithm,在1994年由西南交通大学段凡丁提出,与Bellman-Ford算法一样,用于求解含负权的最短路问题以及判断是否存在负权环。在不含负权环的题情况下优先选择堆优化的Dijkstra算法求最短路径,这就避免SPFA出现最坏的情况。SPFA算法的基本思路与Bellman-Ford算法相同,即每个节点都被用作用于松弛其相邻节点的备选节点。相较于Bellman-Ford算法,SPFA算法的提升在于它并不盲目尝试所有节点,而是维护一个备选节点队列,并且仅有节点被松弛后才会放入队列中。整个流程不断重复直至没有节点可以被松弛。
下面我们给出维基上SPFA算法的伪代码:
// w(u,v)是边(u,v)}的权。 procedure Shortest-Path-Faster-Algorithm(G, s) 1 for each vertex v ≠ s in V(G) 2 d(v) := ∞ 3 d(s) := 0 4 offer s into Q 5 while Q is not empty 6 u := poll Q 7 for each edge (u, v) in E(G) 8 if d(u) + w(u, v) < d(v) then 9 d(v) := d(u) + w(u, v) 10 if v is not in Q then 11 offer v into Q
SPFA算法的性能很大程度上取决于用于松弛其他节点的备选节点的顺序。事实上,如果Q是一个优先队列,则这个算法将极其类似于Dijkstra算法。然而尽管这一算法中并没有用到优先队列,仍有两种可用的技巧可以用来提升队列的质量,并且借此能够提高平均性能(但仍无法提高最坏情况下的性能)。两种技巧通过重新调整Q中元素的顺序从而使得更靠近源点的节点能够被更早地处理。因此一旦实现了这两种技巧,Q将不再是一个先进先出队列,而更像一个链表或双端队列。
下面我们说一下两种优化的思路以及维基上提供的伪代码:
Small Lable First :他的意思是距离小者优先,也就是我们有入队元素时,我们判断队尾元素的权值是否小于队头元素权值,如果满足则将队尾元素剔除并将插到队首。
下面我们给出维基百科上的伪代码,把这一段代码加到上述SPFA代码的第11行之后即可:
1 procedure Small-Label-First(G, Q) 2 if d(back(Q)) < d(front(Q)) then 3 u := pop back of Q 4 push u into front of Q
Large Lable Last:这种优化思路是距离大者置后,也就是我们每次都会计算出当前队列中元素的平均值,当发现正在入队的元素的权值大于平均权值时就将它从队首剔除并插入到队尾。
下面我们给出维基百科上的伪代码,把这一段代码加到上述SPFA代码的第11行之后即可:
1 procedure Large-Label-Last(G, Q) 2 x := average of d(v) for all v in Q 3 while d(front(Q)) > x 4 u := pop front of Q 5 push u to back of Q
上述算法即是单源最短路含负权问题的一般解法,下面我们描述一种对于有向无环图上的最短路问题的解法,该解法内求解单源最短路问题的时间复杂度为O(V + E)。
DAG上的最短路径问题:
在有向无环图中,即使某个边的权重为负值,如果图中不存在起点s可到达的权重为负值的环,那么其最短路径都是存在的。
我们的算法首先对有向无环图进行拓扑排序,以便确定结点之间的一个线性次序。如果图中包含从u到v的一条最短路,那么在有向无环图的拓扑序中,u结点一定位于v结点的前面。因此我们只需要按照拓扑序 对结点进行一遍处理即可。
每次对一个结点进行处理时,我们对从该结点出发的所有边进行松弛操作。
松弛操作和初始化操作与Bellman-Ford算法中的伪代码完全一样,下面给出算法导论上面关于拓扑排序和DAG-SHORTEST-PATHs的伪代码:
算法导论中的拓扑排序依靠对于每个边记录DFS完成顺序的结果进行的,所以我们对该DFS和DFS形成的拓扑序进行讲解。
DFS:
对于每个结点,用白色表示它还没有访问过,用灰色表示正在访问,用黑色表示访问完毕,那么对于任意一个图,我们首先对图中的结点进行初始化,将所有结点的父亲结点初始化为NULL,将所有结点的颜色都初始化为白色表示未
访问,接着顺序遍历每个结点,如果结点没有被访问果我们就访问该结点,访问每个结点时,我们设置一个全局变量的计时器存储每个结点被访问完毕的时间,我们对该结点的其它邻接结点进行访问,如果邻接结点为白色则对其进行相同
的访问,并将它的父亲标记为当前结点,访问完一个结点的所有邻接结点时我们将其状态变为黑色,并记录此时的访问完成时间用于拓扑排序。

如何求出拓扑序呢,首先利用DFS计算出每个结点最后一次访问的时间,对于图中的每个结点,访问完毕后直接将其结点的编号加入到链表的最前端,最后返回头结点。那么要如何证明一个DFS对于一个结点访问完毕的顺序就是逆拓扑序呢?
