前言
Hadoop系统作为一个比较成熟的分布式系统,他被人们常常定义为一个存储海量数据的地方,与MySQL这里传统的RDBMS数据库有着明显的不同。Hadoop拥有着他天然的优势,他可以存储PB级别的数据,只要你的机器够多,我就可以存那么多,而且帮你考虑了副本备份这样的机制,只能说,Hadoop这一整套体系真的很完善。说到Hadoop的海量数据存储量,每一天的数据增量可以基本达到TB级别,对于一个类似于BAT这种级别的公司来说,于是有一个很重要的东西我们需把控制住,那就是数据的使用情况的数据,说白了就是你存储的数据有多少个block块,文件目录多少个,磁盘使用了多少PB,剩余多少空间等等这样的信息。这类信息的获取对于当前集群的数据使用情况以及未来趋势的分析都有很大的帮助作用,当然Hadoop自身并不会帮你做这样的事情,所以你要想办法自己去拿,那么如何去拿这部分的数据呢,这就是我今天所要给大家分享的。
要获取拿些数据
数据不是获取的越多,越细就好的,因为你要考虑你的成本代价的,在这里我们很明确,我们只需要一个宏观上的数据,总体使用情况的一些数据,比如dfs资源使用量,具体这类的信息这些信息可以参考namenode的页面数据,下面图中所示的一些就是不错的数据.
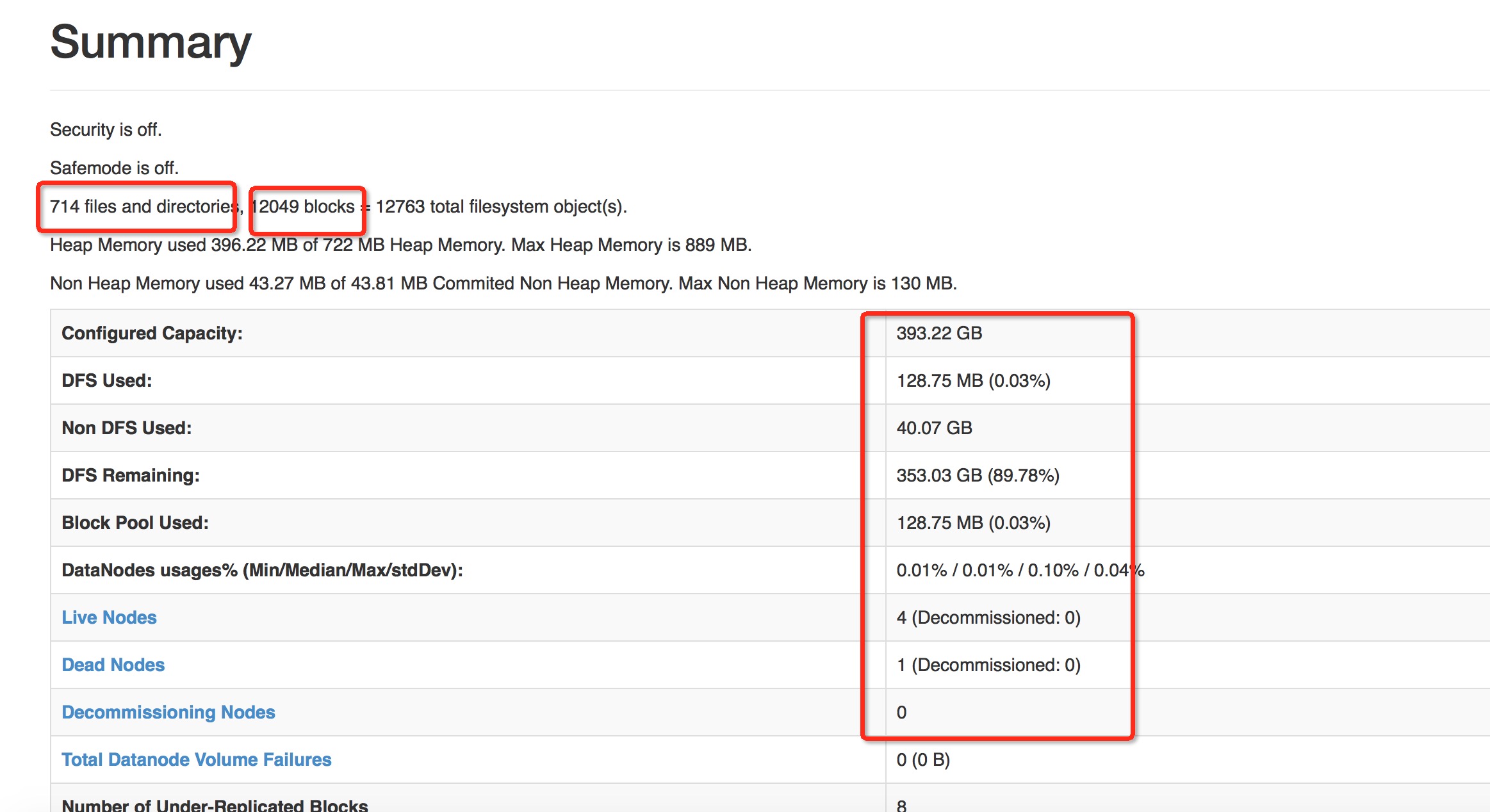
这些数据足以可以展现目前集群的数据使用情况以及数据的未来分析了.OK,我们就可以以这些数据为目标,想尽一起办法去获得其中的数据.
如何获取这些数据
目标倒是有了,但是如何去获取数据呢,如果你想走hdfs 命令行的方式去获取,答案当然是有,,研究过Hadoop-2.7.1源码的同学们应该知道,这个版本的发布包里包含了许多分析fsimage的命令,这些命令可以离线计算集群的file block块的信息,这些命令具体都是以bin/hdfs oiv [-args]开头,就是offlineImageView的缩写.但是这种方法有几个弊端,效率低,性能差,为什么这么说呢,因为每次分析fsimage的文件数据,数据每次都需要重新来过,而且当fsimage文件变得越来越大的时候,所需要的计算延时必然会增大,而且如果这个命令本身属于篇离线分析型的命令,不适合定时周期性去跑的,假设我们想以后缩小间隔数据获取,30分钟获取一下file,block数量,怎么办,所以最佳的办法就是以namenode页面数据获取的方式去拿到这些数据,因为我们经常刷新页面就能得到更新过后的数据,说明这个页面有自己的一套获取这方面数据的方法,只要我们找到了这方面的代码,基本就算大功告成了.中间我这里省略许多如何找这部分代码的过程,最后直接给出结果吧,HDFS的确没有在dfsAdmin这样的命令中添加类似的命令,也没有添加对应的RPC接口.我最后是通过找到,控制此页面的dfshealth.html文件才找到这段代码的,就是下面这个类中设计的代码,最终走的是http请求获取信息的.
/**
* Licensed to the Apache Software Foundation (ASF) under one
* or more contributor license agreements. See the NOTICE file
* distributed with this work for additional information
* regarding copyright ownership. The ASF licenses this file
* to you under the Apache License, Version 2.0 (the
* "License"); you may not use this file except in compliance
* with the License. You may obtain a copy of the License at
*
* http://www.apache.org/licenses/LICENSE-2.0
*
* Unless required by applicable law or agreed to in writing, software
* distributed under the License is distributed on an "AS IS" BASIS,
* WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
* See the License for the specific language governing permissions and
* limitations under the License.
