6.1 Pod控制器介绍
Pod是kubernetes的最小管理单元,在kubernetes中,按照pod的创建方式可以将其分为两类:
-
自主式pod:kubernetes直接创建出来的Pod,这种pod删除后就没有了,也不会重建
-
控制器创建的pod:kubernetes通过控制器创建的pod,这种pod删除了之后还会自动重建
什么是Pod控制器Pod控制器是管理pod的中间层,使用Pod控制器之后,只需要告诉Pod控制器,想要多少个什么样的Pod就可以了,它会创建出满足条件的Pod并确保每一个Pod资源处于用户期望的目标状态。如果Pod资源在运行中出现故障,它会基于指定策略重新编排Pod。
在kubernetes中,有很多类型的pod控制器,每种都有自己的适合的场景,常见的有下面这些:
-
ReplicationController:比较原始的pod控制器,已经被废弃,由ReplicaSet替代
-
ReplicaSet:保证副本数量一直维持在期望值,并支持pod数量扩缩容,镜像版本升级
-
Deployment:通过控制ReplicaSet来控制Pod,并支持滚动升级、回退版本
-
Horizontal Pod Autoscaler:可以根据集群负载自动水平调整Pod的数量,实现削峰填谷
-
DaemonSet:在集群中的指定Node上运行且仅运行一个副本,一般用于守护进程类的任务
-
Job:它创建出来的pod只要完成任务就立即退出,不需要重启或重建,用于执行一次性任务
-
Cronjob:它创建的Pod负责周期性任务控制,不需要持续后台运行
-
StatefulSet:管理有状态应用
6.2 ReplicaSet(RS)
ReplicaSet的主要作用是保证一定数量的pod正常运行,它会持续监听这些Pod的运行状态,一旦Pod发生故障,就会重启或重建。同时它还支持对pod数量的扩缩容和镜像版本的升降级。
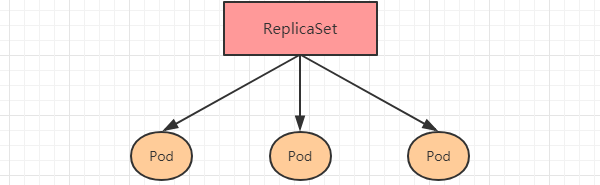
ReplicaSet的资源清单文件:
kind: ReplicaSet # 类型
metadata: # 元数据
name: # rs名称
namespace: # 所属命名空间
labels: #标签
controller: rs
spec: # 详情描述
replicas: 3 # 副本数量
selector: # 选择器,通过它指定该控制器管理哪些pod
matchLabels: # Labels匹配规则
app: nginx-pod
matchExpressions: # Expressions匹配规则
- {key: app, operator: In, values: [nginx-pod]}
template: # 模板,当副本数量不足时,会根据下面的模板创建pod副本
metadata:
labels:
app: nginx-pod
spec:
containers:
- name: nginx
image: nginx:1.17.1
ports:
- containerPort: 80
在这里面,需要新了解的配置项就是spec下面几个选项:
-
replicas:指定副本数量,其实就是当前rs创建出来的pod的数量,默认为1
-
selector:选择器,它的作用是建立pod控制器和pod之间的关联关系,采用的Label Selector机制
在pod模板上定义label,在控制器上定义选择器,就可以表明当前控制器能管理哪些pod了
-
template:模板,就是当前控制器创建pod所使用的模板板,里面其实就是前一章学过的pod的定义
创建ReplicaSet
创建pc-replicaset.yaml文件,内容如下:
kind: ReplicaSet
metadata:
name: pc-replicaset
namespace: dev
spec:
replicas: 3
selector:
matchLabels:
app: nginx-pod
template:
metadata:
labels:
app: nginx-pod
spec:
containers:
- name: nginx
image: nginx:1.17.1
[root@k8s-master01 ~]# kubectl create -f pc-replicaset.yaml
replicaset.apps/pc-replicaset created
# 查看rs
# DESIRED:期望副本数量
# CURRENT:当前副本数量
# READY:已经准备好提供服务的副本数量
[root@k8s-master01 ~]# kubectl get rs pc-replicaset -n dev -o wide
NAME DESIRED CURRENT READY AGE CONTAINERS IMAGES SELECTOR
pc-replicaset 3 3 3 22s nginx nginx:1.17.1 app=nginx-pod
# 查看当前控制器创建出来的pod
# 这里发现控制器创建出来的pod的名称是在控制器名称后面拼接了-xxxxx随机码
[root@k8s-master01 ~]# kubectl get pod -n dev
NAME READY STATUS RESTARTS AGE
pc-replicaset-6vmvt 1/1 Running 0 54s
pc-replicaset-fmb8f 1/1 Running 0 54s
pc-replicaset-snrk2 1/1 Running 0 54s
扩缩容
[root@k8s-master01 ~]# kubectl edit rs pc-replicaset -n dev
replicaset.apps/pc-replicaset edited
# 查看pod
[root@k8s-master01 ~]# kubectl get pods -n dev
NAME READY STATUS RESTARTS AGE
pc-replicaset-6vmvt 1/1 Running 0 114m
pc-replicaset-cftnp 1/1 Running 0 10s
pc-replicaset-fjlm6 1/1 Running 0 10s
pc-replicaset-fmb8f 1/1 Running 0 114m
pc-replicaset-s2whj 1/1 Running 0 10s
pc-replicaset-snrk2 1/1 Running 0 114m
# 当然也可以直接使用命令实现
# 使用scale命令实现扩缩容, 后面--replicas=n直接指定目标数量即可
[root@k8s-master01 ~]# kubectl scale rs pc-replicaset --replicas=2 -n dev
replicaset.apps/pc-replicaset scaled
# 命令运行完毕,立即查看,发现已经有4个开始准备退出了
[root@k8s-master01 ~]# kubectl get pods -n dev
NAME READY STATUS RESTARTS AGE
pc-replicaset-6vmvt 0/1 Terminating 0 118m
pc-replicaset-cftnp 0/1 Terminating 0 4m17s
pc-replicaset-fjlm6 0/1 Terminating 0 4m17s
pc-replicaset-fmb8f 1/1 Running 0 118m
pc-replicaset-s2whj 0/1 Terminating 0 4m17s
pc-replicaset-snrk2 1/1 Running 0 118m
#稍等片刻,就只剩下2个了
[root@k8s-master01 ~]# kubectl get pods -n dev
NAME READY STATUS RESTARTS AGE
pc-replicaset-fmb8f 1/1 Running 0 119m
pc-replicaset-snrk2 1/1 Running 0 119m
镜像升级
[root@k8s-master01 ~]# kubectl edit rs pc-replicaset -n dev
replicaset.apps/pc-replicaset edited
# 再次查看,发现镜像版本已经变更了
[root@k8s-master01 ~]# kubectl get rs -n dev -o wide
NAME DESIRED CURRENT READY AGE CONTAINERS IMAGES ...