首先我们知道,对于一个图G,如果他是有向无环图,那么图中一定存在出度为0的结点,这个出度为零的结点必定是最后访问的。那么在DFS访问的过程中,如果一个结点的所有子节点都被访问完毕之后,其出度即为零,即DFS对结点的
访问完毕顺序满足逆拓扑序。

那么要如何实现DAG-SHORTEST-PATHS呢,我们先将所有结点拓扑排序,接着对结点的信息状态进行初始化,接着按照拓扑序对每个结点的邻接结点进行松弛操作,即可完成。

Dijkstra:
Dijkstra算法解决的是带权重的有向图上单源最短路问题,该算法要求所有边的权重都为非负值。如果方式适当,Dijkstra算法的运行时间要优于SPFA算法的运行时间。
Dijkstra算法会维护一组关键的信息,用于下来的运算,从源结点s到该集合中每个结点的最短路径已经被找到,算法重复从V-S中选择最短路径估计最小的结点u,将u加入到集合S中,然后对所有从u出发的边进行松弛操作。
该算法之所以是正确的是因为每次选择结点u加入S中时,有u.d = shortest-paths。那么要如何证明在结点u加入集合s时有上述性质呢?......算法导论上面花了较长的篇幅进行证明,这里不再进行赘述。
这里是用最小优先队列Q来保存结点集合。首先我们对每个结点进行相同于Bellman-Ford算法的初始化,接着将集合s初始化为一个空集,算法第11行将所有结点放入该队列中,对于该队列中的所有结点,我们每次访问其中
权值最小的那个结点u,并将其加入S中,接着对其结点进行松弛,松弛操作与Bellman-Ford算法相同。
下面给出维基百科上Dijkstra算法关于优先队列优化的伪代码:
1 function Dijkstra(Graph, source): 2 dist[source] ← 0 // Initialization 3 4 create vertex set Q 5 6 for each vertex v in Graph: 7 if v ≠ source 8 dist[v] ← INFINITY // Unknown distance from source to v 9 prev[v] ← UNDEFINED // Predecessor of v 10 11 Q.add_with_priority(v, dist[v]) 12 13 14 while Q is not empty: // The main loop 15 u ← Q.extract_min() // Remove and return best vertex 16 for each neighbor v of u: // only v that are still in Q 17 alt ← dist[u] + length(u, v) 18 if alt < dist[v] 19 dist[v] ← alt 20 prev[v] ← u 21 Q.decrease_priority(v, alt) 22 23 return dist, prev