*/
package org.apache.hadoop.hdfs.server.namenode;
import java.io.BufferedReader;
import java.io.IOException;
import java.io.InputStreamReader;
import java.net.InetSocketAddress;
import java.net.URI;
import java.net.URL;
import java.net.URLConnection;
import java.util.ArrayList;
import java.util.HashMap;
import java.util.Iterator;
import java.util.List;
import java.util.Map;
import java.util.Map.Entry;
import java.util.Set;
import javax.management.MalformedObjectNameException;
import org.apache.commons.logging.Log;
import org.apache.commons.logging.LogFactory;
import org.apache.hadoop.classification.InterfaceAudience;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.hdfs.DFSConfigKeys;
import org.apache.hadoop.hdfs.DFSUtil;
import org.apache.hadoop.hdfs.DFSUtil.ConfiguredNNAddress;
import org.apache.hadoop.hdfs.protocol.DatanodeInfo.AdminStates;
import org.apache.hadoop.util.StringUtils;
import org.codehaus.jackson.JsonNode;
import org.codehaus.jackson.map.ObjectMapper;
import org.codehaus.jackson.type.TypeReference;
import org.znerd.xmlenc.XMLOutputter;
import com.google.common.base.Charsets;
/**
* This class generates the data that is needed to be displayed on cluster web
* console.
*/
@InterfaceAudience.Private
class ClusterJspHelper {
private static final Log LOG = LogFactory.getLog(ClusterJspHelper.class);
public static final String OVERALL_STATUS = "overall-status";
public static final String DEAD = "Dead";
private static final String JMX_QRY =
"/jmx?qry=Hadoop:service=NameNode,name=NameNodeInfo";
/**
* JSP helper function that generates cluster health report. When
* encountering exception while getting Namenode status, the exception will
* be listed on the page with corresponding stack trace.
*/
ClusterStatus generateClusterHealthReport() {
ClusterStatus cs = new ClusterStatus();
Configuration conf = new Configuration();
List<ConfiguredNNAddress> nns = null;
try {
nns = DFSUtil.flattenAddressMap(
DFSUtil.getNNServiceRpcAddresses(conf));
} catch (Exception e) {
// Could not build cluster status
cs.setError(e);
return cs;
}
// Process each namenode and add it to ClusterStatus
for (ConfiguredNNAddress cnn : nns) {
InetSocketAddress isa = cnn.getAddress();
NamenodeMXBeanHelper nnHelper = null;
try {
nnHelper = new NamenodeMXBeanHelper(isa, conf);
String mbeanProps= queryMbean(nnHelper.httpAddress, conf);
NamenodeStatus nn = nnHelper.getNamenodeStatus(mbeanProps);
if (cs.clusterid.isEmpty() || cs.clusterid.equals("")) { // Set clusterid only once
cs.clusterid = nnHelper.getClusterId(mbeanProps);
}
cs.addNamenodeStatus(nn);
} catch ( Exception e ) {
// track exceptions encountered when connecting to namenodes
cs.addException(isa.getHostName(), e);
continue;
}
}
return cs;
}
/**
* Helper function that generates the decommissioning report. Connect to each
* Namenode over http via JmxJsonServlet to collect the data nodes status.
*/
DecommissionStatus generateDecommissioningReport() {
String clusterid = "";
Configuration conf = new Configuration();
List<ConfiguredNNAddress> cnns = null;
try {
cnns = DFSUtil.flattenAddressMap(
DFSUtil.getNNServiceRpcAddresses(conf));
} catch (Exception e) {
// catch any exception encountered other than connecting to namenodes
DecommissionStatus dInfo = new DecommissionStatus(clusterid, e);
return dInfo;
}
// Outer map key is datanode. Inner map key is namenode and the value is
// decom status of the datanode for the corresponding namenode
Map<String, Map<String, String>> statusMap =
new HashMap<String, Map<String, String>>();
// Map of exceptions encountered when connecting to namenode
// key is namenode and value is exception
Map<String, Exception> decommissionExceptions =
new HashMap<String, Exception>();
List<String> unreportedNamenode = new ArrayList<String>();
for (ConfiguredNNAddress cnn : cnns) {
InetSocketAddress isa = cnn.getAddress();
NamenodeMXBeanHelper nnHelper = null;
try {
nnHelper = new NamenodeMXBeanHelper(isa, conf);
String mbeanProps= queryMbean(nnHelper.httpAddress, conf);
if (clusterid.equals("")) {
clusterid = nnHelper.getClusterId(mbeanProps);
}
nnHelper.getDecomNodeInfoForReport(statusMap, mbeanProps);
} catch (Exception e) {
// catch exceptions encountered while connecting to namenodes
String nnHost = isa.getHostName();
decommissionExceptions.put(nnHost, e);
unreportedNamenode.add(nnHost);
continue;
}
}
updateUnknownStatus(statusMap, unreportedNamenode);
getDecommissionNodeClusterState(statusMap);
return new DecommissionStatus(statusMap, clusterid,
getDatanodeHttpPort(conf), decommissionExceptions);
}
/**
* Based on the state of the datanode at each namenode, marks the overall
* state of the datanode across all the namenodes, to one of the following:
* <ol>
* <li>{@link DecommissionStates#DECOMMISSIONED}</li>
* <li>{@link DecommissionStates#DECOMMISSION_INPROGRESS}</li>
* <li>{@link DecommissionStates#PARTIALLY_DECOMMISSIONED}</li>
* <li>{@link DecommissionStates#UNKNOWN}</li>
* </ol>
*
* @param statusMap
* map whose key is datanode, value is an inner map with key being
* namenode, value being decommission state.
*/
private void getDecommissionNodeClusterState(
Map<String, Map<String, String>> statusMap) {
if (statusMap == null || statusMap.isEmpty()) {
return;
}
// For each datanodes
Iterator<Entry<String, Map<String, String>>> it =
statusMap.entrySet().iterator();
while (it.hasNext()) {
// Map entry for a datanode:
// key is namenode, value is datanode status at the namenode
Entry<String, Map<String, String>> entry = it.next();
Map<String, String> nnStatus = entry.getValue();
if (nnStatus == null || nnStatus.isEmpty()) {
continue;
}
boolean isUnknown = false;
int unknown = 0;
int decommissioned = 0;
int decomInProg = 0;
int inservice = 0;
int dead = 0;
DecommissionStates overallState = DecommissionStates.UNKNOWN;
// Process a datanode state from each namenode
for (Map.Entry<String, String> m : nnStatus.entrySet()) {
String status = m.getValue();
if (status.equals(DecommissionStates.UNKNOWN.toString())) {
isUnknown = true;
unknown++;
} else
if (status.equals(AdminStates.DECOMMISSION_INPROGRESS.toString())) {
decomInProg++;
} else if (status.equals(AdminStates.DECOMMISSIONED.toString())) {
decommissioned++;
} else if (status.equals(AdminStates.NORMAL.toString())) {
inservice++;
} else if (status.equals(DEAD)) {
// dead
dead++;
}
}
// Consolidate all the states from namenode in to overall state
int nns = nnStatus.keySet().size();
if ((inservice + dead + unknown) == nns) {
// Do not display this data node. Remove this entry from status map.
it.remove();
} else if (isUnknown) {
overallState = DecommissionStates.UNKNOWN;
} else if (decommissioned == nns) {
overallState = DecommissionStates.DECOMMISSIONED;
} else if ((decommissioned + decomInProg) == nns) {
overallState = DecommissionStates.DECOMMISSION_INPROGRESS;
} else if ((decommissioned + decomInProg < nns)
&& (decommissioned + decomInProg > 0)){
overallState = DecommissionStates.PARTIALLY_DECOMMISSIONED;
} else {
LOG.warn("Cluster console encounters a not handled situtation.");
}
// insert overall state
nnStatus.put(OVERALL_STATUS, overallState.toString());
}
}
/**
* update unknown status in datanode status map for every unreported namenode
*/
private void updateUnknownStatus(Map<String, Map<String, String>> statusMap,
List<String> unreportedNn) {
if (unreportedNn == null || unreportedNn.isEmpty()) {
// no unreported namenodes
return;
}
for (Map.Entry<String, Map<String,String>> entry : statusMap.entrySet()) {
String dn = entry.getKey();
Map<String, String> nnStatus = entry.getValue();
for (String nn : unreportedNn) {
nnStatus.put(nn, DecommissionStates.UNKNOWN.toString());
}
statusMap.put(dn, nnStatus);
}
}
/**
* Get datanode http port from configration
*/
private int getDatanodeHttpPort(Configuration conf) {
String address = conf.get(DFSConfigKeys.DFS_DATANODE_HTTP_ADDRESS_KEY, "");
if (address.equals("")) {
return -1;
}
return Integer.parseInt(address.split(":")[1]);
}
/**
* Class for connecting to Namenode over http via JmxJsonServlet
* to get JMX attributes exposed by the MXBean.