pc-replicaset 2 2 2 140m nginx nginx:1.17.2 ...
# 同样的道理,也可以使用命令完成这个工作
# kubectl set image rs rs名称 容器=镜像版本 -n namespace
[root@k8s-master01 ~]# kubectl set image rs pc-replicaset nginx=nginx:1.17.1 -n dev
replicaset.apps/pc-replicaset image updated
# 再次查看,发现镜像版本已经变更了
[root@k8s-master01 ~]# kubectl get rs -n dev -o wide
NAME DESIRED CURRENT READY AGE CONTAINERS IMAGES ...
pc-replicaset 2 2 2 145m nginx nginx:1.17.1 ...
删除ReplicaSet
# 在kubernetes删除RS前,会将RS的replicasclear调整为0,等待所有的Pod被删除后,在执行RS对象的删除
[root@k8s-master01 ~]# kubectl delete rs pc-replicaset -n dev
replicaset.apps "pc-replicaset" deleted
[root@k8s-master01 ~]# kubectl get pod -n dev -o wide
No resources found in dev namespace.
# 如果希望仅仅删除RS对象(保留Pod),可以使用kubectl delete命令时添加--cascade=false选项(不推荐)。
[root@k8s-master01 ~]# kubectl delete rs pc-replicaset -n dev --cascade=false
replicaset.apps "pc-replicaset" deleted
[root@k8s-master01 ~]# kubectl get pods -n dev
NAME READY STATUS RESTARTS AGE
pc-replicaset-cl82j 1/1 Running 0 75s
pc-replicaset-dslhb 1/1 Running 0 75s
# 也可以使用yaml直接删除(推荐)
[root@k8s-master01 ~]# kubectl delete -f pc-replicaset.yaml
replicaset.apps "pc-replicaset" deleted
6.3 Deployment(Deploy)
为了更好的解决服务编排的问题,kubernetes在V1.2版本开始,引入了Deployment控制器。值得一提的是,这种控制器并不直接管理pod,而是通过管理ReplicaSet来简介管理Pod,即:Deployment管理ReplicaSet,ReplicaSet管理Pod。所以Deployment比ReplicaSet功能更加强大。

Deployment主要功能有下面几个:
-
支持ReplicaSet的所有功能
-
支持发布的停止、继续
-
支持滚动升级和回滚版本
Deployment的资源清单文件:
kind: Deployment # 类型
metadata: # 元数据
name: # rs名称
namespace: # 所属命名空间
labels: #标签
controller: deploy
spec: # 详情描述
replicas: 3 # 副本数量
revisionHistoryLimit: 3 # 保留历史版本
paused: false # 暂停部署,默认是false
progressDeadlineSeconds: 600 # 部署超时时间(s),默认是600
strategy: # 策略
type: RollingUpdate # 滚动更新策略
rollingUpdate: # 滚动更新
maxSurge: 30% # 最大额外可以存在的副本数,可以为百分比,也可以为整数
maxUnavailable: 30% # 最大不可用状态的 Pod 的最大值,可以为百分比,也可以为整数
selector: # 选择器,通过它指定该控制器管理哪些pod
matchLabels: # Labels匹配规则
app: nginx-pod
matchExpressions: # Expressions匹配规则
- {key: app, operator: In, values: [nginx-pod]}
template: # 模板,当副本数量不足时,会根据下面的模板创建pod副本
metadata:
labels:
app: nginx-pod
spec:
containers:
- name: nginx
image: nginx:1.17.1
ports:
- containerPort: 80
创建deployment
创建pc-deployment.yaml,内容如下:
kind: Deployment
metadata:
name: pc-deployment
namespace: dev
spec:
replicas: 3
selector:
matchLabels:
app: nginx-pod
template:
metadata:
labels:
app: nginx-pod
spec:
containers:
- name: nginx
image: nginx:1.17.1
[root@k8s-master01 ~]# kubectl create -f pc-deployment.yaml --record=true
deployment.apps/pc-deployment created
# 查看deployment
# UP-TO-DATE 最新版本的pod的数量
# AVAILABLE 当前可用的pod的数量
[root@k8s-master01 ~]# kubectl get deploy pc-deployment -n dev
NAME READY UP-TO-DATE AVAILABLE AGE
pc-deployment 3/3 3 3 15s
# 查看rs
# 发现rs的名称是在原来deployment的名字后面添加了一个10位数的随机串
[root@k8s-master01 ~]# kubectl get rs -n dev
NAME DESIRED CURRENT READY AGE
pc-deployment-6696798b78 3 3 3 23s
# 查看pod
[root@k8s-master01 ~]# kubectl get pods -n dev
NAME READY STATUS RESTARTS AGE
pc-deployment-6696798b78-d2c8n 1/1 Running 0 107s
pc-deployment-6696798b78-smpvp 1/1 Running 0 107s
pc-deployment-6696798b78-wvjd8 1/1 Running 0 107s