上面的代码和算法导论给出的伪代码思路相同,但是实现方式有一定的差距,该算法和算法导论中Dijkstra算法伪代码不同的地方为,该算法第一次只将起始点加入优先队列,然后在每次进行松弛操作的时候将正在松弛的点加入优先队列用于计算,算法导论中伪代码是将所有顶点先加入优先队列,由于刚开始时只有源点s的权值为0,所以该点就是所采用的第一个点,接着循环进行松弛操作时改变相应的值,由于优先队列会重新平衡,所以这样也并无大碍,但是建议还是采用上面代码而非一次将所有结点都加入优先队列,因为这会使得该算法变得笨重些许......(堆每次需要调整使自己平衡)。下面给出算法导论中对于Dijkstra算法的伪代码实现。
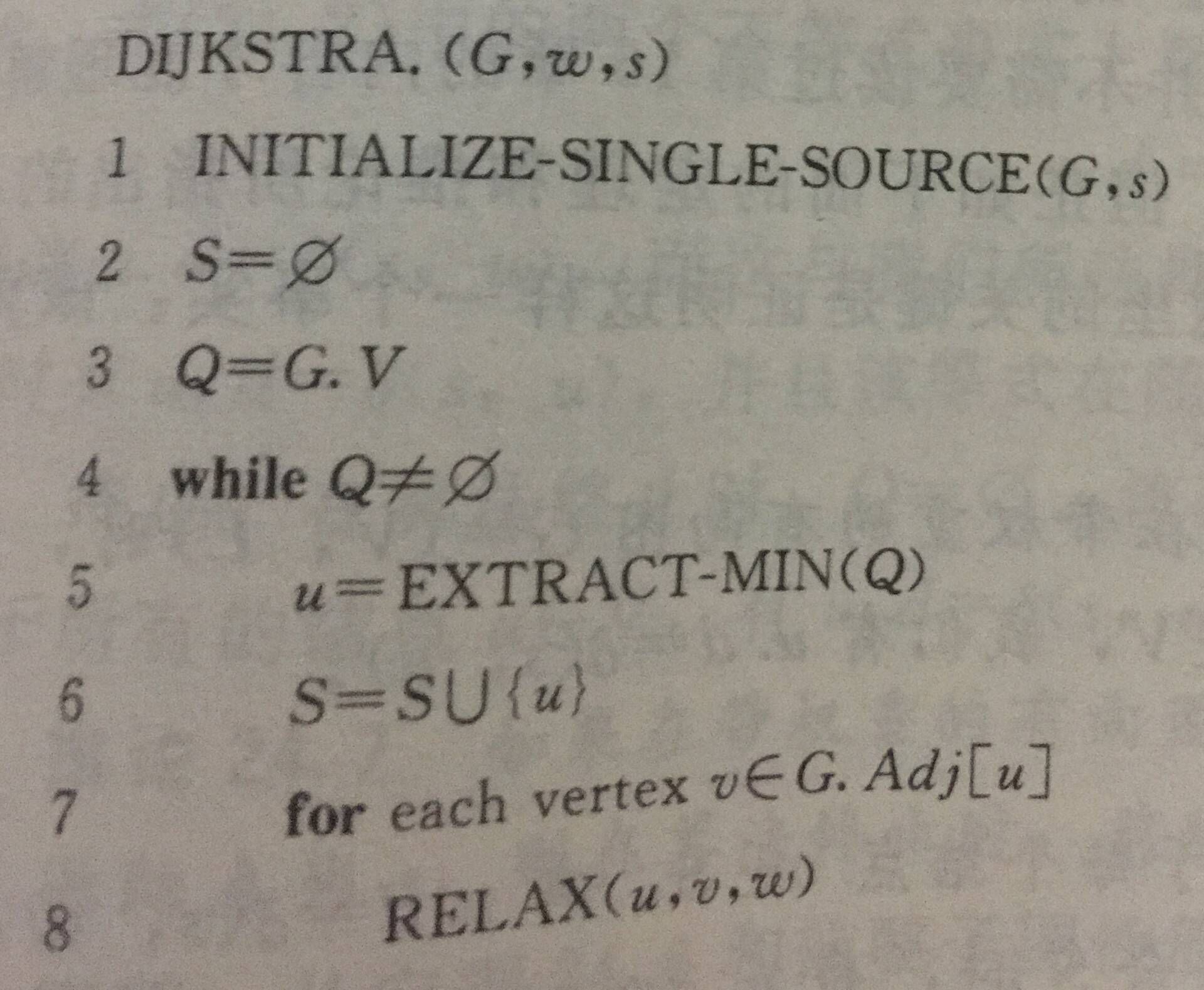
All Pairs Shortest Path
Floyd-Warshall
Floyd-Warshall算法通过逐步改进两个顶点之间的最短路径来实现,直到估计是最优的。
是解决任意两点间的最短路径的一种算法,可以正确处理有向图或负权(但不可存在负权回路)的最短路径问题,同时也被用于计算有向图的传递闭包[2]。
Floyd-Warshall算法的时间复杂度为O(N3),空间复杂度为O(N2)。
原理:Floyd-Warshall算法的原理是动态规划。
设D(i, j, k)为从i到j的只以(1....k)集合中的节点为中间节点的最短路径的长度。
- 若最短路径经过点k,D(i, j, k) = D(i, k, k - 1) + D(k, j, k - 1);
- 若最短路径不经过点k,则D(i, j, k) = D(i, j, k - 1)。
因此,D(i, j, k) = min(, D(i, j, k - 1), D(i, k, k - 1) + D(k, j, k - 1));。
在实际算法中,为了节约空间,可以直接在原来空间上进行迭代,这样空间可降至二维。
下面给出维基百科上面的伪代码描述:
用一个next数组保存路径,意味着以结点 i 为开头的一颗最短路径树。
1 let dist be a |V| * |V| array of minimum distances initialized to 2 let next be a |V| * |V| array of vertex indices initialized to null 3 4 procedure FloydWarshallWithPathReconstruction () 5 for each edge (u,v) 6 dist[u][v] ← w(u,v) // the weight of the edge (u,v) 7 next[u][v] ← v 8 for each vertex v 9 dist[v][v] ← 0 10 next[v][v] ← v 11 for k from 1 to |V| // standard Floyd-Warshall implementation 12 for i from 1 to |V| 13 for j from 1 to |V| 14 if dist[i][j] > dist[i][k] + dist[k][j] then 15 dist[i][j] ← dist[i][k] + dist[k][j] 16 next[i][j] ← next[i][k]
后续还会更新有关Johnson算法得有关内容,并且更新Floyd-Warshall算法得内容。
这几天会有持续的最短路题目更新emmm.....