*/
static class NamenodeMXBeanHelper {
private static final ObjectMapper mapper = new ObjectMapper();
private final String host;
private final URI httpAddress;
NamenodeMXBeanHelper(InetSocketAddress addr, Configuration conf)
throws IOException, MalformedObjectNameException {
this.host = addr.getHostName();
this.httpAddress = DFSUtil.getInfoServer(addr, conf,
DFSUtil.getHttpClientScheme(conf));
}
/** Get the map corresponding to the JSON string */
private static Map<String, Map<String, Object>> getNodeMap(String json)
throws IOException {
TypeReference<Map<String, Map<String, Object>>> type =
new TypeReference<Map<String, Map<String, Object>>>() { };
return mapper.readValue(json, type);
}
/**
* Get the number of live datanodes.
*
* @param json JSON string that contains live node status.
* @param nn namenode status to return information in
*/
private static void getLiveNodeCount(String json, NamenodeStatus nn)
throws IOException {
// Map of datanode host to (map of attribute name to value)
Map<String, Map<String, Object>> nodeMap = getNodeMap(json);
if (nodeMap == null || nodeMap.isEmpty()) {
return;
}
nn.liveDatanodeCount = nodeMap.size();
for (Entry<String, Map<String, Object>> entry : nodeMap.entrySet()) {
// Inner map of attribute name to value
Map<String, Object> innerMap = entry.getValue();
if (innerMap != null) {
if (innerMap.get("adminState")
.equals(AdminStates.DECOMMISSIONED.toString())) {
nn.liveDecomCount++;
}
}
}
}
/**
* Count the number of dead datanode.
*
* @param nn namenode
* @param json JSON string
*/
private static void getDeadNodeCount(String json, NamenodeStatus nn)
throws IOException {
Map<String, Map<String, Object>> nodeMap = getNodeMap(json);
if (nodeMap == null || nodeMap.isEmpty()) {
return;
}
nn.deadDatanodeCount = nodeMap.size();
for (Entry<String, Map<String, Object>> entry : nodeMap.entrySet()) {
Map<String, Object> innerMap = entry.getValue();
if (innerMap != null && !innerMap.isEmpty()) {
if (((Boolean) innerMap.get("decommissioned"))
.booleanValue() == true) {
nn.deadDecomCount++;
}
}
}
}
public String getClusterId(String props) throws IOException {
return getProperty(props, "ClusterId").getTextValue();
}
public NamenodeStatus getNamenodeStatus(String props) throws IOException,
MalformedObjectNameException, NumberFormatException {
NamenodeStatus nn = new NamenodeStatus();
nn.host = host;
nn.filesAndDirectories = getProperty(props, "TotalFiles").getLongValue();
nn.capacity = getProperty(props, "Total").getLongValue();
nn.free = getProperty(props, "Free").getLongValue();
nn.bpUsed = getProperty(props, "BlockPoolUsedSpace").getLongValue();
nn.nonDfsUsed = getProperty(props, "NonDfsUsedSpace").getLongValue();
nn.blocksCount = getProperty(props, "TotalBlocks").getLongValue();
nn.missingBlocksCount = getProperty(props, "NumberOfMissingBlocks")
.getLongValue();
nn.httpAddress = httpAddress.toURL();
getLiveNodeCount(getProperty(props, "LiveNodes").asText(), nn);
getDeadNodeCount(getProperty(props, "DeadNodes").asText(), nn);
nn.softwareVersion = getProperty(props, "SoftwareVersion").getTextValue();
return nn;
}
/**
* Get the decommission node information.
* @param statusMap data node status map
* @param props string
*/
private void getDecomNodeInfoForReport(
Map<String, Map<String, String>> statusMap, String props)
throws IOException, MalformedObjectNameException {
getLiveNodeStatus(statusMap, host, getProperty(props, "LiveNodes")
.asText());
getDeadNodeStatus(statusMap, host, getProperty(props, "DeadNodes")
.asText());
getDecommissionNodeStatus(statusMap, host,
getProperty(props, "DecomNodes").asText());
}
/**
* Store the live datanode status information into datanode status map and
* DecommissionNode.
*
* @param statusMap Map of datanode status. Key is datanode, value
* is an inner map whose key is namenode, value is datanode status.
* reported by each namenode.
* @param namenodeHost host name of the namenode
* @param json JSON string contains datanode status
* @throws IOException
*/
private static void getLiveNodeStatus(
Map<String, Map<String, String>> statusMap, String namenodeHost,
String json) throws IOException {
Map<String, Map<String, Object>> nodeMap = getNodeMap(json);
if (nodeMap != null && !nodeMap.isEmpty()) {
List<String> liveDecommed = new ArrayList<String>();
for (Map.Entry<String, Map<String, Object>> entry: nodeMap.entrySet()) {
Map<String, Object> innerMap = entry.getValue();
String dn = entry.getKey();
if (innerMap != null) {
if (innerMap.get("adminState").equals(
AdminStates.DECOMMISSIONED.toString())) {
liveDecommed.add(dn);
}
// the inner map key is namenode, value is datanode status.
Map<String, String> nnStatus = statusMap.get(dn);
if (nnStatus == null) {
nnStatus = new HashMap<String, String>();
}
nnStatus.put(namenodeHost, (String) innerMap.get("adminState"));
// map whose key is datanode, value is the inner map.
statusMap.put(dn, nnStatus);
}
}
}
}
/**
* Store the dead datanode information into datanode status map and
* DecommissionNode.
*
* @param statusMap map with key being datanode, value being an
* inner map (key:namenode, value:decommisionning state).
* @param host datanode hostname
* @param json String
* @throws IOException
*/
private static void getDeadNodeStatus(
Map<String, Map<String, String>> statusMap, String host,
String json) throws IOException {
Map<String, Map<String, Object>> nodeMap = getNodeMap(json);
if (nodeMap == null || nodeMap.isEmpty()) {
return;
}
List<String> deadDn = new ArrayList<String>();
List<String> deadDecommed = new ArrayList<String>();
for (Entry<String, Map<String, Object>> entry : nodeMap.entrySet()) {
deadDn.add(entry.getKey());
Map<String, Object> deadNodeDetailMap = entry.getValue();
String dn = entry.getKey();
if (deadNodeDetailMap != null && !deadNodeDetailMap.isEmpty()) {
// NN - status
Map<String, String> nnStatus = statusMap.get(dn);
if (nnStatus == null) {
nnStatus = new HashMap<String, String>();
}
if (((Boolean) deadNodeDetailMap.get("decommissioned"))
.booleanValue() == true) {
deadDecommed.add(dn);
nnStatus.put(host, AdminStates.DECOMMISSIONED.toString());
} else {
nnStatus.put(host, DEAD);
}
// dn-nn-status
statusMap.put(dn, nnStatus);
}
}
}
/**
* Get the decommisioning datanode information.
*
* @param dataNodeStatusMap map with key being datanode, value being an
* inner map (key:namenode, value:decommisionning state).
* @param host datanode
* @param json String
*/
private static void getDecommissionNodeStatus(
Map<String, Map<String, String>> dataNodeStatusMap, String host,
String json) throws IOException {
Map<String, Map<String, Object>> nodeMap = getNodeMap(json);
if (nodeMap == null || nodeMap.isEmpty()) {
return;
}
List<String> decomming = new ArrayList<String>();
for (Entry<String, Map<String, Object>> entry : nodeMap.entrySet()) {
String dn = entry.getKey();
decomming.add(dn);
// nn-status
Map<String, String> nnStatus = new HashMap<String, String>();
if (dataNodeStatusMap.containsKey(dn)) {
nnStatus = dataNodeStatusMap.get(dn);
}
nnStatus.put(host, AdminStates.DECOMMISSION_INPROGRESS.toString());
// dn-nn-status
dataNodeStatusMap.put(dn, nnStatus);
}
}
}
/**
* This class contains cluster statistics.