扩缩容
[root@k8s-master01 ~]# kubectl scale deploy pc-deployment --replicas=5 -n dev
deployment.apps/pc-deployment scaled
# 查看deployment
[root@k8s-master01 ~]# kubectl get deploy pc-deployment -n dev
NAME READY UP-TO-DATE AVAILABLE AGE
pc-deployment 5/5 5 5 2m
# 查看pod
[root@k8s-master01 ~]# kubectl get pods -n dev
NAME READY STATUS RESTARTS AGE
pc-deployment-6696798b78-d2c8n 1/1 Running 0 4m19s
pc-deployment-6696798b78-jxmdq 1/1 Running 0 94s
pc-deployment-6696798b78-mktqv 1/1 Running 0 93s
pc-deployment-6696798b78-smpvp 1/1 Running 0 4m19s
pc-deployment-6696798b78-wvjd8 1/1 Running 0 4m19s
# 编辑deployment的副本数量,修改spec:replicas: 4即可
[root@k8s-master01 ~]# kubectl edit deploy pc-deployment -n dev
deployment.apps/pc-deployment edited
# 查看pod
[root@k8s-master01 ~]# kubectl get pods -n dev
NAME READY STATUS RESTARTS AGE
pc-deployment-6696798b78-d2c8n 1/1 Running 0 5m23s
pc-deployment-6696798b78-jxmdq 1/1 Running 0 2m38s
pc-deployment-6696798b78-smpvp 1/1 Running 0 5m23s
pc-deployment-6696798b78-wvjd8 1/1 Running 0 5m23s
镜像更新
deployment支持两种更新策略:重建更新和滚动更新,可以通过strategy指定策略类型,支持两个属性:
type:指定策略类型,支持两种策略
Recreate:在创建出新的Pod之前会先杀掉所有已存在的Pod
RollingUpdate:滚动更新,就是杀死一部分,就启动一部分,在更新过程中,存在两个版本Pod
rollingUpdate:当type为RollingUpdate时生效,用于为RollingUpdate设置参数,支持两个属性:
maxUnavailable:用来指定在升级过程中不可用Pod的最大数量,默认为25%。
maxSurge: 用来指定在升级过程中可以超过期望的Pod的最大数量,默认为25%。
重建更新
1) 编辑pc-deployment.yaml,在spec节点下添加更新策略
strategy: # 策略
type: Recreate # 重建更新
2) 创建deploy进行验证
[root@k8s-master01 ~]# kubectl set image deployment pc-deployment nginx=nginx:1.17.2 -n dev
deployment.apps/pc-deployment image updated
# 观察升级过程
[root@k8s-master01 ~]# kubectl get pods -n dev -w
NAME READY STATUS RESTARTS AGE
pc-deployment-5d89bdfbf9-65qcw 1/1 Running 0 31s
pc-deployment-5d89bdfbf9-w5nzv 1/1 Running 0 31s
pc-deployment-5d89bdfbf9-xpt7w 1/1 Running 0 31s
pc-deployment-5d89bdfbf9-xpt7w 1/1 Terminating 0 41s
pc-deployment-5d89bdfbf9-65qcw 1/1 Terminating 0 41s
pc-deployment-5d89bdfbf9-w5nzv 1/1 Terminating 0 41s
pc-deployment-675d469f8b-grn8z 0/1 Pending 0 0s
pc-deployment-675d469f8b-hbl4v 0/1 Pending 0 0s
pc-deployment-675d469f8b-67nz2 0/1 Pending 0 0s
pc-deployment-675d469f8b-grn8z 0/1 ContainerCreating 0 0s
pc-deployment-675d469f8b-hbl4v 0/1 ContainerCreating 0 0s
pc-deployment-675d469f8b-67nz2 0/1 ContainerCreating 0 0s
pc-deployment-675d469f8b-grn8z 1/1 Running 0 1s
pc-deployment-675d469f8b-67nz2 1/1 Running 0 1s
pc-deployment-675d469f8b-hbl4v 1/1 Running 0 2s
滚动更新
1) 编辑pc-deployment.yaml,在spec节点下添加更新策略
strategy: # 策略
type: RollingUpdate # 滚动更新策略
rollingUpdate:
maxSurge: 25%
maxUnavailable: 25%
2) 创建deploy进行验证
[root@k8s-master01 ~]# kubectl set image deployment pc-deployment nginx=nginx:1.17.3 -n dev
deployment.apps/pc-deployment image updated
# 观察升级过程
[root@k8s-master01 ~]# kubectl get pods -n dev -w
NAME READY STATUS RESTARTS AGE
pc-deployment-c848d767-8rbzt 1/1 Running 0 31m
pc-deployment-c848d767-h4p68 1/1 Running 0 31m
pc-deployment-c848d767-hlmz4 1/1 Running 0 31m
pc-deployment-c848d767-rrqcn 1/1 Running 0 31m
pc-deployment-966bf7f44-226rx 0/1 Pending 0 0s
