前言
什么是storm,storm是做什么的,一个简单的描述,你可以理解为是一个“准实时”的Hadoop,Hadoop是专门做的是离线数据处理,而storm则弥补了Hadoop在这方面的不足,他是一个实时数据处理的平台。至于Storm的各种由来,就不一一在这里废话了,之前我写的某篇文章讲述了部分的Storm的代码结构,详情点击这里。
Storm的总体架构
先来了解一下Storm的整体结构,Storm中的几个关键词Topology,Spout,Bolt,Worker,Executor,Task,暂且就这些吧。这些关键词所代表的对象是在2种节点中运行的,一个叫Nimbus节点,还有一个叫Supervisor节点,Storm采用的也是master/slave的架构,所以也会存在单点的问题。Nimbus节点和Supervisor都能快速失败并恢复,而且他们是无状态的,在其间会利用存储在Zookeeper中的元数据。在每个Supervisor节点中,可以启很多的Worker,再在每个Worker中,可以启很多的Executor执行器,每个执行器内部又会划分出许多的Task,Task是系统允许的最小单位。下面是其中的一张截图。

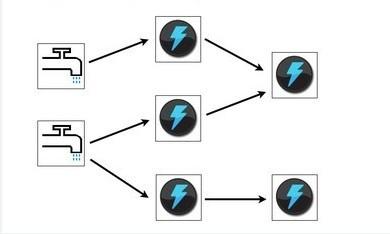
Storm的整体结构运行图如下,Spout是数据源,像水龙头一般不断的产生数据,发送到Bolt节点中执行。
Storm的元数据存储
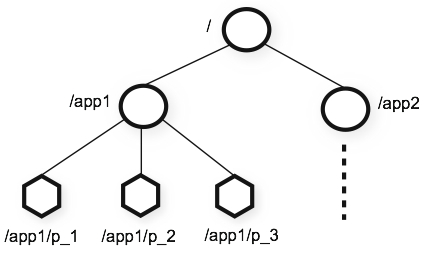
Storm采用Zookeeper来存储Nimbus,Supervisor以及内部的各个Worker之间的元数据,所以可以进行异常恢复。在Zookeeper中是如何存储的呢,答案是存在ZNode中,ZNode是一种树型结构,他有根节点,叶子节点等等,而Storm的这些数据是存在于其中的叶子节点中,最后是根据路径做区分和数据读取的。相当于是从根路径开始往下寻找,类似于Trie树的构造。下面是一张简图。
Storm的代码结构
Storm的源代码组成主要由Clojure和java2种语言来完成。Clojure在百度百科上的介绍是他是一种运行在java平台上的一种方言,而且这门语言的语法规则非常的简单,看过了Storm源码中的Clojure部分代码之后,你应该会看到许多函数式编程的痕迹。Clojure代码实现的主要功能包括Nimbus,Supervisor,worker等作业执行相关的操作,当然还有涉及到Zookeeper相关的数据交换操作等。而java部分的代码则是实现了许多的Storm的高级属性,比如Trident部分的代码,Trident是Storm对实时消息处理的更高层的抽象,我至今也还没有用过。如果是一般的作业执行,用到的核心代码其实还是用Clojure写的。