*/
static class ClusterStatus {
/** Exception indicates failure to get cluster status */
Exception error = null;
/** Cluster status information */
String clusterid = "";
long total_sum = 0;
long free_sum = 0;
long clusterDfsUsed = 0;
long nonDfsUsed_sum = 0;
long totalFilesAndDirectories = 0;
/** List of namenodes in the cluster */
final List<NamenodeStatus> nnList = new ArrayList<NamenodeStatus>();
/** Map of namenode host and exception encountered when getting status */
final Map<String, Exception> nnExceptions = new HashMap<String, Exception>();
public void setError(Exception e) {
error = e;
}
public void addNamenodeStatus(NamenodeStatus nn) {
nnList.add(nn);
// Add namenode status to cluster status
totalFilesAndDirectories += nn.filesAndDirectories;
total_sum += nn.capacity;
free_sum += nn.free;
clusterDfsUsed += nn.bpUsed;
nonDfsUsed_sum += nn.nonDfsUsed;
}
public void addException(String host, Exception e) {
nnExceptions.put(host, e);
}
public void toXML(XMLOutputter doc) throws IOException {
if (error != null) {
// general exception, only print exception message onto web page.
createGeneralException(doc, clusterid,
StringUtils.stringifyException(error));
doc.getWriter().flush();
return;
}
int size = nnList.size();
long total = 0L, free = 0L, nonDfsUsed = 0l;
float dfsUsedPercent = 0.0f, dfsRemainingPercent = 0.0f;
if (size > 0) {
total = total_sum / size;
free = free_sum / size;
nonDfsUsed = nonDfsUsed_sum / size;
dfsUsedPercent = DFSUtil.getPercentUsed(clusterDfsUsed, total);
dfsRemainingPercent = DFSUtil.getPercentRemaining(free, total);
}
doc.startTag("cluster");
doc.attribute("clusterId", clusterid);
doc.startTag("storage");
toXmlItemBlock(doc, "Total Files And Directories",
Long.toString(totalFilesAndDirectories));
toXmlItemBlock(doc, "Configured Capacity", StringUtils.byteDesc(total));
toXmlItemBlock(doc, "DFS Used", StringUtils.byteDesc(clusterDfsUsed));
toXmlItemBlock(doc, "Non DFS Used", StringUtils.byteDesc(nonDfsUsed));
toXmlItemBlock(doc, "DFS Remaining", StringUtils.byteDesc(free));
// dfsUsedPercent
toXmlItemBlock(doc, "DFS Used%", DFSUtil.percent2String(dfsUsedPercent));
// dfsRemainingPercent
toXmlItemBlock(doc, "DFS Remaining%", DFSUtil.percent2String(dfsRemainingPercent));
doc.endTag(); // storage
doc.startTag("namenodes");
// number of namenodes
toXmlItemBlock(doc, "NamenodesCount", Integer.toString(size));
for (NamenodeStatus nn : nnList) {
doc.startTag("node");
toXmlItemBlockWithLink(doc, nn.host, nn.httpAddress, "NameNode");
toXmlItemBlock(doc, "Blockpool Used",
StringUtils.byteDesc(nn.bpUsed));
toXmlItemBlock(doc, "Blockpool Used%",
DFSUtil.percent2String(DFSUtil.getPercentUsed(nn.bpUsed, total)));
toXmlItemBlock(doc, "Files And Directories",
Long.toString(nn.filesAndDirectories));
toXmlItemBlock(doc, "Blocks", Long.toString(nn.blocksCount));
toXmlItemBlock(doc, "Missing Blocks",
Long.toString(nn.missingBlocksCount));
toXmlItemBlockWithLink(doc, nn.liveDatanodeCount + " ("
+ nn.liveDecomCount + ")", new URL(nn.httpAddress,
"/dfsnodelist.jsp?whatNodes=LIVE"),
"Live Datanode (Decommissioned)");
toXmlItemBlockWithLink(doc, nn.deadDatanodeCount + " ("
+ nn.deadDecomCount + ")", new URL(nn.httpAddress,
"/dfsnodelist.jsp?whatNodes=DEAD"),
"Dead Datanode (Decommissioned)");
toXmlItemBlock(doc, "Software Version", nn.softwareVersion);
doc.endTag(); // node
}
doc.endTag(); // namenodes
createNamenodeExceptionMsg(doc, nnExceptions);
doc.endTag(); // cluster
doc.getWriter().flush();
}
}
/**
* This class stores namenode statistics to be used to generate cluster
* web console report.
*/
static class NamenodeStatus {
String host = "";
long capacity = 0L;
long free = 0L;
long bpUsed = 0L;
long nonDfsUsed = 0L;
long filesAndDirectories = 0L;
long blocksCount = 0L;
long missingBlocksCount = 0L;
int liveDatanodeCount = 0;
int liveDecomCount = 0;
int deadDatanodeCount = 0;
int deadDecomCount = 0;
URL httpAddress = null;
String softwareVersion = "";
}
/**
* cluster-wide decommission state of a datanode
*/
public enum DecommissionStates {
/*
* If datanode state is decommissioning at one or more namenodes and
* decommissioned at the rest of the namenodes.
*/
DECOMMISSION_INPROGRESS("Decommission In Progress"),
/* If datanode state at all the namenodes is decommissioned */
DECOMMISSIONED("Decommissioned"),
/*
* If datanode state is not decommissioning at one or more namenodes and
* decommissioned/decommissioning at the rest of the namenodes.
*/
PARTIALLY_DECOMMISSIONED("Partially Decommissioning"),
/*
* If datanode state is not known at a namenode, due to problems in getting
* the datanode state from the namenode.
*/
UNKNOWN("Unknown");
final String value;
DecommissionStates(final String v) {
this.value = v;
}
@Override
public String toString() {
return value;
}
}
/**
* This class consolidates the decommissioning datanodes information in the
* cluster and generates decommissioning reports in XML.
*/
static class DecommissionStatus {
/** Error when set indicates failure to get decomission status*/
final Exception error;
/** Map of dn host <-> (Map of NN host <-> decommissioning state) */
final Map<String, Map<String, String>> statusMap;
final String clusterid;
final int httpPort;
int decommissioned = 0; // total number of decommissioned nodes
int decommissioning = 0; // total number of decommissioning datanodes
int partial = 0; // total number of partially decommissioned nodes
/** Map of namenode and exception encountered when getting decom status */
Map<String, Exception> exceptions = new HashMap<String, Exception>();
private DecommissionStatus(Map<String, Map<String, String>> statusMap,
String cid, int httpPort, Map<String, Exception> exceptions) {
this(statusMap, cid, httpPort, exceptions, null);
}
public DecommissionStatus(String cid, Exception e) {
this(null, cid, -1, null, e);
}
private DecommissionStatus(Map<String, Map<String, String>> statusMap,
String cid, int httpPort, Map<String, Exception> exceptions,
Exception error) {
this.statusMap = statusMap;
this.clusterid = cid;
this.httpPort = httpPort;
this.exceptions = exceptions;
this.error = error;
}
/**
* Generate decommissioning datanode report in XML format
*
* @param doc
* , xmloutputter
* @throws IOException
*/
public void toXML(XMLOutputter doc) throws IOException {
if (error != null) {
createGeneralException(doc, clusterid,
StringUtils.stringifyException(error));
doc.getWriter().flush();
return;
}
if (statusMap == null || statusMap.isEmpty()) {
// none of the namenodes has reported, print exceptions from each nn.