pc-deployment-966bf7f44-226rx 0/1 ContainerCreating 0 0s
pc-deployment-966bf7f44-226rx 1/1 Running 0 1s
pc-deployment-c848d767-h4p68 0/1 Terminating 0 34m
pc-deployment-966bf7f44-cnd44 0/1 Pending 0 0s
pc-deployment-966bf7f44-cnd44 0/1 ContainerCreating 0 0s
pc-deployment-966bf7f44-cnd44 1/1 Running 0 2s
pc-deployment-c848d767-hlmz4 0/1 Terminating 0 34m
pc-deployment-966bf7f44-px48p 0/1 Pending 0 0s
pc-deployment-966bf7f44-px48p 0/1 ContainerCreating 0 0s
pc-deployment-966bf7f44-px48p 1/1 Running 0 0s
pc-deployment-c848d767-8rbzt 0/1 Terminating 0 34m
pc-deployment-966bf7f44-dkmqp 0/1 Pending 0 0s
pc-deployment-966bf7f44-dkmqp 0/1 ContainerCreating 0 0s
pc-deployment-966bf7f44-dkmqp 1/1 Running 0 2s
pc-deployment-c848d767-rrqcn 0/1 Terminating 0 34m
# 至此,新版本的pod创建完毕,就版本的pod销毁完毕
# 中间过程是滚动进行的,也就是边销毁边创建
滚动更新的过程:
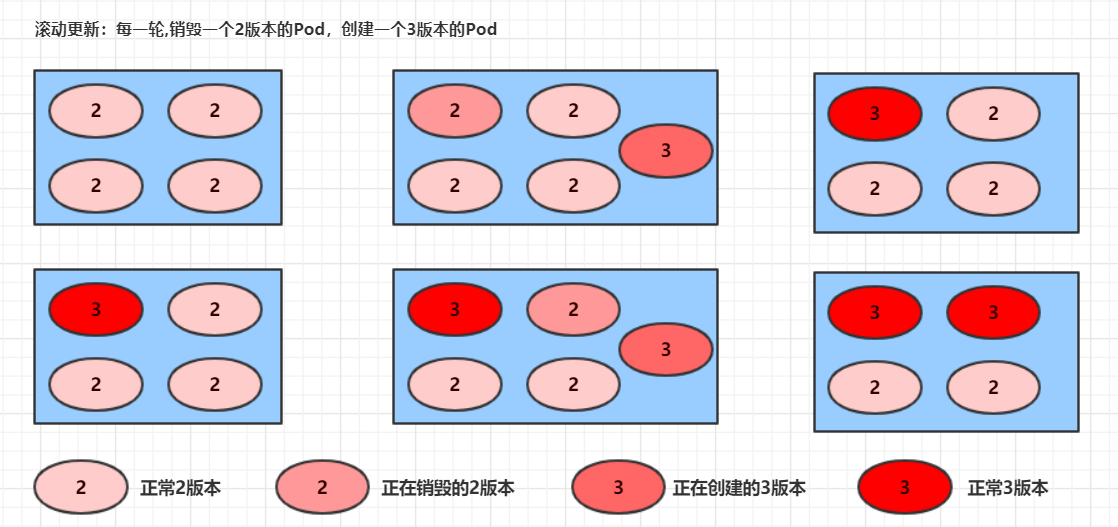
镜像更新中rs的变化:
# 其实这就是deployment能够进行版本回退的奥妙所在,后面会详细解释
[root@k8s-master01 ~]# kubectl get rs -n dev
NAME DESIRED CURRENT READY AGE
pc-deployment-6696798b78 0 0 0 7m37s
pc-deployment-6696798b11 0 0 0 5m37s
pc-deployment-c848d76789 4 4 4 72s
版本回退
deployment支持版本升级过程中的暂停、继续功能以及版本回退等诸多功能,下面具体来看.
kubectl rollout: 版本升级相关功能,支持下面的选项:
-
status 显示当前升级状态
-
history 显示 升级历史记录
-
pause 暂停版本升级过程
-
resume 继续已经暂停的版本升级过程
-
restart 重启版本升级过程
-
undo 回滚到上一级版本(可以使用--to-revision回滚到指定版本)
[root@k8s-master01 ~]# kubectl rollout status deploy pc-deployment -n dev
deployment "pc-deployment" successfully rolled out
# 查看升级历史记录
[root@k8s-master01 ~]# kubectl rollout history deploy pc-deployment -n dev
deployment.apps/pc-deployment
REVISION CHANGE-CAUSE
1 kubectl create --filename=pc-deployment.yaml --record=true
2 kubectl create --filename=pc-deployment.yaml --record=true
3 kubectl create --filename=pc-deployment.yaml --record=true
# 可以发现有三次版本记录,说明完成过两次升级
# 版本回滚
# 这里直接使用--to-revision=1回滚到了1版本, 如果省略这个选项,就是回退到上个版本,就是2版本
[root@k8s-master01 ~]# kubectl rollout undo deployment pc-deployment --to-revision=1 -n dev
deployment.apps/pc-deployment rolled back
# 查看发现,通过nginx镜像版本可以发现到了第一版
[root@k8s-master01 ~]# kubectl get deploy -n dev -o wide
NAME READY UP-TO-DATE AVAILABLE AGE CONTAINERS IMAGES
pc-deployment 4/4 4 4 74m nginx nginx:1.17.1
# 查看rs,发现第一个rs中有4个pod运行,后面两个版本的rs中pod为运行
# 其实deployment之所以可是实现版本的回滚,就是通过记录下历史rs来实现的,
# 一旦想回滚到哪个版本,只需要将当前版本pod数量降为0,然后将回滚版本的pod提升为目标数量就可以了
[root@k8s-master01 ~]# kubectl get rs -n dev
NAME DESIRED CURRENT READY AGE
pc-deployment-6696798b78 4 4 4 78m
pc-deployment-966bf7f44 0 0 0 37m
pc-deployment-c848d767 0 0 0 71m
金丝雀发布
Deployment控制器支持控制更新过程中的控制,如“暂停(pause)”或“继续(resume)”更新操作。
比如有一批新的Pod资源创建完成后立即暂停更新过程,此时,仅存在一部分新版本的应用,主体部分还是旧的版本。然后,再筛选一小部分的用户请求路由到新版本的Pod应用,继续观察能否稳定地按期望的方式运行。确定没问题之后再继续完成余下的Pod资源滚动更新,否则立即回滚更新操作。这就是所谓的金丝雀发布。
[root@k8s-master01 ~]# kubectl set image deploy pc-deployment nginx=nginx:1.17.4 -n dev && kubectl rollout pause deployment pc-deployment -n dev
deployment.apps/pc-deployment image updated
deployment.apps/pc-deployment paused
#观察更新状态
[root@k8s-master01 ~]# kubectl rollout status deploy pc-deployment -n dev
Waiting for deployment "pc-deployment" rollout to finish: 2 out of 4 new replicas have been updated...
