spark源码:
版本:2.3.4: https://github.com/apache/spark/tree/v2.3.4
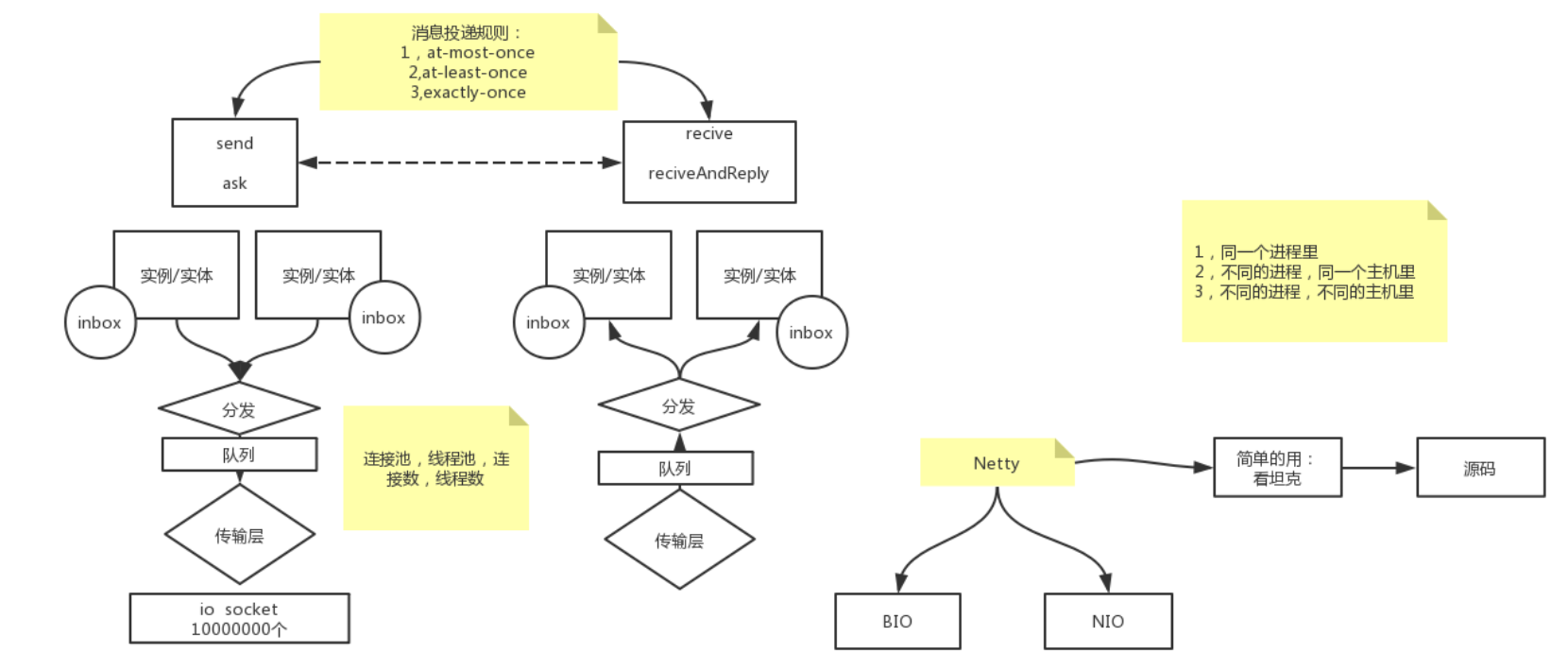
RPC:
1.解析:远程进程调用
2.:传输类型: 1.同一进程 2. 不同的进程 同一主机 3.不同的进程、不同的主机(最复杂)
实例A ---------> 实例B
3.传输方式: 实例A(有信箱,inbox,用来区别实例中的那个方法) -> 分发A(用来区别发给哪个实例) -> 队列A -> 传输层A -> 传输层B -> 分发B -> 队列B -> 实例B(有信箱,inbox)
4. 传输层最典型的是Netty, Netty底层调用了BIO或者NIO
脚本运行:
start-all.sh
- start-master.sh
- org.apache.spark.deploy.master.Master
- object Master
- main
- 1.rpcEnv.awaitTermination()一直等待,不退出,让rpc一直通信 2.startRpcEnvAndEndpoint()
- RpcEnv.create(SYSTEM_NAME, host, port, conf, securityMgr)
- create
- new NettyRpcEnvFactory().create(config)
- 看new出的 NettyRpcEnv类 private val dispatcher: Dispatcher = new Dispatcher(this, numUsableCores)(分发器) 和 nettyEnv.startServer(config.bindAddress, actualPort)(传输层)
重点- 传输层
- @volatile private var server: TransportServer = _ server = transportContext.createServer(bindAddress, port, bootstraps)(传输服务器)
- init(hostToBind, portToBind);
