前言
在集群规模日益增大的背景下,集群内运行的机器类型可能也会变得越来越多,可能一部分机器磁盘读写性能比较好,又可能说那部分机器网络情况较好,还有的是CPU计算资源比较好的机器.面对这么多机型的节点,我们当然不能”一视同仁”,否则对于这些机器来说,就是一种资源浪费.在Job运行的层面(在YARN层面)而言,已经可以支持通过打NodeLabel标签的形式,让application运行在指定nodeLabel的节点上,以此做到计算资源的充分利用以及任务运行的资源隔离.那么现在问题来了,在数据存储的层面(在HDFS层面)而言,是否也能支持这种NodeLabel的机制呢?本文探讨的主题就是HDFS NodeLabel特性,与YARN NodeLabel有一部分相似点.
HDFS NodeLabel综述
HDFS NodeLabel最早的提出是在HDFS-9411(HDFS NodeLabel support)上,适用的背景正如前言中所描述的.正如HDFS-9411所显示的,此功能特性还尚且处于原型设计阶段,还并未进行实质的开发.但是尽管如此,此功能特性依然是一个很棒的特性,这也是为什么我会专门写一篇文章来介绍它的原因.Ok,扯得有点远了,重新回到正题,在YARN NodeLabel中,打标签的对象是nodemanager,用户通过给application打对应的标签,从而使得application跑在对应nodelabel的nodemanager上.我们可以进行对比和联系,在HDFS NodeLabel中,打标签的对象将会是DataNode和待写入的文件/目录.然后对应nodelabel的文件最后存储到对应的DataNode.看到这里,稍微熟悉HDFS的人可能马上会提出一点意见:这不正是HDFS异构存储的StoragePolicy机制所干的事情吗?不错,在这点上,二者的确有着比较大的相似性,归结下来一句话:
HDFS NodeLabel包含了部分StorageType的功能特点,但是相比后者,它的功能并不仅限于此,它能支持更加复杂的分组.
在后面的设计细节中,大家将会感觉到其中的异同.
HDFS NodeLabel的设计
NodeLabel的类型
在HDFS-9411的最新的设计文档中,将NodeLabel分为了以下2大类型:
- Constraint Label(约束标签):每个约束标签代表着一类的特性,比如高内存,高CPU资源等等.每个DataNode可以拥有多个不同的约束标签.
- Partition Label(分区标签):分区标签的主要作用是将整个集群在逻辑上划分成多个分段,每个DataNode划分到其中一个Partition分段中.
对于第一种标签的使用场景,我们应该比较熟悉了,与HDFS的storageType的使用场景比较类似.这里我们来看看第二种标签的使用场景,比如我们有10台机器,其中node[1-5]被打上了Partition1的标签,而node[6-10]则被划分到了Partition2下.分段标签划分好之后,我们可以规定Partition1下的机器归属HBase使用,而Partition2下的则归属于Hive使用.这样的话,我们其实就做到了服务上的隔离.
NodeLabel要求实现点
以下是一些HDFS NodeLabel需要满足的要求点:
- 每个节点所拥有的NodeLabel数需要有数量的限制,以此减轻NameNode的管理压力.
- 每个NodeLabel需要被Admin管理员创建.
- 可以有不打NodeLabel标签的节点存在.
- 同个NodeLabel可以被打在多个节点上.
- NodeLabel标签需要被持久化,这样当节点或集群重启的时候不会丢失NodeLabel信息.
- NodeLabel需要有ACL的控制.
- 用户通过指定NodeLabel相关的表达式来确定文件block的存放(表达式的规则在后面会详细提到).
- 现有HDFS StorageType功能将不被包括进来,同时也不会被影响.
- 需要有Nodelabel相关的Admin管理员工具命令,包括如下4方面
- 动态地关联/解除关联label与各个节点.
- 列出指定节点所关联的label.
- 从集群中删除某label.
- label标签的访问控制管理.