# 监控更新的过程,可以看到已经新增了一个资源,但是并未按照预期的状态去删除一个旧的资源,就是因为使用了pause暂停命令
[root@k8s-master01 ~]# kubectl get rs -n dev -o wide
NAME DESIRED CURRENT READY AGE CONTAINERS IMAGES
pc-deployment-5d89bdfbf9 3 3 3 19m nginx nginx:1.17.1
pc-deployment-675d469f8b 0 0 0 14m nginx nginx:1.17.2
pc-deployment-6c9f56fcfb 2 2 2 3m16s nginx nginx:1.17.4
[root@k8s-master01 ~]# kubectl get pods -n dev
NAME READY STATUS RESTARTS AGE
pc-deployment-5d89bdfbf9-rj8sq 1/1 Running 0 7m33s
pc-deployment-5d89bdfbf9-ttwgg 1/1 Running 0 7m35s
pc-deployment-5d89bdfbf9-v4wvc 1/1 Running 0 7m34s
pc-deployment-6c9f56fcfb-996rt 1/1 Running 0 3m31s
pc-deployment-6c9f56fcfb-j2gtj 1/1 Running 0 3m31s
# 确保更新的pod没问题了,继续更新
[root@k8s-master01 ~]# kubectl rollout resume deploy pc-deployment -n dev
deployment.apps/pc-deployment resumed
# 查看最后的更新情况
[root@k8s-master01 ~]# kubectl get rs -n dev -o wide
NAME DESIRED CURRENT READY AGE CONTAINERS IMAGES
pc-deployment-5d89bdfbf9 0 0 0 21m nginx nginx:1.17.1
pc-deployment-675d469f8b 0 0 0 16m nginx nginx:1.17.2
pc-deployment-6c9f56fcfb 4 4 4 5m11s nginx nginx:1.17.4
[root@k8s-master01 ~]# kubectl get pods -n dev
NAME READY STATUS RESTARTS AGE
pc-deployment-6c9f56fcfb-7bfwh 1/1 Running 0 37s
pc-deployment-6c9f56fcfb-996rt 1/1 Running 0 5m27s
pc-deployment-6c9f56fcfb-j2gtj 1/1 Running 0 5m27s
pc-deployment-6c9f56fcfb-rf84v 1/1 Running 0 37s
删除Deployment
[root@k8s-master01 ~]# kubectl delete -f pc-deployment.yaml
deployment.apps "pc-deployment" deleted
6.4 Horizontal Pod Autoscaler(HPA)
在前面的课程中,我们已经可以实现通过手工执行kubectl scale命令实现Pod扩容或缩容,但是这显然不符合Kubernetes的定位目标--自动化、智能化。 Kubernetes期望可以实现通过监测Pod的使用情况,实现pod数量的自动调整,于是就产生了Horizontal Pod Autoscaler(HPA)这种控制器。
HPA可以获取每个Pod利用率,然后和HPA中定义的指标进行对比,同时计算出需要伸缩的具体值,最后实现Pod的数量的调整。其实HPA与之前的Deployment一样,也属于一种Kubernetes资源对象,它通过追踪分析RC控制的所有目标Pod的负载变化情况,来确定是否需要针对性地调整目标Pod的副本数,这是HPA的实现原理。
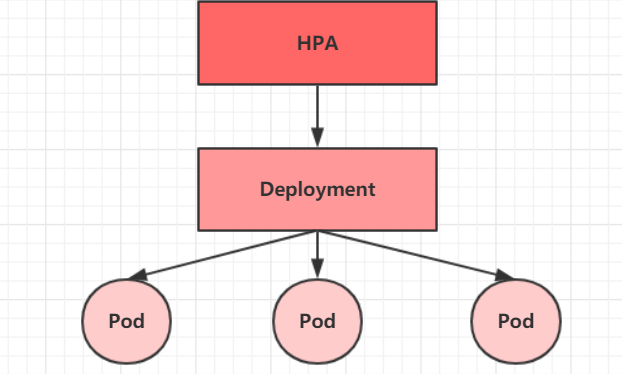
接下来,我们来做一个实验
1 安装metrics-server
metrics-server可以用来收集集群中的资源使用情况
[root@k8s-master01 ~]# yum install git -y
# 获取metrics-server, 注意使用的版本
[root@k8s-master01 ~]# git clone -b v0.3.6 https://github.com/kubernetes-incubator/metrics-server
# 修改deployment, 注意修改的是镜像和初始化参数
[root@k8s-master01 ~]# cd /root/metrics-server/deploy/1.8+/
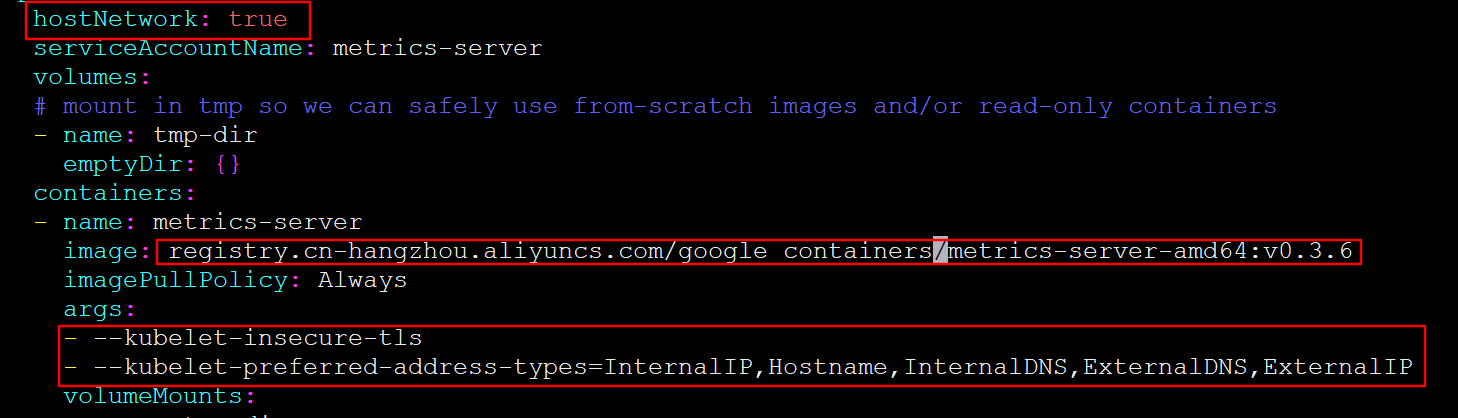
[root@k8s-master01 1.8+]# vim metrics-server-deployment.yaml
按图中添加下面选项
hostNetwork: true
image: registry.cn-hangzhou.aliyuncs.com/google_containers/metrics-server-amd64:v0.3.6
args:
- --kubelet-insecure-tls
- --kubelet-preferred-address-types=InternalIP,Hostname,InternalDNS,ExternalDNS,ExternalIP
[root@k8s-master01 1.8+]# kubectl apply -f ./
# 查看pod运行情况
[root@k8s-master01 1.8+]# kubectl get pod -n kube-system
metrics-server-6b976979db-2xwbj 1/1 Running 0 90s
# 使用kubectl top node 查看资源使用情况
[root@k8s-master01 1.8+]# kubectl top node
NAME CPU(cores) CPU% MEMORY(bytes) MEMORY%