- 进入netty,java写的,有boss、有work, 2.NettyUtils.createEventLoop 创建线程,需要不断地处理任务,就得创建一个死循环卡主线程不退出, 3.context.initializePipeline(ch, rpcHandler);
- createChannelHandler(channel, channelRpcHandler);
- new TransportChannelHandler()
- channelRead()
- requestHandler.handle((RequestMessage) request);
- processOneWayMessage((OneWayMessage) request);
- rpcHandler.receive(reverseClient, req.body().nioByteBuffer()); 看receive方法实现类NettyRpcEnv
- dispatcher.postRemoteMessage(messageToDispatch, callback) 最终扔到了分发器中
- postMessage(message.receiver.name, rpcMessage, (e) => callback.onFailure(e))
- 1.data.inbox.post(message) 消息放进数据中的信箱 2. receivers.offer(data) 接收数据
2.分发器 - private val dispatcher: Dispatcher = new Dispatcher(this, numUsableCores)
- class Dispatcher 的receive方法
- 1.private val receivers = new LinkedBlockingQueue[EndpointData](队列) 2.ThreadPoolExecutor(pool.execute(new MessageLoop))循环处理MessageLoop 3. MessageLoop -> 1.val data = receivers.take()接收信息 2.receivers.offer(PoisonPill) 对垃圾信息投毒 3. data.inbox.process(Dispatcher.this) 装进信箱
- 传输层
- start-slaves.sh
->org.apache.spark.deploy.worker.Worker
