前言
众所周知,当元数据空间达到一个比较庞大的规模量级的时候,HDFS会遇到一定的扩展性问题。首先HDFS将这些元数据INode信息都load在内存中进行管理,而且还有附属相关的mapping信息,这些庞大的信息被HDFS的NameNode所管理。相应地,NameNode也将会面临更大规模量级的请求处理。从更本质的层面上来说,这是集中中心管理式服务会遇到的一个问题。不同于HDFS的集中纯内存元数据管理方式,本文将介绍另外一种扩展性更强的Ozone分布式元数据管理方式。
Ozone的分布式元数据
首先,这里有个概念,何为分布式元数据?简单地来说,就是系统的元数据分散地存储于各个节点上。那么有人肯定会有疑问了,那我们如何做具体元数据的位置查询呢?难道不是应该有个更加集中式的管理服务来查询这些元数据的关系吗?
这里其实有个问题,如果我们还需要有个集中式的管理服务来管理这些分布式元数据,那这样的设计模式又退化到和集中式管理服务一样的模式了。
在Ozone的每个Datanode中,存储有上面所有block对chunk文件的信息。而另外一半的block在什么节点上这样的信息,是由另外的服务来告诉client的。也就是说,client只要知道它所请求的文件block信息在这个节点就可以了,后面这个block具体对应的chunk物理文件在什么位置,查询Datanode的本地db文件即可。在HDFS中,像这种大量的具体block对文件的映射信息都是集中被NameNode所管理,在Ozone中,这样的集中元数据变成了分布式元数据的模式了。
Ozone Datanode数据的layout
既然Ozone的元数据是分布式地存储于各个Datanode节点之上的,下面我们来具体看看Datanode实际的数据layout,包括用户数据以及元数据,比HDFS Datanode多了元数据目录。
笔者在测试Ozone集群内,创建了一个测试volume,buckt,然后put了一个测试文件。通过查询文件所属的Container的实际位置,就能找到它所在的实际节点位置了。
Datanode的Container目录格式如下所示:
<<dfs.datanode.dir>>/hdds/<>/current/
笔者测试集群的一个实际目录如下:
[hdfs@lyq ~]$ ls -l /tmp/hadoop-hdfs/dfs/data/hdds/762187f8-3d8d-4c2c-8659-9ca66987c829/current/