k8s-master01 289m 14% 1582Mi 54%
k8s-node01 81m 4% 1195Mi 40%
k8s-node02 72m 3% 1211Mi 41%
[root@k8s-master01 1.8+]# kubectl top pod -n kube-system
NAME CPU(cores) MEMORY(bytes)
coredns-6955765f44-7ptsb 3m 9Mi
coredns-6955765f44-vcwr5 3m 8Mi
etcd-master 14m 145Mi
...
# 至此,metrics-server安装完成
2 准备deployment和servie
创建pc-hpa-pod.yaml文件,内容如下:
kind: Deployment
metadata:
name: nginx
namespace: dev
spec:
strategy: # 策略
type: RollingUpdate # 滚动更新策略
replicas: 1
selector:
matchLabels:
app: nginx-pod
template:
metadata:
labels:
app: nginx-pod
spec:
containers:
- name: nginx
image: nginx:1.17.1
resources: # 资源配额
limits: # 限制资源(上限)
cpu: "1" # CPU限制,单位是core数
requests: # 请求资源(下限)
cpu: "100m" # CPU限制,单位是core数
[root@k8s-master01 1.8+]# kubectl expose deployment nginx --type=NodePort --port=80 -n dev
[root@k8s-master01 1.8+]# kubectl get deployment,pod,svc -n dev
NAME READY UP-TO-DATE AVAILABLE AGE
deployment.apps/nginx 1/1 1 1 47s
NAME READY STATUS RESTARTS AGE
pod/nginx-7df9756ccc-bh8dr 1/1 Running 0 47s
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
service/nginx NodePort 10.101.18.29 <none> 80:31830/TCP 35s
3 部署HPA
创建pc-hpa.yaml文件,内容如下:
kind: HorizontalPodAutoscaler
metadata:
name: pc-hpa
namespace: dev
spec:
minReplicas: 1 #最小pod数量
maxReplicas: 10 #最大pod数量
targetCPUUtilizationPercentage: 3 # CPU使用率指标
scaleTargetRef: # 指定要控制的nginx信息
apiVersion: apps/v1
kind: Deployment
name: nginx
[root@k8s-master01 1.8+]# kubectl create -f pc-hpa.yaml
horizontalpodautoscaler.autoscaling/pc-hpa created
# 查看hpa
[root@k8s-master01 1.8+]# kubectl get hpa -n dev
NAME REFERENCE TARGETS MINPODS MAXPODS REPLICAS AGE
pc-hpa Deployment/nginx 0%/3% 1 10 1 62s
4 测试
使用压测工具对service地址192.168.5.4:31830进行压测,然后通过控制台查看hpa和pod的变化
hpa变化
NAME REFERENCE TARGETS MINPODS MAXPODS REPLICAS AGE
pc-hpa Deployment/nginx 0%/3% 1 10 1 4m11s
pc-hpa Deployment/nginx 0%/3% 1 10 1 5m19s
pc-hpa Deployment/nginx 22%/3% 1 10 1 6m50s
pc-hpa Deployment/nginx 22%/3% 1 10 4 7m5s
pc-hpa Deployment/nginx 22%/3% 1 10 8 7m21s
pc-hpa Deployment/nginx 6%/3% 1 10 8 7m51s
pc-hpa Deployment/nginx 0%/3% 1 10 8 9m6s
pc-hpa Deployment/nginx 0%/3% 1 10 8 13m
pc-hpa Deployment/nginx 0%/3% 1 10 1 14m
deployment变化
NAME READY UP-TO-DATE AVAILABLE AGE
nginx 1/1 1 1 11m
nginx 1/4 1 1 13m
nginx 1/4 1 1 13m
nginx 1/4 1 1 13m
nginx 1/4 4 1 13m
nginx 1/8 4 1 14m
nginx 1/8 4 1 14m
nginx 1/8 4 1 14m
nginx 1/8 8 1 14m
nginx 2/8 8 2 14m
nginx 3/8 8 3 14m
nginx 4/8 8 4 14m
nginx 5/8 8 5 14m
nginx 6/8 8 6 14m
nginx 7/8 8 7 14m
nginx 8/8 8 8 15m
nginx 8/1 8 8 20m
nginx 8/1 8 8 20m
nginx 1/1 1 1 20m
pod变化
NAME READY STATUS RESTARTS AGE
nginx-7df9756ccc-bh8dr 1/1 Running 0 11m
nginx-7df9756ccc-cpgrv 0/1 Pending 0 0s
nginx-7df9756ccc-8zhwk 0/1 Pending 0 0s
nginx-7df9756ccc-rr9bn 0/1 Pending 0 0s
nginx-7df9756ccc-cpgrv 0/1 ContainerCreating 0 0s