NodeLabel的具体实现细节
首先我们来看增删改label的操作命令,目标的命令格式如下:
// 创建label标签
hdfs nodelabels -createNodeLabel -name <labelname> [-type labeltype] -acl <aclspec>
// 修改label标签
hdfs nodelabels -modifyNodeLabelACL -name <labelname> [-x] -acl <aclspec>
// 删除label标签
hdfs nodelabels -removeNodeLabel -name <labelName>
// 列表label标签
hdfs nodelabels -listNodeLabels [datanode-name]
hdfs nodelabels -listNodesForLabel -name <labelName>集群中的标签创建好了之后,接下来的操作就是将label与各个DataNode进行关联,将标签打到节点上,模板命令如下:
// 将label标签管理到指定节点
hdfs nodelabels -addDataNodeLabel -name <labelname> [-type <labeltype>] <dn_ipc_addess>
// 将label从指定节点上移除
hdfs nodelabels -removeDataNodeLabel -name <labelName> <dn_ipc_addess>前面2步操作完成之后,最后一步就是对目标写入文件的标签设置,操作的目的是将对应label的文件存储到对应label的DataNode上.操作的模板命令如下:
// 对指定文件/目录的path设置label表达式
hdfs nodelabels –setLabelExpression <expression> <path>
// 清空指定文件/目录的path的label表达式
hdfs nodelabels –clearLabelExpression <expression> <path>从上面的命令中,我们看到这里对于文件目录的标签设置采用的expression的形式而不是纯label的方式,设计者有什么用意在里面呢?答案是为了更加的灵活性.以社区设计文档中所提到的例子为例,假设当前结构如下:
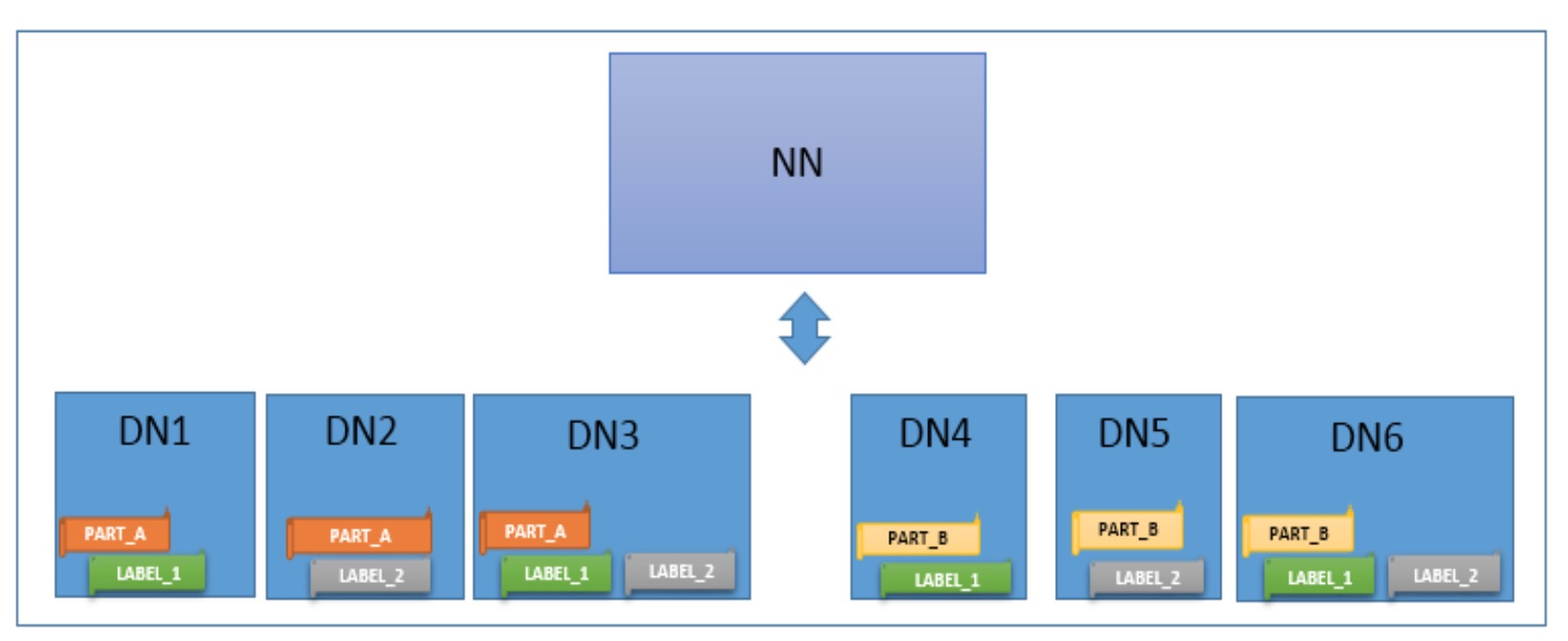
图1-1 HDFS NodeLabel集群
从上图我们可以看出,逻辑上DN被分为了Partition1和Partition2两个分段,然后在细节上,部分DN还被打上了各自的特性标签LABEL1,2等等.此时我们对某文件设置了如下表达式的label:
(LABEL_1 || LABEL_2) && PART_A于是在上图中,此文件将会选择DN1,DN2,DN3作为目标存储节点.在设计的初期,为了实现的简单性,我们只需支持||和&&2种表达式操作即可.
