Spark生态圈
spark core 批计算 取代了MR
spark streaming 流计算 取代了storm(没有自己的生态圈,所以不火)
spark sql
spark mlib 机器学习
问:spark core为什么会取代MR?spark计算速度为什么比MR快?
1. spark申请资源是粗粒度的资源申请(所有task执行完毕executor才会关闭,有利有弊,有些浪费机器资源),MR是细粒度调用,每一个task都会启动一个jvm,完事就关掉 2. Spark基于内存计算 cache persist (内存计算,pipeline操作 (怕波兰))
申请资源细粒度和粗粒度资源调用的区别以及利弊?
1.粗粒度 缺点:后台一直占用资源,端口4040 优点:只申请资源一次,跑task任务的时候不需要重新拉取,用空间换时间
2.细粒度 缺点:每次都需要申请资源,比较耗时 优点:由JVM管理,每次跑完任务,释放资源
请问map和filter如何打印
val rdd = sc.textFile("path")
val rddMap = rdd.map( x=> {
println("map" + x)
x
})
val filterRDD = rddMap.filter(x =>{
println("filter" + x)
true
})
filterRDD.count();
答:map和filter交替打印
原理: filter(map(textFile)) RDD不存数据,只存计算逻辑,里面的task每次取一条数据,管道操作,所以从文件拿一条数据打印map 在打印filter,循环交替
sparkStriming流式计算缺点
批计算 无限的缩小 微批,时间足够短就成了流计算
实时性很差
流计算默认情况下无状态
batch
有状态的计算(需要我们找地方存储)
updateStateByKey
什么是flink?
分布式有状态的计算引擎,他主要能够计算无界数据流和有界的数据流,简单来说也能批计算也能流计算
1.UnBounded streams 无界计算 有开始时间,无结束时间,比如用户日志
2.Bounded streams 有界,有开始时间,有结束时间(可以自己定时间)
3.stateful compulation state可以放内存、磁盘、state状态可以关联上下文
SparkStreaming主要是批计算,认为流计算是批计算中特殊情况,无限压榨缩小时间范围
Fink主要是流计算,默认批计算是流计算中特殊情况,要卡住结束时间就可以有界批量计算
Flink特点和优势
1. 支持高吞吐、低延迟、高性能 2. 支持事件,结合watermark处理乱序数据 3. 支持有状态计算,并且支持多种状态 可以存放到内存、文件、RocksDB 4. 支持高度灵活的窗口(window)操作 time、count、session 5. 基于轻量级分布式快照(checkpoint)实现的容错 保证exactly-once语义 6. 基于JVM实现独立的内存管理 7. Save Points(保存点) 方便代码升级
spark集群(master-slave架构)和 Fink集群 (master-slave架构)
Master:(master) 管理集群中的所有worker,进而管理了集群资源 worker:(slave) worker管理各个节点上的资源(mem core) worker_memory 1G worker_cores 2 Driver:任务调度 --executor-cores 2 JobManager(master)相当于saprk的master+driver,既负责资源调度,又负责任务调度 TaskManager(slave) 1.JobManager分发task(JobManager有多个TaskManager) 2.TaskManager向JobManager注册,通过心跳保持连接 3.TaskManager有多个slot
4.JobManager会触发checkpoint (checkpoint就是那个taskManager挂掉了,就T出去,让下一个上) 5.task slot 只对内存资源进行划分隔离,对CPU没有隔离,多个task slot共享CPU,内存是平分的 假如: TaskManager 3G 3core 则 task slot 1G 没有核
安装standalone集群
| ke01 | ke02 | ke03 | ke04 |
| JobManager | TaskManager | TaskManager | TaskManager |