结论: 可以看出 实例new出了一个dispatcher 和传输层的dispatcher 最终都会发送信息
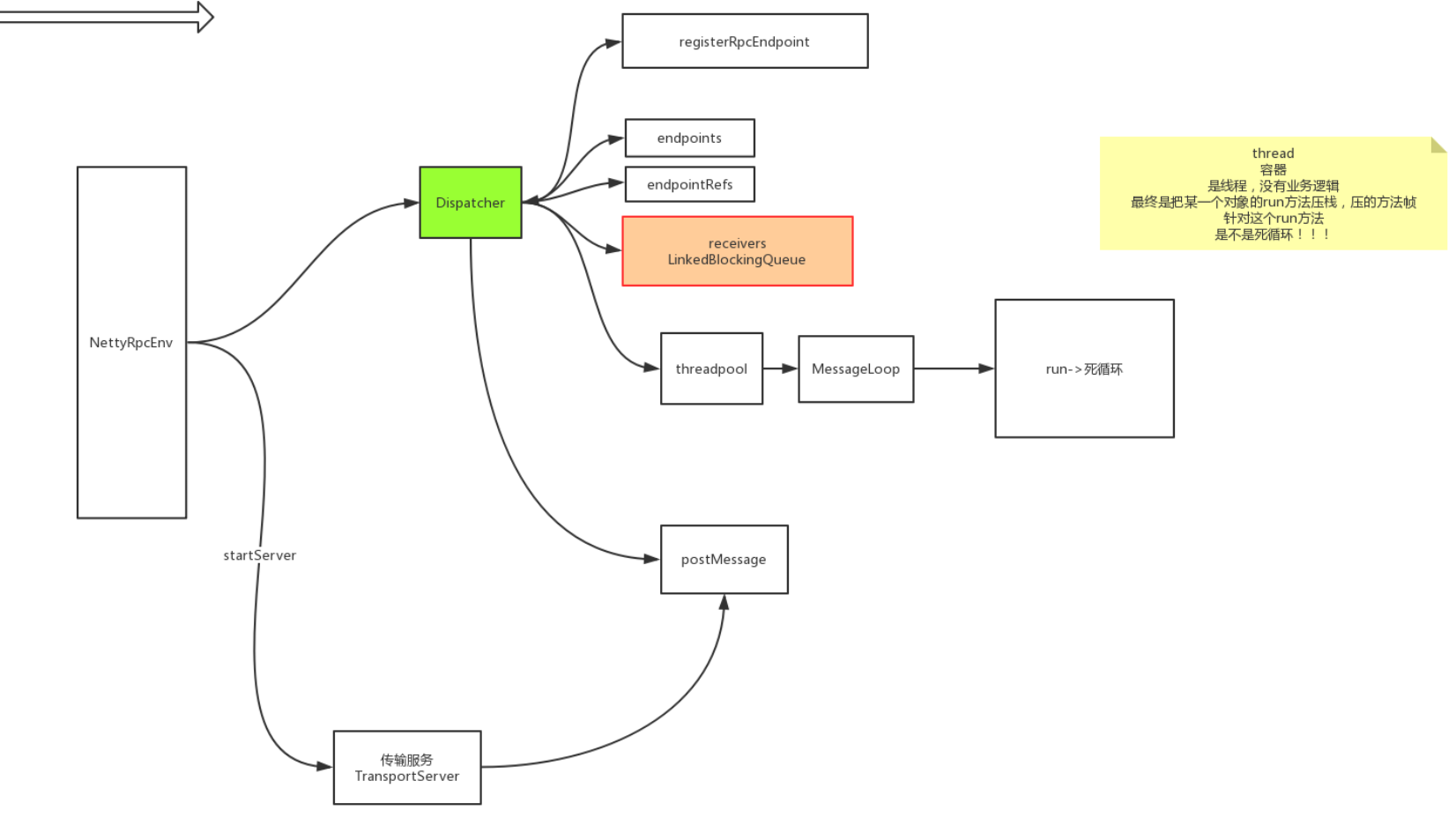
1. dispatcher 是new出来的,开始的时候会注册好服务地址、创建队列、创建死循环线程不断地把postMessage中消息放进队列中,只是初始化(new)的时候都是空的
2. TransportServer 将数据不断地放进去postMessage
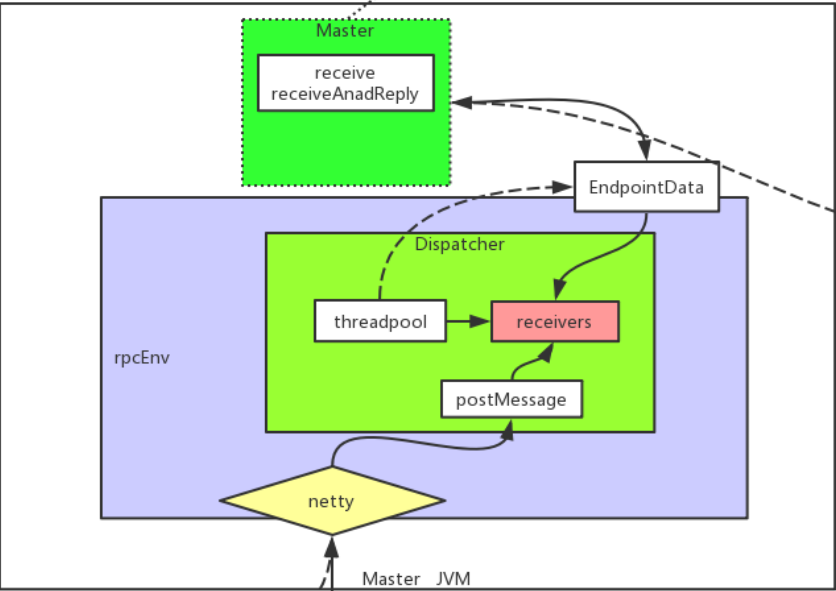
Master工作原理
-> netty 对外通信接收消息 -> postMessage -> threadpool -> receivers(receive or receiveAndReply) 线程池循环接收消息
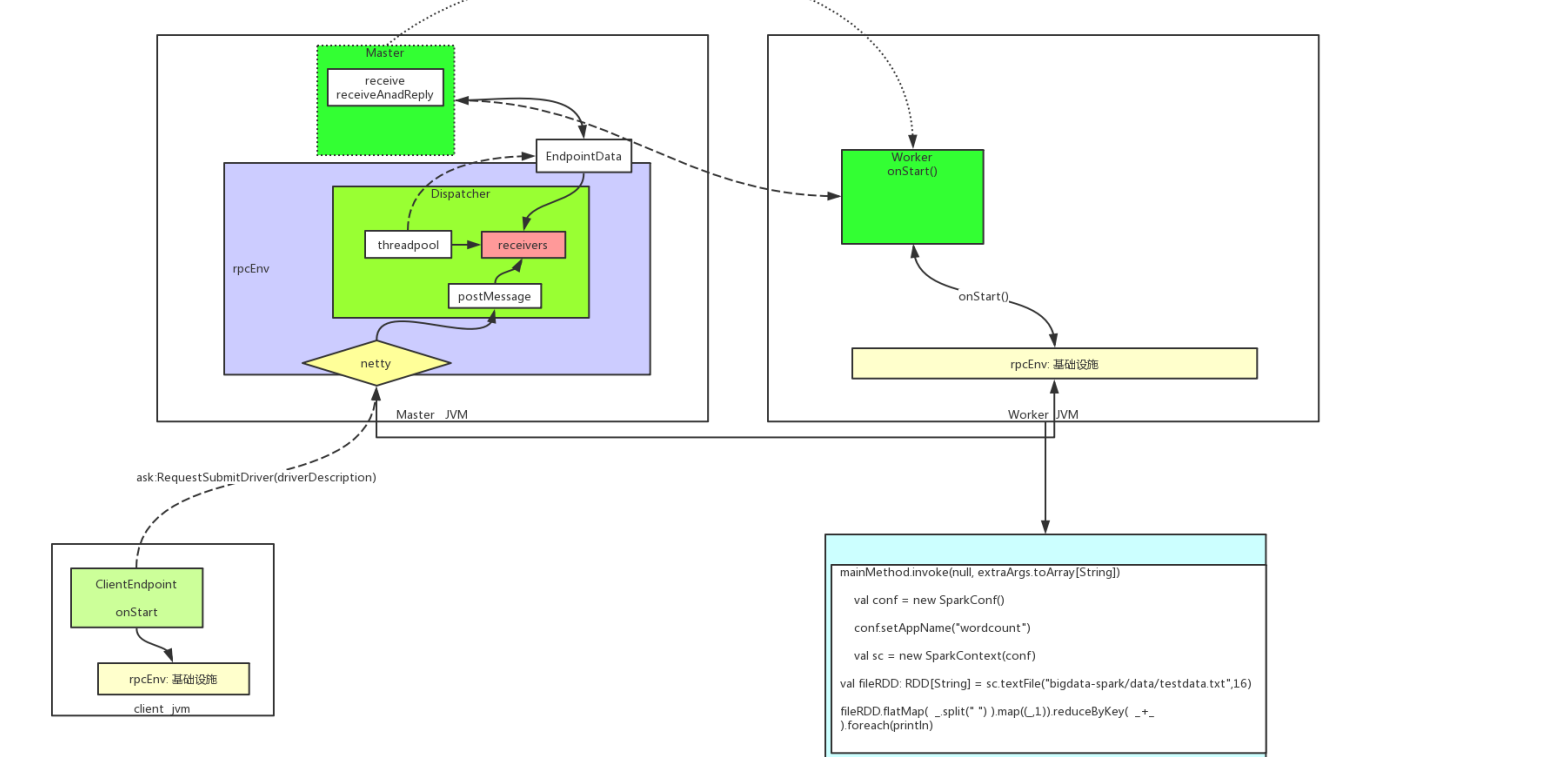
start-slaves.sh 启动的时候需要给定 ip地址 端口号
->org.apache.spark.deploy.worker.Worker
-> main
-> 1.rpcEnv.awaitTermination()不退出进程 2.startRpcEnvAndEndpoint()
-> 1. RpcEnv.create(systemName, host, port, conf, securityMgr) 走rpcEnv的思路 2.setupEndpoint()方法内的new Worker()
-> onStart()
-> registerWithMaster()
-> tryRegisterAllMasters()
-> sendRegisterMessageToMaster(masterEndpoint)
-> send()
到达 master的receive()
-> receive()
-> RegisterWorker()
-> val worker = new WorkerInfo(id, workerHost, workerPort, cores, memory,workerRef, workerWebUiUrl)获取到worker发送的信息
-> 1.registerWorker(worker) 2.workerRef.send(RegisteredWorker(self, masterWebUiUrl, masterAddress))
