前言
在我们平时的程序处理过程中,在效率上而言,串行处理的效率不如并行处理的效率,从线程层面而言,即多线程效率不如单线程。但是尽管说并行处理效率确实会比较高,但是它在处理拥有数据结果依赖关系的逻辑时,需要额外的同步管控。例如我的输出怎么临时被存放,然后被下游程序收到处理等等。倘若我们设计的并行处理程序能很好地解决,逻辑依赖关系,那么无疑并行处理的方式将会大大提速我们实际系统中的执行效率。本文笔者来聊聊其中一种被称为Pipeline(流水线)模式的并行处理作业模式,相信此并行处理模式在实际工作中还是有所应用场景的。
Pipeline并行处理模式概要
首先一个问题,什么叫做Pipeline并行处理模式呢?Pipeline并行处理模式,首先它具有Pipeline属性,它有一条完整的依赖关系处理流程。比如一道工序总共分3个流程,A,B和C, 并且有严格的先后顺序执行要求。B流程的执行必须依赖A流程的执行结果,同样C流程需要依赖B的。其实这么来看,串行处理模式是天然适用于Pipeline处理模式的。
不过本文我们要讨论的是并行处理Pipeline模式作业。如果按照惯常使用的多线程依赖同步的处理方法,主要有以下两种:
- 将程序中间结果写出到第三方存储介质内,然后并行处理线程与此第三方存储进行数据交互,同步。
- 程序中间结果保存到本地变量内,通过线程安全的做法将中间结果进行赋值输出,灵活一点的,还可以进行同步的控制。
接下来笔者将要讨论的方法是第二种方法。
车厢模拟式的Pipeline并行处理模式
这里我们将用模拟车厢的方式来进行Pipeline work的执行,每个车厢代表一个执行单元,车厢具有Pipeline work的独有特征:
- 车厢具有连接关系,每个车厢有它的前车厢和后车厢。
- 头车厢无前车厢,它的处理无须依赖前车厢执行结果。
- 尾车厢无后车厢,它的处理完毕即意味着总执行过程的结束。
另外在每个车厢内,它还具有以下变量:
- 多执行线程
- 中间结果置换列表
因此,基于车厢模型的Pipeline处理模式如下图所示:
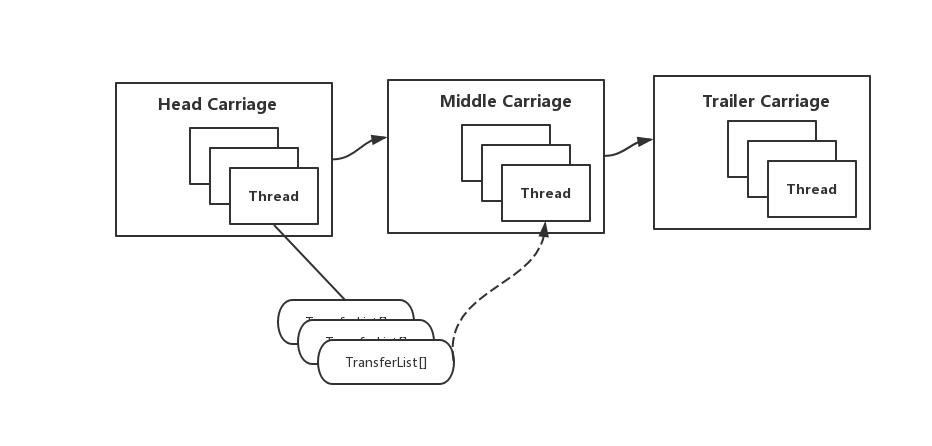
上图中Middle Carriage(中部车厢)可能会有很多节,每个线程都有对应的中间结果输出列表。
Pipeline并行处理模式代码实现
此部分笔者来分享一段Pipeline并行处理模式的多线实现代码,引用自Hadoop社区JIRA的一个patch。
在这个patch代码中,还是沿用了上节车厢的概念,另外它的整个过程可拆分为以下几个步骤:
- Pipeline work的定义以及Pipeline task的构建
- 根据Pipeline task,来构建车厢
- 车厢内部逻辑处理
3.1) 头车厢(起始线程)处理过程
3.2) 中部车(中部线程)厢处理过程
3.3) 尾部车厢(末尾线程)处理过程
针对上述子步骤,我们逐一来阐述。首先是Pipeline work的定义,此work的是每个车厢的线程的具体执行逻辑。
PipelineWork header = new PipelineWork<Object, TestItem>() {
int idx = 0;
@Override
public TestItem doWork(Object obj) throws IOException {
if (idx < items.size()) {
TestItem item = items.get(idx);
item.setVal(item.getVal() * 2);
if (exp && (idx == items.size() - 1)) {
throw ioe;
}
idx++;
LOG.info(Thread.currentThread().getName() +
": Head worker produce item: " + item.getVal());
return item;
} else {
LOG.info("Head worker finsihed produce item.");
return null;
}
}
};
PipelineWork middle = new PipelineWork<TestItem, TestItem>() {
@Override
public TestItem doWork(TestItem item) {
item.setVal(item.getVal() * 2);
LOG.info(Thread.currentThread().getName() +
": Middle worker set value: " + item.getVal());
return item;
}
};
PipelineWork trailer = new PipelineWork<TestItem, Object>() {
@Override
public Object doWork(TestItem item) {
item.setVal(item.getVal() * 2);
LOG.info(Thread.currentThread().getName() +
": Trailer woker set value: " + item.getVal());
return EMPTY;
}
};
然后根据上面的work,构建Pipeline task,
PipelineTask task = new PipelineTask(conf, "pipeline.testcarriage");
task.appendWork(header, "header");
task.appendWork(middle, "middle" + i);