1.下载链接: https://mirrors.tuna.tsinghua.edu.cn/apache/flink/flink-1.9.2/flink-1.9.2-bin-scala_2.11.tgz 2.解压:tar -zxf flink-1.9.2-bin-scala_2.11.tgz 3.修改flink-conf.yaml配置文件: 3.1 jobmanager.rpc.address: node01 JobManager地址 3.2 jobmanager.rpc.port: 6123 JobManagerRPC通信端口 3.3 jobmanager.heap.size: 1024m JobManager所能使用的堆内存大小 3.4 taskmanager.heap.size: 1024m TaskManager所能使用的堆内存大小 3.5 taskmanager.numberOfTaskSlots: 2 TaskManager管理的TaskSlot个数,依据当前物理机的核心数来配置,一般预留出一部分核心(25%)给系统及其他进程使用,一个slot对应一个core。如果core支持超线程,那么slot个数*2 3.6 rest.port: 8081 指定WebUI的访问端口 4.修改slaves配置文件 ke02 ke03 ke04 5.同步到其他节点 scp -r flink-1.9.2 ke02:`pwd` scp -r flink-1.9.2 ke03:`pwd` scp -r flink-1.9.2 ke04:`pwd` 6.配置环境 export FLINK_HOME=/opt/software/flink/flink-1.9.2 export PATH=$PATH:$FLINK_HOME/bin source /etc/profile 7.启动集群 node01上启动:start-cluster.sh
查看Flink WebUI
-
访问JobManager节点的8081端口

常用提交Application到Flink集群运行方式
(1)通过命令方式提交Application flink run -c com.msb.stream.WordCount StudyFlink-1.0-SNAPSHOT.jar -c 指定主类 -d 独立运行、后台运行 -p 指定并行度 (2)通过WebUI方式提交Application 在Web中指定Jar包的位置、主类路径、并行书等 web.submit.enable: true一定是true,否则不支持Web提交Application
本地测试
编写代码:
val env = StreamExecutionEnvironment.getExecutionEnvironment
val initStream: DataStream[String] = env.socketTextStream("192.168.75.85", 8888)
val wordStream = initStream.flatMap(_.split(" "))
val pairStream = wordStream.map((_, 1))
val keyByStream = pairStream.keyBy(0)
val restStream = keyByStream.sum(1)
restStream.print()
env.execute("first flink job")
1. ke01 : nc -lk 8888 2. 本地启动项目 3. 发送信息 4. 本地控制台有结果打印
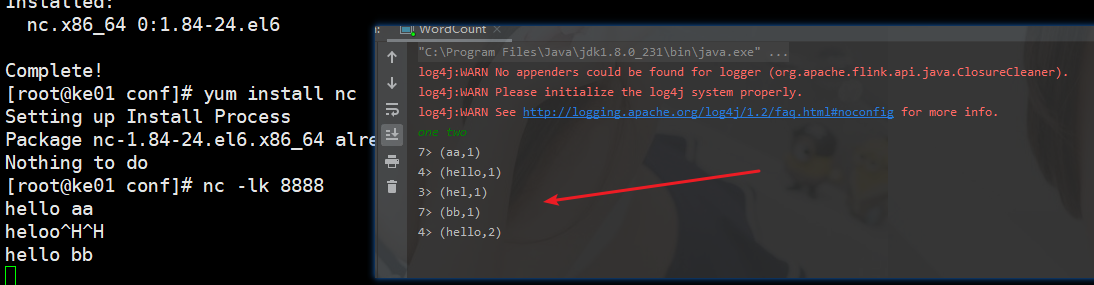
Web页面提交
1.submit new job 2.add new 3.上传jar包 4.点击jar包填写: Entry Class 5.submit 6.点击task Managers页面查看stdout,以及运行日志
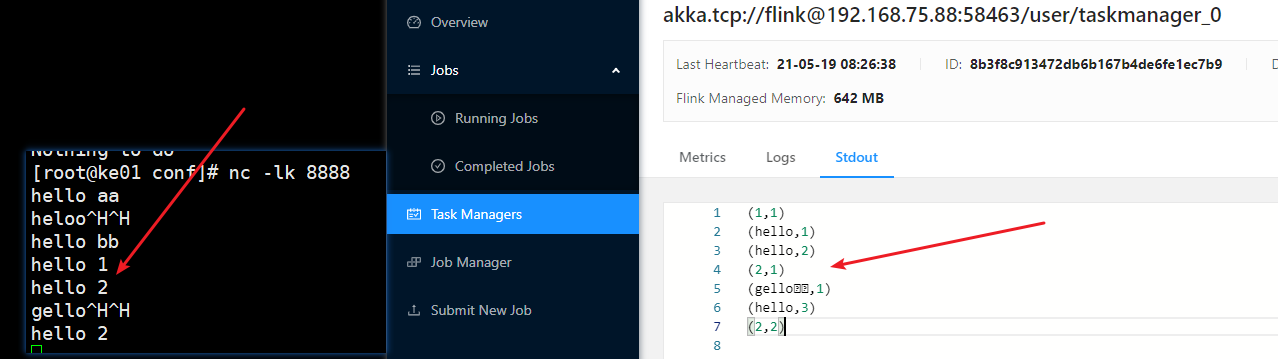
命令提交
flink run -c com.text.WordCount flink_test-1.0-SNAPSHOT.jar
Standalone HA集群安装&测试
JobManager协调每个flink任务部署,它负责调度和资源管理 默认情况下,每个flink集群只有一个JobManager,这将导致一个单点故障(SPOF single-point-offailure):如果JobManager挂了,则不能提交新的任务,并且运行中的程序也会失败。 所以搞多个JobManager,只有一个是Active,其他是Standby, 当其中一个JobManager挂掉,就会重试,如果连接不上,就是用下一个
单独启动JobManager jobmanager.sh 单独启动TaskManager taskmanager.sh
| ke01 | ke02 | ke03 | ke04 | |
| JobManager | √ | √ | ||
| TaskManager | √ | √ | √ |