total 4
drwxr-xr-x 3 hdfs hdfs 4096 Dec 24 07:56 containerDir0
这里的containerDir0是Container按照Container Id做partition的,分partition目录是为了防止一个目录下游过多的文件。然后紧接着partition目录的是Container Id目录。
[hdfs@lyq ~]$ ls -l /tmp/hadoop-hdfs/dfs/data/hdds/762187f8-3d8d-4c2c-8659-9ca66987c829/current/containerDir0/4/
total 8
drwxr-xr-x 2 hdfs hdfs 4096 Dec 24 07:56 chunks
drwxr-xr-x 3 hdfs hdfs 4096 Dec 24 07:56 metadata
以上2个目录中,chunks代表的即Container下的block对应的chunk文件数据,metadata则为container信息文件和Container db文件,后者里面存储着此Container里的block信息元数据。Block元信息存储着其包含的chunk文件信息数据。
[hdfs@lyq ~]$ ls -l /tmp/hadoop-hdfs/dfs/data/hdds/762187f8-3d8d-4c2c-8659-9ca66987c829/current/containerDir0/4/chunks/103363337595977729_chunk_1
-rw-r--r-- 1 hdfs hdfs 12 Dec 24 07:56 /tmp/hadoop-hdfs/dfs/data/hdds/762187f8-3d8d-4c2c-8659-9ca66987c829/current/containerDir0/4/chunks/103363337595977729_chunk_1
[hdfs@lyq ~]$ cat /tmp/hadoop-hdfs/dfs/data/hdds/762187f8-3d8d-4c2c-8659-9ca66987c829/current/containerDir0/4/chunks/103363337595977729_chunk_1
hello world
接着我们来看Container的元数据目录,