BlockPlacement Policy的支持
HDFS Label的引入对原本的block放置策略不会造成根本影响,但是在选择目标节点的方法上需要做一些改变,如下:
原方法:
public abstract DatanodeStorageInfo[] chooseTarget(String srcPath,
int numOfReplicas,
Node writer,
List<DatanodeStorageInfo> chosen,
boolean returnChosenNodes,
Set<Node> excludedNodes,
long blocksize,
BlockStoragePolicy storagePolicy,
EnumSet<AddBlockFlag> flags);在此增加一个参数,用于label标签的判断:
public abstract DatanodeStorageInfo[] chooseTarget(String srcPath,
int numOfReplicas,
Node writer,
List<DatanodeStorageInfo> chosen,
boolean returnChosenNodes,
Set<Node> excludedNodes,
long blocksize,
BlockStoragePolicy storagePolicy,
EnumSet<AddBlockFlag> flags,
NodeLabelExpression labelExpression);NodeLabel标签相关统计
NodeLabel标签相关的统计同样是不可忽视的一点,主要有以下一些指标统计(针对的前提都为单个NodeLabel):
- 此NodeLabel的磁盘Capacity容量.
- 此NodeLabel的磁盘使用量.
- 此NodeLabel的总block数.
- 此NodeLabel关联的活跃的DataNode数.
- 此NodeLabel关联的Dead的DataNode数.
- 此NodeLabel关联的下线状态的DataNode数.
- 此NodeLabel关联的处于下线中状态的DataNode数.
NodeLabel周边服务的支持
在未来的实现中,我们还需要完善NodeLabel相关周边服务的支持,主要在于以下2点:
第一点, WebUI的NodeLabel显示支持.
第二点, 围绕NodeLabel相关节点的Balancer数据平衡的操作.
NodeLabel的未来优化点
在官方的设计文档中,只提到了以下两点:
- 支持更多复杂的Label表达式.
- 支持同一个block块的多个副本的不同Partition的存放.
HDFS NodeLabel的类似实现: YARN NodeLabel
尽管HDFS NodeLabel功能还未实现,但是我们可以看一下与其在设计思路上极为类似的YARN NodeLabel.前面小节列出的许多HDFS NodeLabel的实现点在YARN的NodeLabel已经有了实现.下面列出其中几点.
首先是NodeLabel的持久化,在YARN中通过配置项yarn.node-labels.fs-store.root-dir来控制NodeLabel的存储,此配置项目可以是HDFS上的路径或者是一个本地的文件路径,如下:
// hdfs存储路径
hdfs://namenode:port/path/to/store/node-labels/
// 本地文件系统存储路径
file:///home/yarn/node-label以此做到重启集群的时候NodeLabel信息不会丢失.
又比如说,NodeLabel在WebUI上的显示,在链接http://RM-Address:port/cluster/nodelabels上可以查看,上面还汇集了每个NodeLabel下的总资源情况.

图1-2 YARN NodeLabel页
以此我们可以类比出HDFS NodelLabel的UI统计显示.但是在仔细查看YARN NodeLabel的细节中,它还能支持queue上的label配置,以此来控制此队列上的任务只能使用对应label的资源.
总结
本文的内容主要来自于HDFS-9411的设计文档,本文算是对其的一个缩略的译文,相信HDFS NodeLabel的功能特性将会是一个很棒的特性.
参考资料
[1].https://issues.apache.org/jira/browse/HDFS-9411
[2].https://issues.apache.org/jira/secure/attachment/12811794/HDFSNodeLabels-20-06-2016.pdf
[3].http://hadoop.apache.org/docs/current/hadoop-yarn/hadoop-yarn-site/NodeLabel.html