1.修改配置文件 conf/flink-conf.yaml 1.1 high-availability: zookeeper 1.2 high-availability.storageDir: hdfs://ke01:8020/flink/ha/ 保存JobManager恢复所需要的所有元数据信息 1.3 high-availability.zookeeper.quorum: ke04:2181,ke02:2181,ke03:2181(zookeeper地址) 2.修改配置文件conf/masters ke01:8081 ke02:8081 3.同步到各个节点下面 4.下载支持Hadoop插件并且拷贝到各个节点的安装包的lib目录下 下载地址:https://repo.maven.apache.org/maven2/org/apache/flink/flink-shaded-hadoop-2-uber/2.6.5-10.0/flink-shaded-hadoop-2-uber-2.6.5-10.0.jar
启动:
ke01:start-cluster.sh ke02: jobmanager.sh start
stop-cluster.sh
Flink on yarn
1.client提交命令并将对应的jar和相关配置文件上传到hdfs
2.Application Master申请资源
3.RM(yarn)分配资源给JobManager
4.JobManager去hdfs下载配置和jar
5.JobManager向RM给TaskManager申请资源
6.TaskManager去HDFS下载jar和配置,开始处理任务
运行流程:
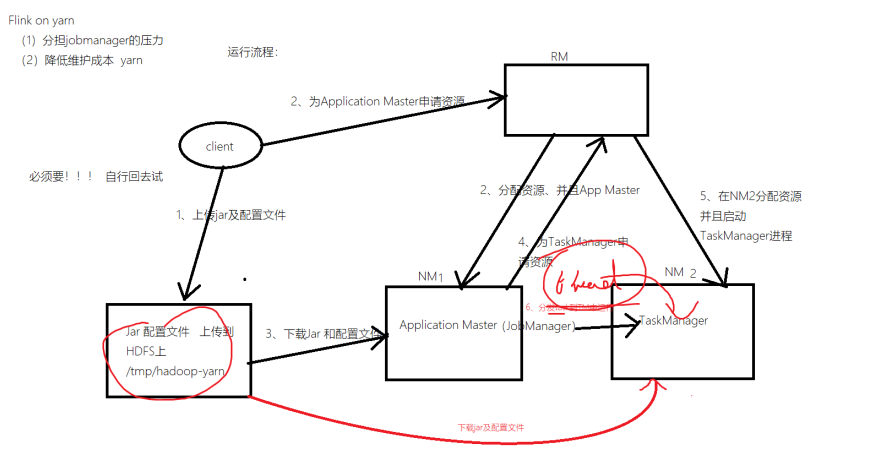
Flink on yarn两种提交方式
解脱了JobManager的压力 RM做资源管理 JobManager只负责任务管理
1.yarn seesion(Start a long-running Flink cluster on YARN)这种方式是在yarn中先启动Flink集群,然后再提交作业,这个Flink集群一直停留再yarn中,一直占据了yarn集群的资源(只是JobManager会一直占用,没有Job运行TaskManager并不会运行),不管有没有任务运行。这种方式能够降低任务的启动时间
2.Run a Flink job on YARN 每次提交一个Flink任务的时候,先去yarn中申请资源启动JobManager和TaskManager,然后在当前集群中运行,任务执行完毕,集群关闭。任务之间互相独立,互不影响,可以最大化的使用集群资源,但是每个任务的启动时间变长了
1.yarn-session(常用模式) (1)启动yarn-session集群: yarn-session.sh -n 3 -s 3 -nm flink-session -d -q -n,--container <arg>:在yarn中启动container的个数,实质就是TaskManager的个数 -s,--slots <arg>:每个TaskManager管理的Slot个数 -nm,--name <arg>:给当前的yarn-session(Flink集群)起一个名字 -d,--detached:后台独立模式启动,守护进程 -tm,--taskManagerMemory <arg>:TaskManager的内存大小 单位:MB -jm,--jobManagerMemory <arg>:JobManager的内存大小 单位:MB -q,--query:显示yarn集群可用资源(内存、core) (2)在yarn-session集群上运行项目: flink run -c com.text.WordCount -yid application_1623189129942_0005 flink_test-1.0-SNAPSHOT.jar 2.直接启动
flink run -m yarn-cluster -yn 3 -ys 3 -ynm flink-job -c com.text.WordCount flink_test-1.0-SNAPSHOT.jar
-yn,--container <arg> 表示分配容器的数量,也就是TaskManager的数量。
-d,--detached:设置在后台运行。
-yjm,--jobManagerMemory<arg>:设置JobManager的内存,单位是MB。
-ytm,--taskManagerMemory<arg>:设置每个TaskManager的内存,单位是MB。
-ynm,--name:给当前Flink application在Yarn上指定名称。
-yq,--query:显示yarn中可用的资源(内存、cpu核数)
-yqu,--queue<arg> :指定yarn资源队列
-ys,--slots<arg> :每个TaskManager使用的Slot数量。