master又发给worker 到达worker的receive
->receive()
-> case msg: RegisterWorkerResponse => handleRegisterResponse(msg)获得注册的响应
-> self.send(SendHeartbeat)给master发送心跳
------------------------------------------------------------------------------- 以上是资源层 : master -> worker ------------------------------------------------------------------------------------------------------------------
---------------------------------- 计算层: client-> driver -> executor ---------------------------------
spark-submit 跑一个自己写的程序
-> org.apache.spark.deploy.SparkSubmit
-> main
-> case SparkSubmitAction.SUBMIT => submit(appArgs, uninitLog)
-> doRunMain()
-> runMain(args, uninitLog)
-> prepareSubmitEnvironment()获取childMainClass 下一个需要运行类 -》 childMainClass = STANDALONE_CLUSTER_SUBMIT_CLASS -》 classOf[ClientApp].getName() -> new ClientEndpoint()
-> onStart()
-> 1. val mainClass = "org.apache.spark.deploy.worker.DriverWrapper" 2. val command = new Command(mainClass,Seq("{{WORKER_URL}}", "{{USER_JAR}}", driverArgs.mainClass) ++ driverArgs.driverOptions,sys.env, classPathEntries, libraryPathEntries, javaOpts) 一个是程序的类,一个是我们的类