task.appendWork(trailer, "trailer");
task.kickOff();
task.join();
在Pipeline的task的构建过程中,会进行车厢的组织,
/**
* Pipeline work的构建
*/
public void kickOff() {
for (int i = 0; i < pipeLine.size(); i++) {
// 从pipeline中获取当前车厢
Carriage ca = pipeLine.get(i);
if (i == 0) {
// 第一个车厢为头车厢,没有前车厢,标记Header字段
ca.setPrev(null);
ca.setHeader();
}
if (i == pipeLine.size() - 1) {
// 如果是最后一节末尾车厢,则标记Trailer字段
ca.setTrailer();
}
if (i > 0) {
// 中部车厢进行前车厢的引用赋值
ca.setPrev(pipeLine.get(i - 1));
}
// 车厢衔接处理设置完毕,然后进行启动执行
ca.kickOff();
}
}
每节车厢在组织完毕后,就可以开始run起来了。
对于每个车厢,它有如下的定义:
private class Carriage<K, T> {
private PipelineWork<K, T> work;
private ArrayList<T>[] transferList;
private ReentrantLock[] lock;
private Throwable[] exception;
// 每个线程的是否执行完毕的标识
private boolean[] done;
// 执行Carriage任务的线程数
private int numThreads;
private int blockingThreshold, transferThreshold, logThreshold;
// 此车厢依赖的前车厢
private Carriage prev;
private volatile boolean shouldStop = false;
final private List<T> EMPTY_LIST = new ArrayList<T>(0);
// 是否是头车厢
private boolean header = false;
// 是否是末尾车厢
private boolean trailer = false;
// 执行当前车厢的线程组
private Thread[] threads = null;
private String name = null;
...
public Carriage(PipelineWork<K, T> inWork, String caName) {
name = caName;
blockingThreshold = conf.getInt(getBlockingThresholdKey(name), 10000);
transferThreshold = conf.getInt(getTransferThresholdKey(name), 100);
logThreshold = conf.getInt(getLoggingThresholdKey(name), 10000000);
numThreads = conf.getInt(getNumThreadsKey(name), 3);
if (blockingThreshold < 0 || transferThreshold < 0
|| blockingThreshold < transferThreshold || logThreshold < 0
|| numThreads < 0) {
throw new IllegalArgumentException("Illegal argument for PipelineTask "
+ name);
}
work = inWork;
transferList = new ArrayList[numThreads];
for (int i = 0; i < numThreads; i++) {
transferList[i] = null;
}
lock = new ReentrantLock[numThreads];
for (int i = 0; i < numThreads; i++) {
lock[i] = new ReentrantLock();
}
exception = new Throwable[numThreads];
for (int i = 0; i < numThreads; i++) {
exception[i] = null;
}
done = new boolean[numThreads];
for (int i = 0; i < numThreads; i++) {
done[i] = false;
}
}
public void setPrev(Carriage ca) {
prev = ca;
Preconditions.checkState(header == false);
}
public void stopCarriager() {
shouldStop = true;
}
public void setHeader() {
header = true;
Preconditions.checkState(prev == null);
}
public void setTrailer() {
trailer = true;
}
/**
* 获取车厢的本地处理结果.