[hdfs@lyq ~]$ ls -l /tmp/hadoop-hdfs/dfs/data/hdds/762187f8-3d8d-4c2c-8659-9ca66987c829/current/containerDir0/4/metadata/
total 8
drwxr-xr-x 2 hdfs hdfs 4096 Dec 24 07:56 4-dn-container.db
-rw-r--r-- 1 hdfs hdfs 567 Dec 24 07:56 4.container
container_id.container样式的文件包含了此Container的一些基本信息内容,这个文件会在Datanode创建Container时顺带生成。
[hdfs@lyq ~]$ cat /tmp/hadoop-hdfs/dfs/data/hdds/762187f8-3d8d-4c2c-8659-9ca66987c829/current/containerDir0/4/metadata/4.container
!<KeyValueContainerData>
checksum: fbbb104d6b0f2341cc318f4cf940a76658d1a5e0250bd16d4b4c752a6ea7465c
chunksPath: /tmp/hadoop-hdfs/dfs/data/hdds/762187f8-3d8d-4c2c-8659-9ca66987c829/current/containerDir0/4/chunks
containerDBType: RocksDB
containerID: 4
containerType: KeyValueContainer
layOutVersion: 1
maxSize: 5368709120
metadata: {}
metadataPath: /tmp/hadoop-hdfs/dfs/data/hdds/762187f8-3d8d-4c2c-8659-9ca66987c829/current/containerDir0/4/metadata
originNodeId: c29894ae-e3b2-4dea-b97e-3e5a60243baf
originPipelineId: c2971ae1-61f2-4bf9-aed0-a1fd2fea5964
state: OPEN
这部分信息同样会被load到Datanode的内存中进行管理。另外一个4-dn-container.db目录则是Container的RocksDB文件,保存了此Container所包含的Block元数据信息文件。
