取范围
val conf = new SparkConf().setMaster("local").setAppName("test")
val sc = new SparkContext(conf)
val list = sc.parallelize(List(1,2,3,4,5,2,1))
val filterRdd = list.filter(_ > 3)
val newList = filterRdd.collect()
newList.foreach(println)
//结果: 4 5
去重
val dis_list = list.distinct()
// 源码: map(x => (x, null)).reduceByKey((x, y) => x).map(_._1)
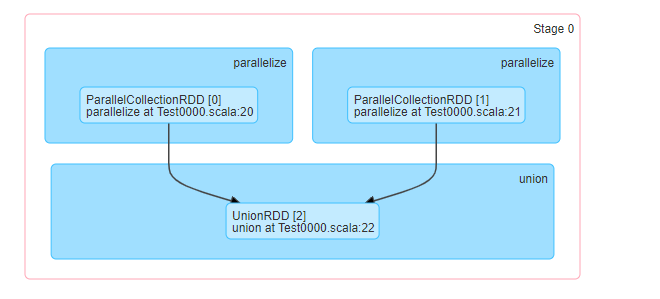
集合合并
val list01 = sc.parallelize(List(1,2)) val list02 = sc.parallelize(List(2,8)) val union = list01.union(list02) union.foreach(println)
结果: 1,2, 2,8
// 源码:new UnionRDD -> getPartitions() ->
for ((rdd, rddIndex) <- rdds.zipWithIndex; split <- rdd.partitions) {
array(pos) = new UnionPartition(pos, rdd, rddIndex, split.index)
pos += 1
}
rdds.zipWithIndex; 会将a,b,c变成(a,0)(b,1)(c,2) ->
会将 RDD1放入array(0) RDD2放入array(1)
// 依赖关系: -> getDependencies() -> RangeDependency()
println(union.partitions.size) // 2(2是因为之前创建的list在不同的分区内,所以新生成的list在两个分区内)
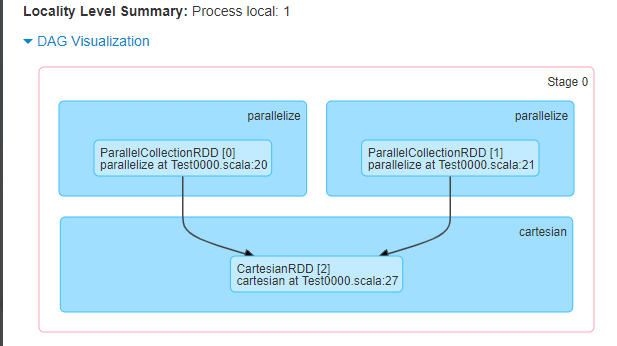
集合相乘
val list01 = sc.parallelize(List(1,2)) val list02 = sc.parallelize(List(2,8)) val cartesian = list01.cartesian(list02) println(cartesian.partitions.size) // 1 cartesian.foreach(println) 结果: (1,2) (1,8) (2,2) (2,8) // new CartesianRDD -> new NarrowDependency
println(cartesian.partitions.size) // 2(2是因为之前创建的list在不同的分区内,所以新生成的list在两个分区内)
依赖关系
1.Dependency 1.1 ShuffleDependency 1.2 NarrowDependency 1.2.1 RangeDependency 一对一 1.2.2 RangeDependency 一对多
交集
val list01 = sc.parallelize(List(1,2,3,4))
val list02 = sc.parallelize(List(4,3,5,6))
val list03 = list01.intersection(list02)
println(list03.partitions.size)
// 1
list03.foreach(println)
// 交集 结果 3 4

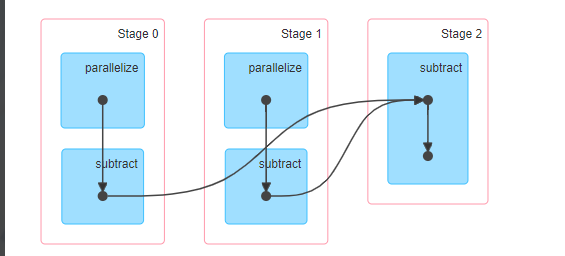
差集
val list01 = sc.parallelize(List(1,4,3,4))
val list02 = sc.parallelize(List(4,3,5,6))
// 差集
val list03 = list01.subtract(list02)
println(list03.partitions.size)
// 1
list03.foreach(println)
// 1
key不变,值合并
val list01 = sc.parallelize(List(
("zhangsan", 11),
("zhangsan", 22),
("lisi", 33),
("wangwu", 44)
))
val list02 = sc.parallelize(List(
("zhangsan", 11),
("zhangsan", 55),
("lisi", 66),
("赵六", 77)
))
val list03 = list01.cogroup(list02)
// cogroup 使用了Shuffle,规避了全量IO
/**
* 第一台: 张三、李四、王五
* 第一台: 张三、李四、赵六
* 如果不使用shuffle 第一台不分区: 那么需要把第二台数据全部拷贝过去,双层for
* 如果不使用shuffle 第一台分区:A(张三、李四) B(王五) 需要合并王五,则需要把第二台数据全量拷贝给B分区
*
* shuffle:一条一条处理
* 张三放入 A机器、
* 李四放入 B机器、
* 王五放入 C机器、
* 需要合并王五 只需处理C机器,也只需要拉取C机器即可
*
* so: shuffle 一条一条处理 ,不使用shuffle是全量数据,规避了IO
*/
list03.foreach(println)
/**
* 结果:
*
* (zhangsan,(CompactBuffer(11, 22),CompactBuffer(11, 55)))
* (wangwu,(CompactBuffer(44),CompactBuffer()))
* (赵六,(CompactBuffer(),CompactBuffer(77)))
* (lisi,(CompactBuffer(33),CompactBuffer(66)))
*/
val list03 = list01.join(list02)
list03.foreach(println)
//源码: 调用cogroup方法 在flatMapValues中(同一个key,处理value) 在双重循环(如果value有一个空,就跳过)
/**
* (zhangsan,(11,11))
* (zhangsan,(11,55))
* (zhangsan,(22,11))
* (zhangsan,(22,55))
* (lisi,(33,66))
*/
val list03 = list01.leftOuterJoin(list02)
list03.foreach(println)
/**
* if (pair._2.isEmpty) {
* pair._1.iterator.map(v => (v, None))
*
* (zhangsan,(11,Some(11)))
* (zhangsan,(11,Some(55)))
* (zhangsan,(22,Some(11)))
* (zhangsan,(22,Some(55)))
* (wangwu,(44,None))
* (lisi,(33,Some(66)))
*/
val list03 = list01.rightOuterJoin(list02)
list03.foreach(println)
/**
* (zhangsan,(Some(11),11))
* (zhangsan,(Some(11),55))
* (zhangsan,(Some(22),11))
* (zhangsan,(Some(22),55))
* (赵六,(None,77))
* (lisi,(Some(33),66))
*/
val list03 = list01.fullOuterJoin(list02)
list03.foreach(println)
/**
* (zhangsan,(Some(11),Some(11)))
* (zhangsan,(Some(11),Some(55)))
* (zhangsan,(Some(22),Some(11)))
* (zhangsan,(Some(22),Some(55)))
* (wangwu,(Some(44),None))
* (赵六,(None,Some(77)))
* (lisi,(Some(33),Some(66)))
*/