doc.startTag("cluster");
createNamenodeExceptionMsg(doc, exceptions);
doc.endTag();
doc.getWriter().flush();
return;
}
doc.startTag("cluster");
doc.attribute("clusterId", clusterid);
doc.startTag("decommissioningReport");
countDecommissionDatanodes();
toXmlItemBlock(doc, DecommissionStates.DECOMMISSIONED.toString(),
Integer.toString(decommissioned));
toXmlItemBlock(doc,
DecommissionStates.DECOMMISSION_INPROGRESS.toString(),
Integer.toString(decommissioning));
toXmlItemBlock(doc,
DecommissionStates.PARTIALLY_DECOMMISSIONED.toString(),
Integer.toString(partial));
doc.endTag(); // decommissioningReport
doc.startTag("datanodes");
Set<String> dnSet = statusMap.keySet();
for (String dnhost : dnSet) {
Map<String, String> nnStatus = statusMap.get(dnhost);
if (nnStatus == null || nnStatus.isEmpty()) {
continue;
}
String overallStatus = nnStatus.get(OVERALL_STATUS);
// check if datanode is in decommission states
if (overallStatus != null
&& (overallStatus.equals(AdminStates.DECOMMISSION_INPROGRESS
.toString())
|| overallStatus.equals(AdminStates.DECOMMISSIONED.toString())
|| overallStatus
.equals(DecommissionStates.PARTIALLY_DECOMMISSIONED
.toString()) || overallStatus
.equals(DecommissionStates.UNKNOWN.toString()))) {
doc.startTag("node");
// dn
toXmlItemBlockWithLink(doc, dnhost, new URL("http", dnhost, httpPort,
""), "DataNode");
// overall status first
toXmlItemBlock(doc, OVERALL_STATUS, overallStatus);
for (Map.Entry<String, String> m : nnStatus.entrySet()) {
String nn = m.getKey();
if (nn.equals(OVERALL_STATUS)) {
continue;
}
// xml
toXmlItemBlock(doc, nn, nnStatus.get(nn));
}
doc.endTag(); // node
}
}
doc.endTag(); // datanodes
createNamenodeExceptionMsg(doc, exceptions);
doc.endTag();// cluster
} // toXML
/**
* Count the total number of decommissioned/decommission_inprogress/
* partially decommissioned datanodes.
*/
private void countDecommissionDatanodes() {
for (String dn : statusMap.keySet()) {
Map<String, String> nnStatus = statusMap.get(dn);
String status = nnStatus.get(OVERALL_STATUS);
if (status.equals(DecommissionStates.DECOMMISSIONED.toString())) {
decommissioned++;
} else if (status.equals(DecommissionStates.DECOMMISSION_INPROGRESS
.toString())) {
decommissioning++;
} else if (status.equals(DecommissionStates.PARTIALLY_DECOMMISSIONED
.toString())) {
partial++;
}
}
}
}
/**
* Generate a XML block as such, <item label=key value=value/>
*/
private static void toXmlItemBlock(XMLOutputter doc, String key, String value)
throws IOException {
doc.startTag("item");
doc.attribute("label", key);
doc.attribute("value", value);
doc.endTag();
}
/**
* Generate a XML block as such, <item label="Node" value="hostname"
* link="http://hostname:50070" />
*/
private static void toXmlItemBlockWithLink(XMLOutputter doc, String value,
URL url, String label) throws IOException {
doc.startTag("item");
doc.attribute("label", label);
doc.attribute("value", value);
doc.attribute("link", url.toString());
doc.endTag(); // item
}
/**
* create the XML for exceptions that we encountered when connecting to
* namenode.
*/
private static void createNamenodeExceptionMsg(XMLOutputter doc,
Map<String, Exception> exceptionMsg) throws IOException {
if (exceptionMsg.size() > 0) {
doc.startTag("unreportedNamenodes");
for (Map.Entry<String, Exception> m : exceptionMsg.entrySet()) {
doc.startTag("node");
doc.attribute("name", m.getKey());
doc.attribute("exception",
StringUtils.stringifyException(m.getValue()));
doc.endTag();// node
}
doc.endTag(); // unreportedNamnodes
}
}
/**
* create XML block from general exception.
*/
private static void createGeneralException(XMLOutputter doc,
String clusterid, String eMsg) throws IOException {
doc.startTag("cluster");
doc.attribute("clusterId", clusterid);
doc.startTag("message");
doc.startTag("item");
doc.attribute("msg", eMsg);
doc.endTag(); // item
doc.endTag(); // message
doc.endTag(); // cluster
}
/**
* Read in the content from a URL
* @param url URL To read
* @return the text from the output
* @throws IOException if something went wrong
*/
private static String readOutput(URL url) throws IOException {
StringBuilder out = new StringBuilder();
URLConnection connection = url.openConnection();
BufferedReader in = new BufferedReader(
new InputStreamReader(
connection.getInputStream(), Charsets.UTF_8));
String inputLine;
while ((inputLine = in.readLine()) != null) {
out.append(inputLine);
}
in.close();
return out.toString();
}
private static String queryMbean(URI httpAddress, Configuration conf)
throws IOException {
/**
* Although the other namenode might support HTTPS, it is fundamentally
* broken to get the JMX via an HTTPS connection inside the namenode,
* because in HTTPS set up the principal of the client and the one of
* the namenode differs. Therefore, there is no guarantees that the
* HTTPS connection can be set up.
*
* As a result, we just hard code the connection as an HTTP connection.
*/
URL url = new URL(httpAddress.toURL(), JMX_QRY);
return readOutput(url);
}
/**
* In order to query a namenode mxbean, a http connection in the form of
* "http://hostname/jmx?qry=Hadoop:service=NameNode,name=NameNodeInfo"
* is sent to namenode. JMX attributes are exposed via JmxJsonServelet on
* the namenode side.
*/
private static JsonNode getProperty(String props, String propertyname)
throws IOException {
if (props == null || props.equals("") || propertyname == null
|| propertyname.equals("")) {
return null;
}
ObjectMapper m = new ObjectMapper();
JsonNode rootNode = m.readValue(props, JsonNode.class);
JsonNode jn = rootNode.get("beans").get(0).get(propertyname);
return jn;
}
}
/**
* JSP helper function that generates cluster health report. When
* encountering exception while getting Namenode status, the exception will
* be listed on the page with corresponding stack trace.
*/
ClusterStatus generateClusterHealthReport() {
ClusterStatus cs = new ClusterStatus();
Configuration conf = new Configuration();
List<ConfiguredNNAddress> nns = null;
try {
nns = DFSUtil.flattenAddressMap(
DFSUtil.getNNServiceRpcAddresses(conf));
} catch (Exception e) {
// Could not build cluster status
cs.setError(e);
return cs;
}
// Process each namenode and add it to ClusterStatus
for (ConfiguredNNAddress cnn : nns) {
InetSocketAddress isa = cnn.getAddress();
NamenodeMXBeanHelper nnHelper = null;
try {
nnHelper = new NamenodeMXBeanHelper(isa, conf);
String mbeanProps= queryMbean(nnHelper.httpAddress, conf);
NamenodeStatus nn = nnHelper.getNamenodeStatus(mbeanProps);
if (cs.clusterid.isEmpty() || cs.clusterid.equals("")) { // Set clusterid only once
cs.clusterid = nnHelper.getClusterId(mbeanProps);
}
cs.addNamenodeStatus(nn);
} catch ( Exception e ) {
// track exceptions encountered when connecting to namenodes
cs.addException(isa.getHostName(), e);
continue;
}
}
return cs;
}/**
* This class stores namenode statistics to be used to generate cluster
* web console report.
*/
static class NamenodeStatus {
String host = "";
long capacity = 0L;
long free = 0L;
long bpUsed = 0L;
long nonDfsUsed = 0L;
long filesAndDirectories = 0L;
long blocksCount = 0L;
long missingBlocksCount = 0L;
int liveDatanodeCount = 0;
int liveDecomCount = 0;
int deadDatanodeCount = 0;
int deadDecomCount = 0;
URL httpAddress = null;
String softwareVersion = "";
}有了这些数据,怎么用
现在来考虑一个实际的问题,有了这些数据我们怎么用.首先要,明白一件事情,数据拿来是要存下的,所以第一首先就是存入数据库中,间隔周期可自己调,一般这样的数据比较倾向于用于分析数据增长走势的,所以建议做成折线趋势图,可以分为2个维度.