Ozone Datanode的数据处理操作
在上述的Datanode Container layout模式下,Datanode是如何进行数据处理的呢?这其中的过程是怎样的呢?
这里假设大家对Ozone已经有一定的背景了解,一个大的背景是client往某个Datanode Container写入block数据。这里无非会涉及到两方面主要操作:
- Container实际数据读写操作,即上面的chunk文件的操作
- Container Metadata的信息操作,更改container db文件或.container文件
再加上Datanode Dispatcher分发类+对应Container Type(目前只支持K-V方式的存储)的Handler处理类,就构成了如下的数据处理过程:
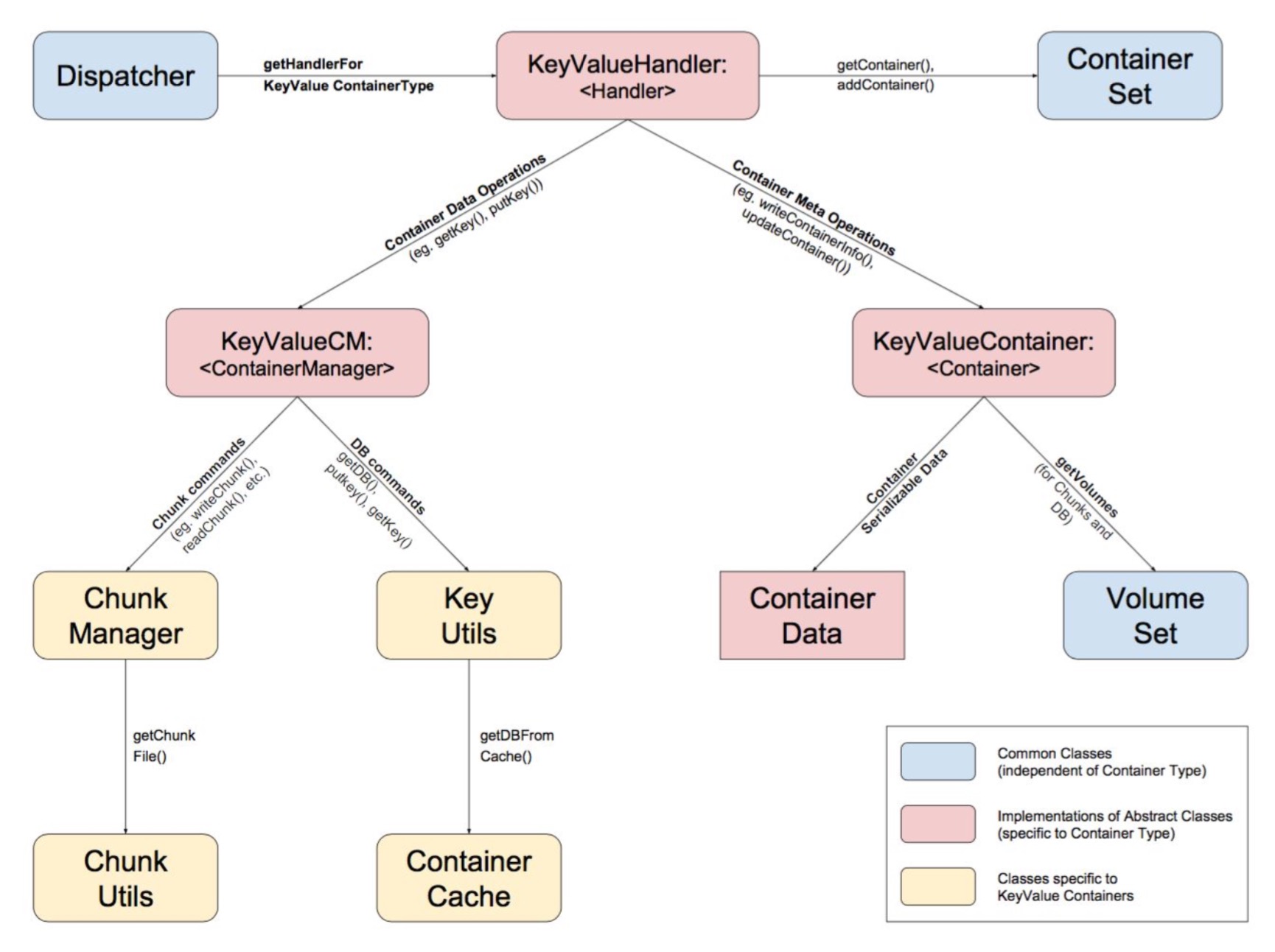
上图中的ChunkManager处理的是数据文件的读写,其实KeyValueHanlder内部还有一个叫做BlockManager的类是控制block metadata的操作。上述KeyUtils更准确地说,应该用BlockManager#BlockUtils所替代。
上述的中心处理逻辑都包含在了KeyValueHanlder类中:
// handle处理操作
public ContainerCommandResponseProto handle(
ContainerCommandRequestProto request, Container container,
DispatcherContext dispatcherContext) {
Type cmdType = request.getCmdType();
KeyValueContainer kvContainer = (KeyValueContainer) container;
switch(cmdType) {
case CreateContainer:
return handleCreateContainer(request, kvContainer);
case ReadContainer:
return handleReadContainer(request, kvContainer);
...
return handleReadChunk(request, kvContainer, dispatcherContext);