*/
public List<T> getList() {
int doneThread = 0;
for (int i = 0; i < transferList.length; i++) {
lock[i].lock();
try {
if (exception[i] != null) {
return null;
}
// 如果发现i下标线程的中间结果列表不为空,则进行返回
if (transferList[i] != null) {
ArrayList<T> res = transferList[i];
// 然后置空此下标值为空
transferList[i] = null;
return res;
} else {
// 如果此下标置换列表为空,则判断是否为当前对应的线程已经处理完毕
if (done[i]) {
// 如果是,则进行技术加一
doneThread++;
}
}
} finally {
lock[i].unlock();
}
}
// 如果线程结束数量达到置换结果列表原始长度,则返回空,意为当前车厢数据已经完全处理完毕
if (doneThread == transferList.length) {
return null;
} else {
// 否则,返回空list,意为暂时没有处理数据
return EMPTY_LIST;
}
}
然后就是各个车厢内的并行处理的核心执行逻辑,
/**
* 执行车厢内容的线程类
*/
private class CarriageThread extends Thread {
// 线程标识
private int index;
public CarriageThread(int i) {
index = i;
this.setName("PipelineTask-" + name + "-" + index);
}
@Override
public void run() {
try {
Preconditions.checkState((prev != null) ^ header);
ArrayList<T> localList = null;
if (!trailer) {
localList =
new ArrayList<T>((blockingThreshold > 0) ? blockingThreshold
: 0);
}
LOG.info("Carriage " + name + " thread " + index + " is scheduled");
int itemHandled = 0;
while (!shouldStop) {
if (header) {
/** 1.头车厢的处理过程 **/
// 如果是头车厢,则没有前车厢依赖输入,直接执行
T t = work.doWork(null);
itemHandled++;
if (itemHandled == logThreshold) {
LOG.info("Handled " + itemHandled + " in " + name + " thread "
+ index);
itemHandled = 0;
}
if (!trailer && t != null) {
// 将处理结果加入到当前本地结果列表中
localList.add(t);
} else if (t == null) {
// 如果处理结果为空,意为原始输入数据已经完全处理完毕,头车厢任务宣告全部完成
break;
}
} else {
/** 2.中部车厢/尾车厢的处理过程 **/
// 非头车厢,意为当前为中间车厢或者尾车厢,先取出前车厢的处理结果
List<K> inputList = prev.getList();
if (inputList == null) {
// 如果前车厢的处理结果为空,意为前车厢数据已处理完毕,则当前车厢跳出当前循环
LOG.info("Break out.");
break;
} else if (inputList.isEmpty()) {
// 如果前车厢的处理结果为Empty,意为前车厢还有未处理的数据,不过还未将结果赋值到置换列表内
// 让出当前CPU给其它线程执行
Thread.yield();
continue;
}
for (K k : inputList) {
// 遍历前车厢的数据处理结果,得到新的处理结果
T t = work.doWork(k);
itemHandled++;
if (itemHandled == logThreshold) {
LOG.info("Handled " + itemHandled + " in " + name
+ " thread " + index);
itemHandled = 0;
}
if (!trailer && t != null) {
// 将处理结果加入到当前车厢的本地结果列表内,将作为此车厢下节的依赖输入
// 后续同样是中间置换结果的赋值过程
localList.add(t);
}
}
}
if (trailer) {
// 如果是尾车厢,跳过后续本地输出结果的交换
continue;
}
/** 3.执行线程中间结果交换 **/
// 如果当前本地结果超出阈值设定大小
if (localList.size() >= transferThreshold) {
if (lock[index].tryLock()) {
// 而且之前对应位置交换列表为空,则进行赋值
if (transferList[index] == null) {
transferList[index] = localList;
lock[index].unlock();
// 交换完毕,重新置空本地结果列表
localList =
new ArrayList<T>(
(blockingThreshold > 0) ? blockingThreshold : 0);
} else {
lock[index].unlock();
}
}
}
// 本地结果列表达到阻塞阈值设定大小,阻塞意为当前本地输出的结果必须要赋值到置换列表内
if (blockingThreshold > 0 && localList.size() >= blockingThreshold) {
lock[index].lock();
// 如果当前置换列表数据不为空,意为还没被下游车厢处理,则进行循环等待
while (transferList[index] != null) {
lock[index].unlock();
// 让出CPU给其它线程执行,然后再循环执行判断
Thread.yield();
lock[index].lock();
}
// 置换列表被下游车厢取走,则进行新的本地结果赋值