nginx-7df9756ccc-8zhwk 0/1 ContainerCreating 0 0s
nginx-7df9756ccc-rr9bn 0/1 ContainerCreating 0 0s
nginx-7df9756ccc-m9gsj 0/1 Pending 0 0s
nginx-7df9756ccc-g56qb 0/1 Pending 0 0s
nginx-7df9756ccc-sl9c6 0/1 Pending 0 0s
nginx-7df9756ccc-fgst7 0/1 Pending 0 0s
nginx-7df9756ccc-g56qb 0/1 ContainerCreating 0 0s
nginx-7df9756ccc-m9gsj 0/1 ContainerCreating 0 0s
nginx-7df9756ccc-sl9c6 0/1 ContainerCreating 0 0s
nginx-7df9756ccc-fgst7 0/1 ContainerCreating 0 0s
nginx-7df9756ccc-8zhwk 1/1 Running 0 19s
nginx-7df9756ccc-rr9bn 1/1 Running 0 30s
nginx-7df9756ccc-m9gsj 1/1 Running 0 21s
nginx-7df9756ccc-cpgrv 1/1 Running 0 47s
nginx-7df9756ccc-sl9c6 1/1 Running 0 33s
nginx-7df9756ccc-g56qb 1/1 Running 0 48s
nginx-7df9756ccc-fgst7 1/1 Running 0 66s
nginx-7df9756ccc-fgst7 1/1 Terminating 0 6m50s
nginx-7df9756ccc-8zhwk 1/1 Terminating 0 7m5s
nginx-7df9756ccc-cpgrv 1/1 Terminating 0 7m5s
nginx-7df9756ccc-g56qb 1/1 Terminating 0 6m50s
nginx-7df9756ccc-rr9bn 1/1 Terminating 0 7m5s
nginx-7df9756ccc-m9gsj 1/1 Terminating 0 6m50s
nginx-7df9756ccc-sl9c6 1/1 Terminating 0 6m50s
6.5 DaemonSet(DS)
DaemonSet类型的控制器可以保证在集群中的每一台(或指定)节点上都运行一个副本。一般适用于日志收集、节点监控等场景。也就是说,如果一个Pod提供的功能是节点级别的(每个节点都需要且只需要一个),那么这类Pod就适合使用DaemonSet类型的控制器创建。
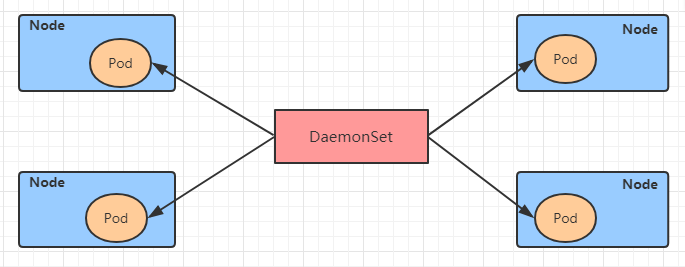
DaemonSet控制器的特点:
-
每当向集群中添加一个节点时,指定的 Pod 副本也将添加到该节点上
-
当节点从集群中移除时,Pod 也就被垃圾回收了
下面先来看下DaemonSet的资源清单文件
kind: DaemonSet # 类型
metadata: # 元数据
name: # rs名称
namespace: # 所属命名空间
labels: #标签
controller: daemonset
spec: # 详情描述
revisionHistoryLimit: 3 # 保留历史版本
updateStrategy: # 更新策略
type: RollingUpdate # 滚动更新策略
rollingUpdate: # 滚动更新
maxUnavailable: 1 # 最大不可用状态的 Pod 的最大值,可以为百分比,也可以为整数
selector: # 选择器,通过它指定该控制器管理哪些pod
matchLabels: # Labels匹配规则
app: nginx-pod
matchExpressions: # Expressions匹配规则
- {key: app, operator: In, values: [nginx-pod]}
template: # 模板,当副本数量不足时,会根据下面的模板创建pod副本
metadata:
labels:
app: nginx-pod
spec:
containers:
- name: nginx
image: nginx:1.17.1
ports:
- containerPort: 80
创建pc-daemonset.yaml,内容如下:
kind: DaemonSet
metadata:
name: pc-daemonset
namespace: dev
spec:
selector:
matchLabels:
app: nginx-pod
template:
metadata:
labels:
app: nginx-pod
spec:
containers:
- name: nginx
image: nginx:1.17.1
[root@k8s-master01 ~]# kubectl create -f pc-daemonset.yaml
daemonset.apps/pc-daemonset created
# 查看daemonset
[root@k8s-master01 ~]# kubectl get ds -n dev -o wide
NAME DESIRED CURRENT READY UP-TO-DATE AVAILABLE AGE CONTAINERS IMAGES
pc-daemonset 2 2 2 2 2 24s nginx nginx:1.17.1
# 查看pod,发现在每个Node上都运行一个pod
[root@k8s-master01 ~]# kubectl get pods -n dev -o wide
NAME READY STATUS RESTARTS AGE IP NODE
pc-daemonset-9bck8 1/1 Running 0 37s 10.244.1.43 node1
pc-daemonset-k224w 1/1 Running 0 37s 10.244.2.74 node2
# 删除daemonset
[root@k8s-master01 ~]# kubectl delete -f pc-daemonset.yaml
daemonset.apps "pc-daemonset" deleted