case DeleteChunk:
return handleDeleteChunk(request, kvContainer);
case WriteChunk:
return handleWriteChunk(request, kvContainer, dispatcherContext);
case ListChunk:
return handleUnsupportedOp(request);
case CompactChunk:
return handleUnsupportedOp(request);
...
default:
return null;
}
}
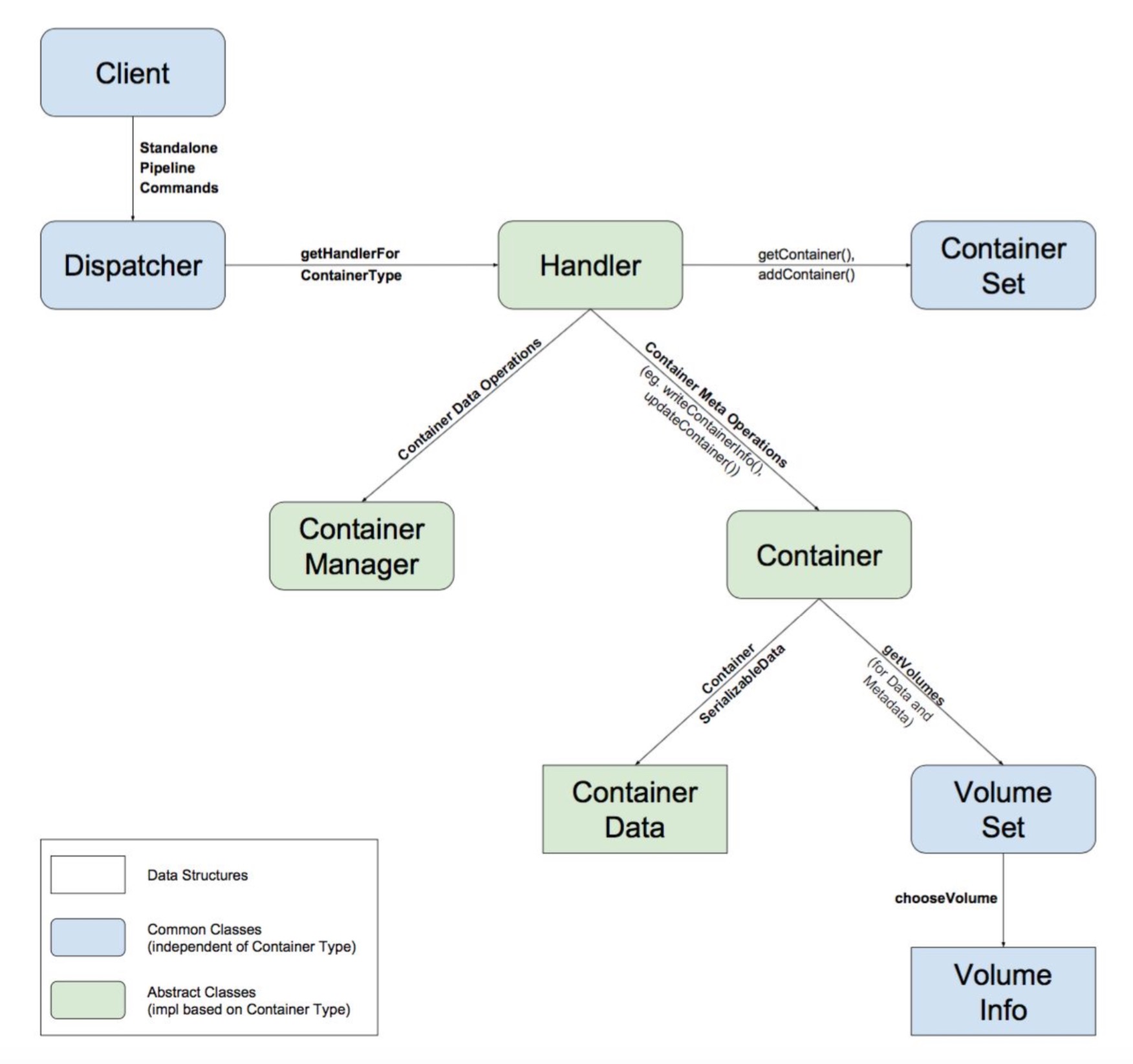
而这里的Dispatcher请求的最开始源头是从外部client发起的,
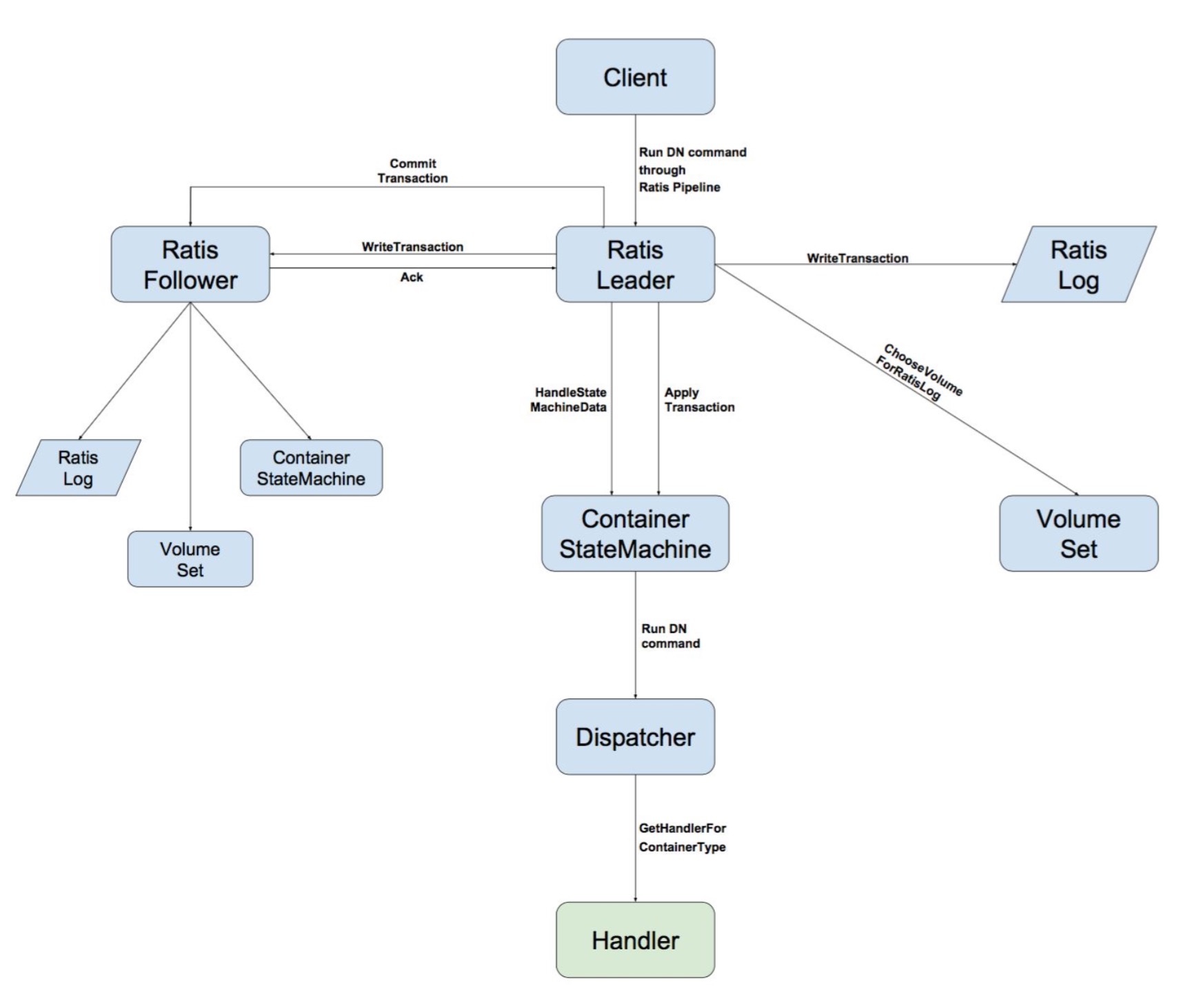
Ozone对于Client到实际Datanode之间的通信,通过Apache Ratis(Raft协议的java实现库)来保证其中的操作一致性,Client到Datanode的中间过程如下图所示:
当然Client在连接目标Datanode之前,还需要与OM进行通信,来得到数据输出流对象,以及目标Block的位置信息,然后再向目标Datanode发起数据读写命令请求。
此部分过程如下所示:
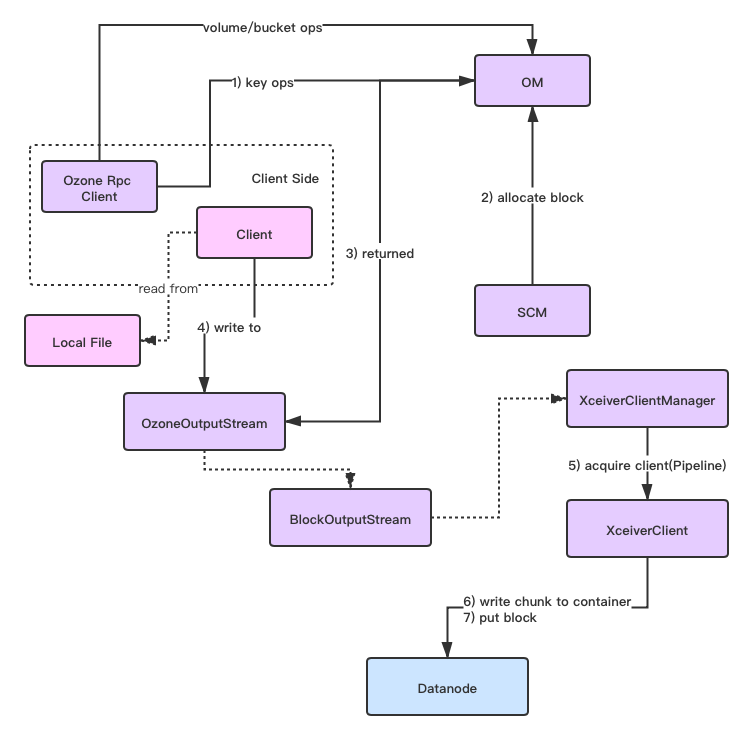
上述过程如下(下图数字过程不匹配图中数字标号):
1)Client向OM执行put key操作
2)OM向SCM申请Container Block
3)OM返回给Client一个Block的输出流对象
4)Client往此输出流中进行数据的写入
5)Block输出流对象内部会调用发送请求命令操作进行实际chunk文件的写入
6)上述chunk文件如若写入成功,则输出流对象内部会继续调用put block操作给Datanode进行container db文件的更新
Ozone Client实际Block的数据写出过程还是有许多细节还是比较精妙的,笔者后续会在另外的文章中来阐述这块内容的。
引用
[1]. https://issues.apache.org/jira/browse/HDDS-48 . ContainerIO - Storage Management