1.从file,dir文件目录数,block块折线趋势图,因为这2个指标可以明显的发现集群每日的写入量多少,一旦集群所持有的文件,block数太多,会导致namenode内存吃紧的,因为namenode要维护如此庞大的元数据信息压力会很大,第二这个指标在一定程度上会反映出小文件的个数情况,因为一旦小文件多了,比如说极端一点的情况,我有很多不到1M的文件写入集群,那这些不到1M的文件必然是单独的1个block块,会造成block增长趋势与filesAndDirs的数目增长趋势会很解决,存储空间并没有很大的影响,但是会对集群的性能造成影响,hadoop本身是不适用于过小文件的存放的,因为每读一个文件他要启动task,需要一定的成本代价,一旦你的小文件过多,首先会启动大量的map task去读文件,因为1个task只能读1个文件,甚至极端情况,某个job会有上千,上万个task,这个现象在我们公司确实发生过.
2.从dfs磁盘空间使用量的趋势分析图.这个很好理解,我就是想知道,我们集群每天数据增长的总量是多少T,多少G,方便我可以在适当的时候增加机器来扩充集群的容量.
下面给大家看2张,我们内部针对以上2点做的分析图表,仅供大家参考:
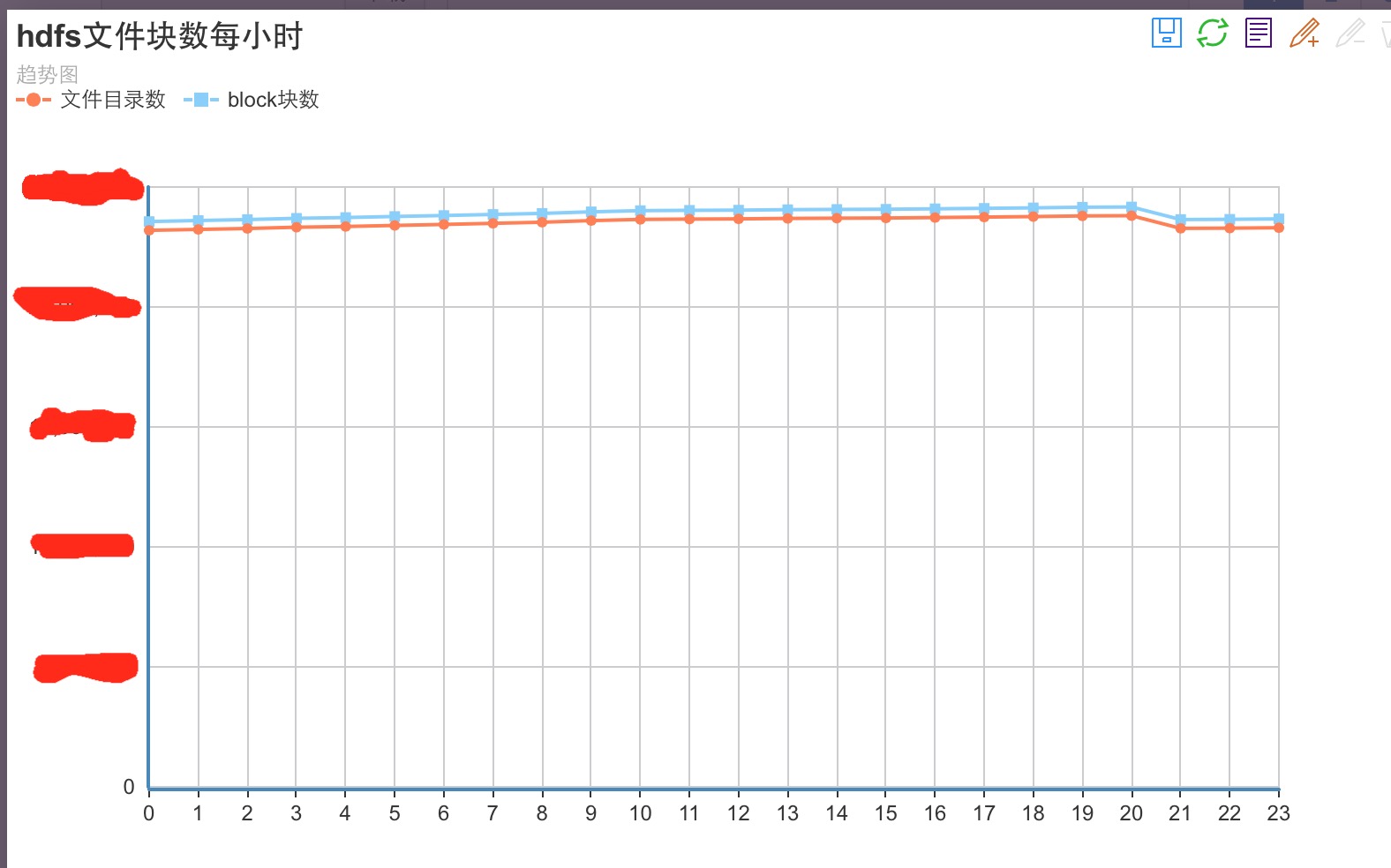
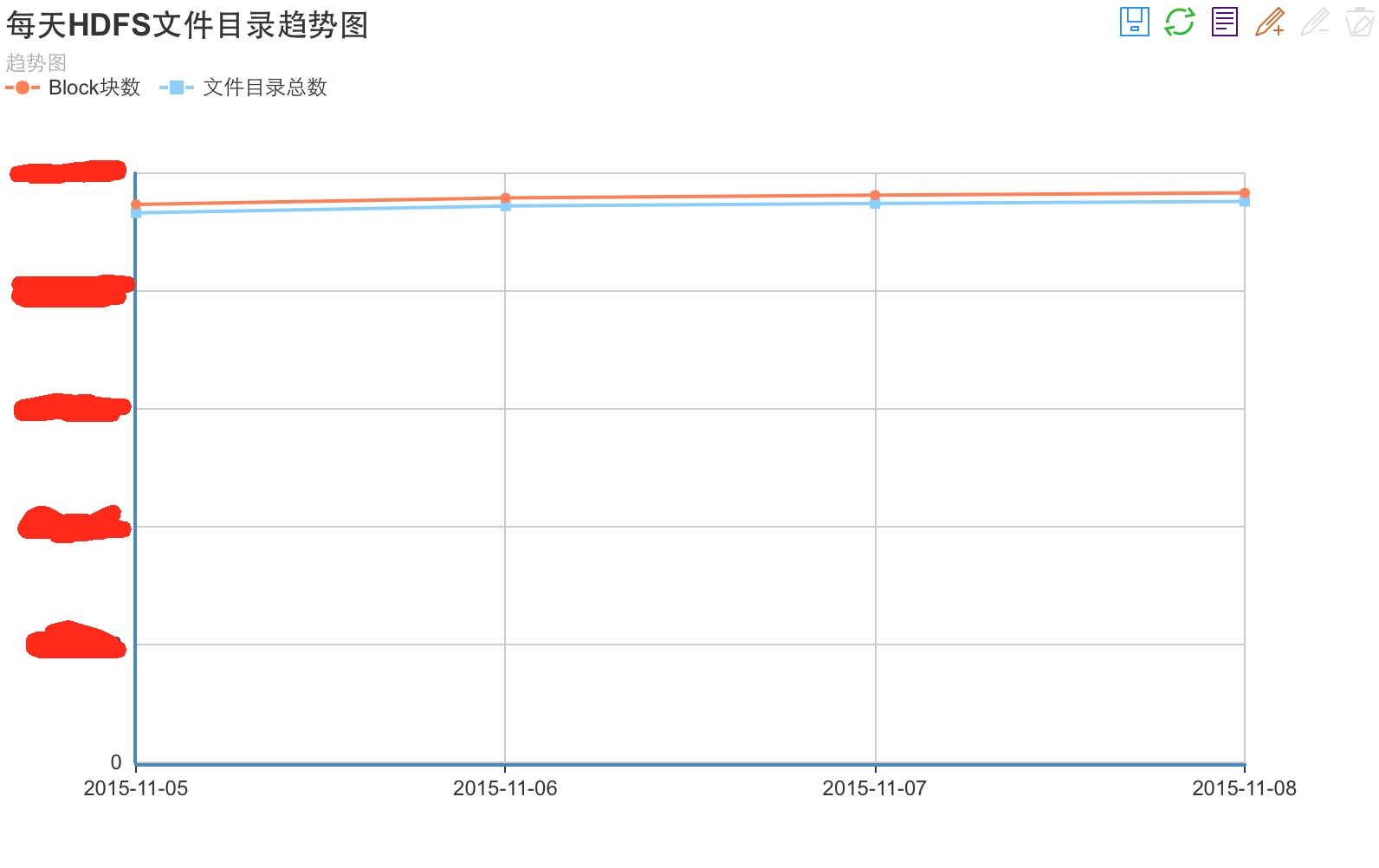
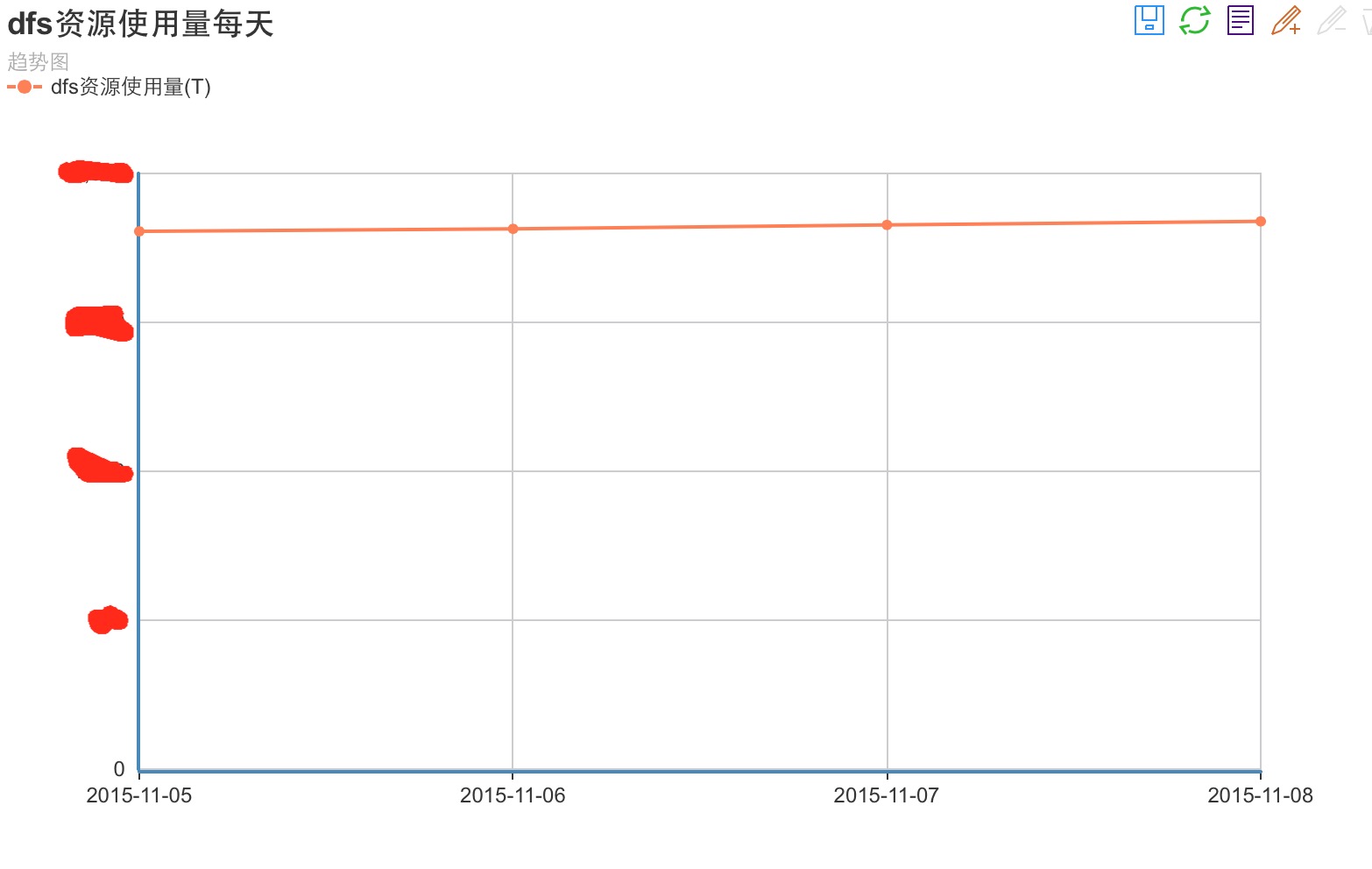
这里有个小建议,在做预测分析图表的时候,最后把每天的和每小时的都计算一遍,一个方便知道你的按天数据增长量,和1天内什么时段数据增长趋势块.
下面给出抓取数据的程序,这段代码里还有获取NodeManager信息的程序:
package mytool;
import java.io.IOException;
import java.text.DateFormat;
import java.text.SimpleDateFormat;
import java.util.ArrayList;
import java.util.Calendar;
import java.util.Collections;
import java.util.Date;
import java.util.List;
import mytool.ClusterJspHelper.ClusterStatus;
import mytool.ClusterJspHelper.NamenodeStatus;
import org.apache.commons.lang.StringUtils;
import org.apache.commons.lang.time.DateFormatUtils;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.yarn.api.records.NodeReport;
import org.apache.hadoop.yarn.client.api.YarnClient;
import org.apache.hadoop.yarn.exceptions.YarnException;
public class Main {
public static void main(String[] args) {
int writedb;
YarnClient client;
ClusterStatus cs;
client = YarnClient.createYarnClient();
client.init(new Configuration());
client.start();
writedb = 0;
if (args.length == 1) {
if (args[0].equals("writedb")) {
writedb = 1;
}
} else {
System.out.println("param num is error");
return;
}
try {
printNodeStatus(client, writedb);
} catch (YarnException e) {
// TODO Auto-generated catch block
e.printStackTrace();
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
} finally {
client.stop();
System.out.println("关闭客户端");
}
cs = new ClusterJspHelper().generateClusterHealthReport();
printNameStatusInfo(cs, writedb);
}
/**
* Prints the node report for node id.
*
* @param nodeIdStr
* @throws YarnException
*/
private static void printNodeStatus(YarnClient client, int writedb)
throws YarnException, IOException {
String time;
String nodelables;
int memUsed;
int memAvail;
int vcoresUsed;
int vcoresAvail;
String[] values;
DbClient dbClient;
List<NodeReport> nodesReport = client.getNodeReports();
// Use PrintWriter.println, which uses correct platform line ending.