6.6 Job
Job,主要用于负责批量处理(一次要处理指定数量任务)短暂的一次性(每个任务仅运行一次就结束)任务。Job特点如下:
-
当Job创建的pod执行成功结束时,Job将记录成功结束的pod数量
-
当成功结束的pod达到指定的数量时,Job将完成执行
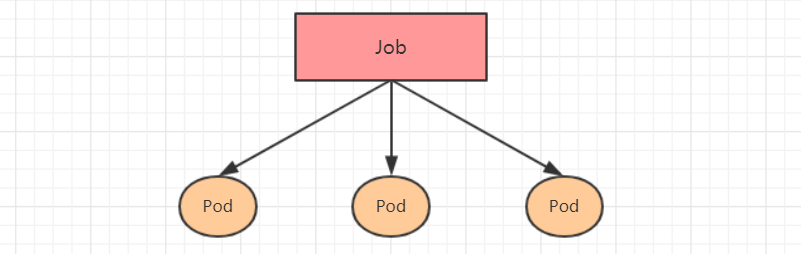
Job的资源清单文件:
kind: Job # 类型
metadata: # 元数据
name: # rs名称
namespace: # 所属命名空间
labels: #标签
controller: job
spec: # 详情描述
completions: 1 # 指定job需要成功运行Pods的次数。默认值: 1
parallelism: 1 # 指定job在任一时刻应该并发运行Pods的数量。默认值: 1
activeDeadlineSeconds: 30 # 指定job可运行的时间期限,超过时间还未结束,系统将会尝试进行终止。
backoffLimit: 6 # 指定job失败后进行重试的次数。默认是6
manualSelector: true # 是否可以使用selector选择器选择pod,默认是false
selector: # 选择器,通过它指定该控制器管理哪些pod
matchLabels: # Labels匹配规则
app: counter-pod
matchExpressions: # Expressions匹配规则
- {key: app, operator: In, values: [counter-pod]}
template: # 模板,当副本数量不足时,会根据下面的模板创建pod副本
metadata:
labels:
app: counter-pod
spec:
restartPolicy: Never # 重启策略只能设置为Never或者OnFailure
containers:
- name: counter
image: busybox:1.30
command: ["bin/sh","-c","for i in 9 8 7 6 5 4 3 2 1; do echo $i;sleep 2;done"]
如果指定为OnFailure,则job会在pod出现故障时重启容器,而不是创建pod,failed次数不变
如果指定为Never,则job会在pod出现故障时创建新的pod,并且故障pod不会消失,也不会重启,failed次数加1
如果指定为Always的话,就意味着一直重启,意味着job任务会重复去执行了,当然不对,所以不能设置为Always
创建pc-job.yaml,内容如下:
kind: Job
metadata:
name: pc-job
namespace: dev
spec:
manualSelector: true
selector:
matchLabels:
app: counter-pod
template:
metadata:
labels:
app: counter-pod
spec:
restartPolicy: Never
containers:
- name: counter
image: busybox:1.30
command: ["bin/sh","-c","for i in 9 8 7 6 5 4 3 2 1; do echo $i;sleep 3;done"]
[root@k8s-master01 ~]# kubectl create -f pc-job.yaml
job.batch/pc-job created
# 查看job
[root@k8s-master01 ~]# kubectl get job -n dev -o wide -w
NAME COMPLETIONS DURATION AGE CONTAINERS IMAGES SELECTOR
pc-job 0/1 21s 21s counter busybox:1.30 app=counter-pod
pc-job 1/1 31s 79s counter busybox:1.30 app=counter-pod
# 通过观察pod状态可以看到,pod在运行完毕任务后,就会变成Completed状态
[root@k8s-master01 ~]# kubectl get pods -n dev -w
NAME READY STATUS RESTARTS AGE
pc-job-rxg96 1/1 Running 0 29s
pc-job-rxg96 0/1 Completed 0 33s
# 接下来,调整下pod运行的总数量和并行数量 即:在spec下设置下面两个选项
# completions: 6 # 指定job需要成功运行Pods的次数为6
# parallelism: 3 # 指定job并发运行Pods的数量为3
# 然后重新运行job,观察效果,此时会发现,job会每次运行3个pod,总共执行了6个pod
[root@k8s-master01 ~]# kubectl get pods -n dev -w
NAME READY STATUS RESTARTS AGE
pc-job-684ft 1/1 Running 0 5s
pc-job-jhj49 1/1 Running 0 5s
pc-job-pfcvh 1/1 Running 0 5s
pc-job-684ft 0/1 Completed 0 11s
pc-job-v7rhr 0/1 Pending 0 0s
pc-job-v7rhr 0/1 Pending 0 0s
pc-job-v7rhr 0/1 ContainerCreating 0 0s
pc-job-jhj49 0/1 Completed 0 11s
pc-job-fhwf7 0/1 Pending 0 0s
pc-job-fhwf7 0/1 Pending 0 0s
pc-job-pfcvh 0/1 Completed 0 11s
pc-job-5vg2j 0/1 Pending 0 0s
pc-job-fhwf7 0/1 ContainerCreating 0 0s
pc-job-5vg2j 0/1 Pending 0 0s
pc-job-5vg2j 0/1 ContainerCreating 0 0s
pc-job-fhwf7 1/1 Running 0 2s
pc-job-v7rhr 1/1 Running 0 2s
pc-job-5vg2j 1/1 Running 0 3s