transferList[index] = localList;
lock[index].unlock();
// 交换完毕,重新置空本地结果列表
localList = new ArrayList<T>(blockingThreshold);
}
}
/** 4.车厢末端中间结果赋值输出 **/
// 循环执行结果后,将最后一批处理得到的本地输出结果进行输出赋值
lock[index].lock();
while (!trailer) {
if (localList.size() > 0) {
// 本地输出结果有值,并且置换列表为空,则进行辅助
if (transferList[index] == null) {
transferList[index] = localList;
break;
} else {
// 不为空,让出当前CPU给其它线程处理,然后再等待下次的循环处理
lock[index].unlock();
Thread.yield();
lock[index].lock();
continue;
}
} else {
break;
}
}
// 本地输入结果处理完毕,标记当前线程处理完毕
done[index] = true;
if (prev != null) {
exception[index] = prev.getException();
}
lock[index].unlock();
} catch (Throwable t) {
// 更新对应下标线程信息的变量
LOG.warn("Exception in pipeline task ", t);
lock[index].lock();
exception[index] = t;
lock[index].unlock();
shouldStop = true;
}
LOG.info("Carriage " + name + " thread " + index + " is done");
}
}
大家可以反复阅读上述的执行逻辑,设计还是比较巧妙的。
以下是其中的测试结果输出:每节车厢内的执行逻辑可以并行地run起来,无须强同步的控制。
2019-09-03 23:25:48,395 INFO util.TestPipelineTask (TestPipelineTask.java:doWork(69)) - PipelineTask-middle0-0: Middle worker set value: 2884
2019-09-03 23:25:48,395 INFO util.TestPipelineTask (TestPipelineTask.java:doWork(69)) - PipelineTask-middle0-0: Middle worker set value: 2888
2019-09-03 23:25:48,392 INFO util.TestPipelineTask (TestPipelineTask.java:doWork(69)) - PipelineTask-middle0-2: Middle worker set value: 1704
2019-09-03 23:25:48,392 INFO util.TestPipelineTask (TestPipelineTask.java:doWork(56)) - PipelineTask-header-0: Head worker produce item: 1976
2019-09-03 23:25:48,392 INFO util.TestPipelineTask (TestPipelineTask.java:doWork(79)) - PipelineTask-trailer-2: Trailer woker set value: 176
2019-09-03 23:25:48,395 INFO util.TestPipelineTask (TestPipelineTask.java:doWork(79)) - PipelineTask-trailer-2: Trailer woker set value: 192
2019-09-03 23:25:48,395 INFO util.TestPipelineTask (TestPipelineTask.java:doWork(79)) - PipelineTask-trailer-2: Trailer woker set value: 208
2019-09-03 23:25:48,395 INFO util.TestPipelineTask (TestPipelineTask.java:doWork(79)) - PipelineTask-trailer-2: Trailer woker set value: 232
2019-09-03 23:25:48,395 INFO util.TestPipelineTask (TestPipelineTask.java:doWork(56)) - PipelineTask-header-0: Head worker produce item: 1992
2019-09-03 23:25:48,395 INFO util.TestPipelineTask (TestPipelineTask.java:doWork(79)) - PipelineTask-trailer-0: Trailer woker set value: 16
2019-09-03 23:25:48,395 INFO util.TestPipelineTask (TestPipelineTask.java:doWork(69)) - PipelineTask-middle0-2: Middle worker set value: 1720
2019-09-03 23:25:48,395 INFO util.TestPipelineTask (TestPipelineTask.java:doWork(69)) - PipelineTask-middle0-0: Middle worker set value: 2892
2019-09-03 23:25:48,395 INFO util.TestPipelineTask (TestPipelineTask.java:doWork(69)) - PipelineTask-middle0-0: Middle worker set value: 2896
引用
[1].https://issues.apache.org/jira/browse/HDFS-13700 . The process of loading image can be done in a pipeline model