NodeReport nodeReport = null;
System.out.println("node num is " + nodesReport.size()
+ ", writedb is " + writedb);
dbClient = null;
if (writedb == 1) {
dbClient = new DbClient(BaseValues.DB_URL, BaseValues.DB_USER_NAME,
BaseValues.DB_PASSWORD,
BaseValues.DB_NM_REPORT_STAT_TABLE_NAME);
dbClient.createConnection();
}
for (NodeReport report : nodesReport) {
nodeReport = report;
values = new String[BaseValues.DB_COLUMN_NM_REPORT_LEN];
System.out.println("Node Report : ");
System.out.print(" Node-Id : ");
System.out.println(nodeReport.getNodeId());
values[BaseValues.DB_COLUMN_NM_REPORT_NODE_NAME] = nodeReport
.getNodeId().getHost();
System.out.print(" Rack : ");
System.out.println(nodeReport.getRackName());
values[BaseValues.DB_COLUMN_NM_REPORT_RACK] = nodeReport
.getRackName();
System.out.print(" Node-State : ");
System.out.println(nodeReport.getNodeState());
values[BaseValues.DB_COLUMN_NM_REPORT_NODE_STATE] = nodeReport
.getNodeState().toString();
System.out.print(" Node-Http-Address : ");
System.out.println(nodeReport.getHttpAddress());
values[BaseValues.DB_COLUMN_NM_REPORT_NODE_HTTP_ADDRESS] = nodeReport
.getHttpAddress();
System.out.print(" Last-Health-Update : ");
time = DateFormatUtils.format(
new Date(nodeReport.getLastHealthReportTime()),
"yyyy-MM-dd HH:mm:ss");
System.out.println(time);
values[BaseValues.DB_COLUMN_NM_REPORT_LAST_HEALTH_UPDATE] = time;
values[BaseValues.DB_COLUMN_NM_REPORT_TIME] = getCurrentTime();
System.out.print(" Health-Report : ");
System.out.println(nodeReport.getHealthReport());
values[BaseValues.DB_COLUMN_NM_REPORT_HEALTH_REPORT] = nodeReport
.getHealthReport();
System.out.print(" Containers : ");
System.out.println(nodeReport.getNumContainers());
values[BaseValues.DB_COLUMN_NM_REPORT_CONTAINERS] = String
.valueOf(nodeReport.getNumContainers());
System.out.print(" Memory-Used : ");
memUsed = (nodeReport.getUsed() == null) ? 0 : (nodeReport
.getUsed().getMemory());
System.out.println(memUsed + "MB");
values[BaseValues.DB_COLUMN_NM_REPORT_MEMORY_USED] = String
.valueOf(memUsed);
System.out.print(" Memory-Capacity : ");
System.out.println(nodeReport.getCapability().getMemory() + "MB");
memAvail = nodeReport.getCapability().getMemory() - memUsed;
values[BaseValues.DB_COLUMN_NM_REPORT_MEMORY_AVAIL] = String
.valueOf(memAvail);
System.out.print(" CPU-Used : ");
vcoresUsed = (nodeReport.getUsed() == null) ? 0 : (nodeReport
.getUsed().getVirtualCores());
System.out.println(vcoresUsed + " vcores");
values[BaseValues.DB_COLUMN_NM_REPORT_VCORES_USED] = String
.valueOf(vcoresUsed);
System.out.print(" CPU-Capacity : ");
System.out.println(nodeReport.getCapability().getVirtualCores()
+ " vcores");
vcoresAvail = nodeReport.getCapability().getVirtualCores()
- vcoresUsed;
values[BaseValues.DB_COLUMN_NM_REPORT_VCORES_AVAIL] = String
.valueOf(vcoresAvail);
System.out.print(" Node-Labels : ");
// Create a List for node labels since we need it get sorted
List<String> nodeLabelsList = new ArrayList<String>(
report.getNodeLabels());
Collections.sort(nodeLabelsList);
nodelables = StringUtils.join(nodeLabelsList.iterator(), ',');
System.out.println(nodelables);
values[BaseValues.DB_COLUMN_NM_REPORT_NODE_LABELS] = nodelables;
if (dbClient != null) {
dbClient.insertNMReportData(values);
}
}
if (nodeReport == null) {
System.out.print("Could not find the node report for node id");
}
if (dbClient != null) {
dbClient.closeConnection();
}
}
private static String getCurrentTime() {
Calendar calendar = Calendar.getInstance();
Date date = calendar.getTime();
DateFormat df = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss");
return df.format(date);
}
private static void printNameStatusInfo(ClusterStatus cs, int writedb) {
double dfsUsedPercent;
String[] values;
List<NamenodeStatus> nsList;
DbClient dbClient;
if (cs == null || cs.nnList == null) {
return;
}
dbClient = null;
if (writedb == 1) {
dbClient = new DbClient(BaseValues.DB_URL, BaseValues.DB_USER_NAME,
BaseValues.DB_PASSWORD,
BaseValues.DB_CLUSTER_STATUS_STAT_TABLE_NAME);
dbClient.createConnection();
}
nsList = cs.nnList;
for (NamenodeStatus ns : nsList) {
values = new String[BaseValues.DB_COLUMN_CLUSTER_STATUS_LEN];
dfsUsedPercent = 1.0 * ns.bpUsed / ns.capacity;
System.out.println("host:" + ns.host);
System.out.println("blocksCount:" + ns.blocksCount);
System.out.println("bpUsed:" + ns.bpUsed);
System.out.println("capacity:" + ns.capacity);
System.out.println("deadDatanodeCount:" + ns.deadDatanodeCount);
System.out.println("deadDecomCount:" + ns.deadDecomCount);
System.out.println("filesAndDirectories:" + ns.filesAndDirectories);
System.out.println("free:" + ns.free);
System.out.println("liveDatanodeCount:" + ns.liveDatanodeCount);
System.out.println("liveDecomCount:" + ns.liveDecomCount);
System.out.println("missingBlocksCount:" + ns.missingBlocksCount);
System.out.println("nonDfsUsed:" + ns.nonDfsUsed);
System.out.println("dfsUsedPercent:" + dfsUsedPercent);
System.out.println("softwareVersion:" + ns.softwareVersion);
values[BaseValues.DB_COLUMN_CLUSTER_STATUS_HOST] = String.valueOf(ns.host);
values[BaseValues.DB_COLUMN_CLUSTER_STATUS_BLOCKS_COUNT] = String.valueOf(ns.blocksCount);
values[BaseValues.DB_COLUMN_CLUSTER_STATUS_BP_USED] = String.valueOf(ns.bpUsed);
values[BaseValues.DB_COLUMN_CLUSTER_STATUS_CAPACITY] = String.valueOf(ns.capacity);
values[BaseValues.DB_COLUMN_CLUSTER_STATUS_DEAD_DN_COUNT] = String.valueOf(ns.deadDatanodeCount);
values[BaseValues.DB_COLUMN_CLUSTER_STATUS_DEAD_DECOM_COUNT] = String.valueOf(ns.deadDecomCount);
values[BaseValues.DB_COLUMN_CLUSTER_STATUS_FILES_AND_DIRS] = String.valueOf(ns.filesAndDirectories);
values[BaseValues.DB_COLUMN_CLUSTER_STATUS_FREE] = String.valueOf(ns.free);
values[BaseValues.DB_COLUMN_CLUSTER_STATUS_LIVE_DN_COUNT] = String.valueOf(ns.liveDatanodeCount);
values[BaseValues.DB_COLUMN_CLUSTER_STATUS_LIVE_DECOM_COUNT] = String.valueOf(ns.liveDecomCount);
values[BaseValues.DB_COLUMN_CLUSTER_STATUS_MISSING_BLOCKS_COUNT] = String.valueOf(ns.missingBlocksCount);
values[BaseValues.DB_COLUMN_CLUSTER_STATUS_NON_DFS_USED] = String.valueOf(ns.nonDfsUsed);
values[BaseValues.DB_COLUMN_CLUSTER_STATUS_DFS_USED_PERCENT] = String.valueOf(dfsUsedPercent);
values[BaseValues.DB_COLUMN_CLUSTER_STATUS_SOFT_WARE_VERSION] = String.valueOf(ns.softwareVersion);
values[BaseValues.DB_COLUMN_CLUSTER_STATUS_REPORT_TIME] = String.valueOf(getCurrentTime());
if(dbClient != null){
dbClient.insertCSReportData(values);
}
}
if(dbClient != null){
dbClient.closeConnection();
}
}
}
https://github.com/linyiqun/yarn-jobhistory-crawler/tree/master/NMTool
其他分析工具代码链接:
https://github.com/linyiqun/yarn-jobhistory-crawler