-> asyncSendToMasterAndForwardReply[SubmitDriverResponse](RequestSubmitDriver(driverDescription)) 我们的数据放到了driver中,driver发送给master
-> ask
-> 到达Mater的receiveAndReply()
-> 最终在worker上启动一个新进程用来跑DriverWrapper
-> 执行我们写的代码
-> sparkContext ->textFile ->hadoopRDD -> flatMap -> MappartitionsRDD -> runJob
sparkContext
-> sparkEnv
-> TaskSchedulerImpl -> initialize -> start
-> standaloneSchedulerVackend 父类 CoarseGrainedSchedulerBackend -> start
-> DAGScheduler
start
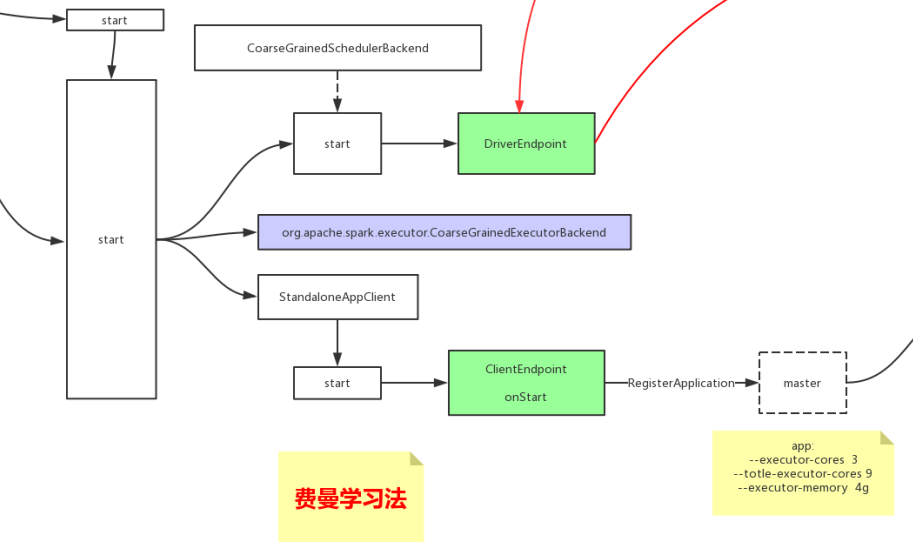
stage
相干计算 --> 需要shuffle 不相干计算 --> 组成了一个stage,在一台可以完成 ,pipeline :迭代器嵌套模式 ,窄依赖 stage与stage之间是需要shuffle的, stage划分是根据中间是否shuffle task任务 一个stage的任务task的数量是多少,是由stage里最后一个RDD的分区的数量决定的
ResultStage:最后一个stafe
ShuffleMapStage: 一个job可以有多个stage, 除了最后一个stage,其他的都是ShuffleMapStage
stage与stage之间是需要shuffle的,数据经过stage是一条一条流过的,前一个stage结束,存储IO文件,下一个stage开始从存储的IO文件开始解析
问题: spark的task是怎么来的,怎么分给executor的