问题:多分片下评分不准确,如何解决
因为计算评分都是在本地分片进行,并没有进行全局评分,就会造成误差较大。
目前大多解决方案是: 分片大小设置成一样的
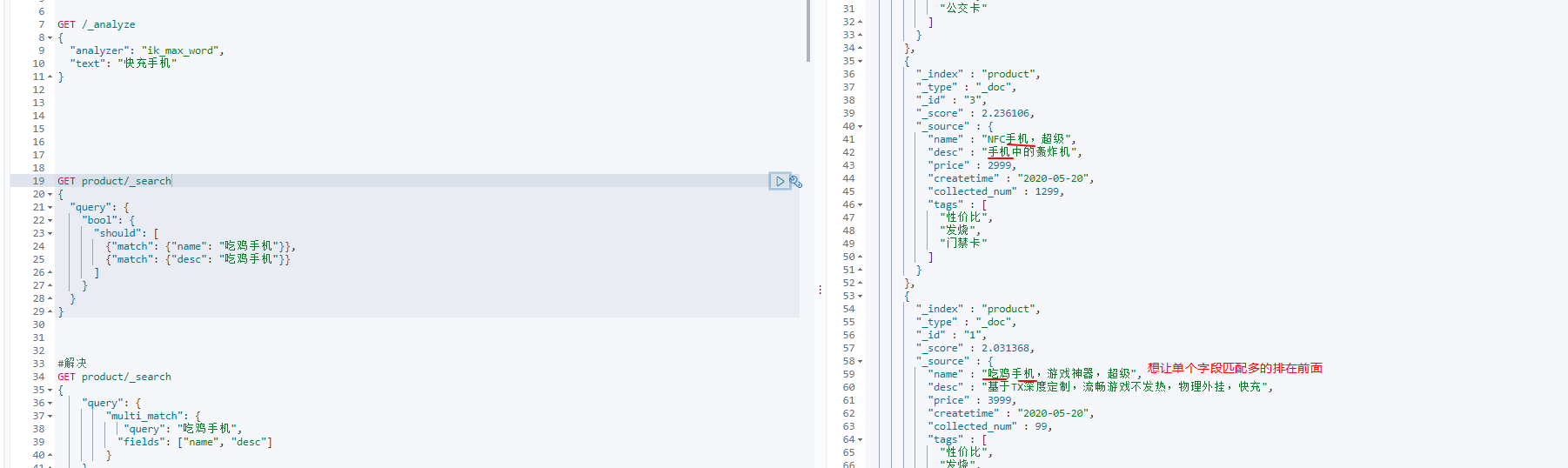
multi_match - best_fields让单个字段匹配多的排在前面
#想让单个字段匹配多的排在前面 GET product/_search { "query": { "multi_match": { "query": "吃鸡手机", "fields": ["name", "desc"] # 默认 "type": "best_fields" } } }

multi_match - most_fields多字段匹配
#使用多字段进行匹配<most_fields> GET product/_search { "query": { "multi_match": { "query": "超级快充", "fields": ["name", "desc"], "type": "most_fields" } } }
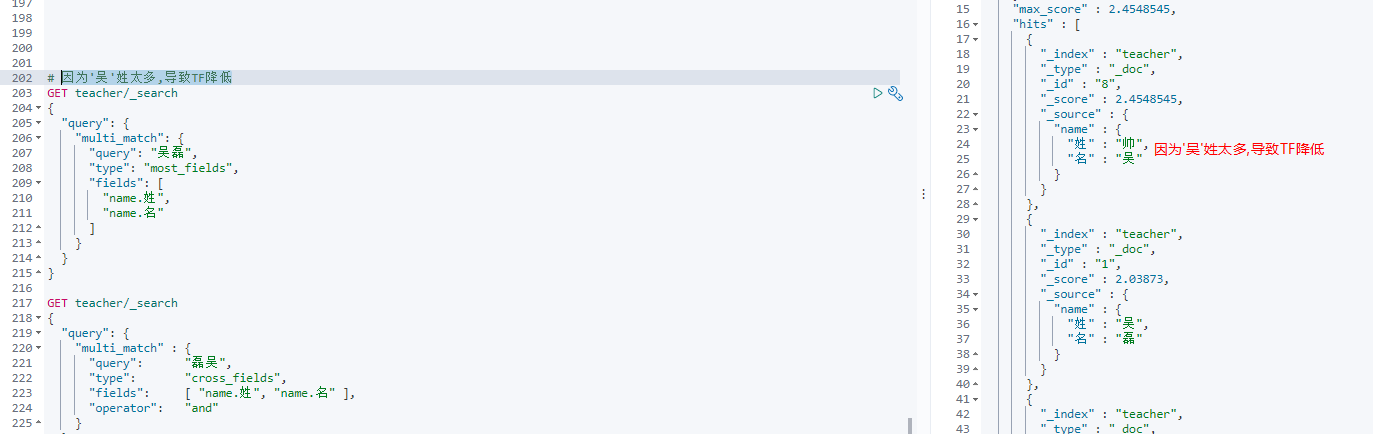
multi_match - cross_fields
#cross_fields
#如果是and 多个字段加起来是'吴磊'
#比如 姓:吴 名:磊
GET teacher/_search
{
"query": {
"multi_match" : {
"query": "磊吴",
"type": "cross_fields",
"fields": [ "name.姓", "name.名" ],
"operator": "and"
}
}
}
dis_max - tie_breaker 来调整TF 或IDF之间的比例,进而影响评分
GET product/_search { "query": { "dis_max": { "queries": [ {"match": {"name": "超级支持"}}, {"match": {"desc": "超级支持"}} ], "tie_breaker": 0.7 } } }
查询修改score
GET product/_search { "query": { "function_score": { "query": { "match_all": {} }, "field_value_factor": { "field": "collected_num", #设置字段'collected_num'为_score分数 "modifier": "log1p", # log(collected_num) "factor": 0.9 # log(collected_num)*0.9 }, "boost_mode": "multiply", log(collected_num)/0.9 "max_boost": 3 # 最大分为3,超过3的都为3 } } }
排序位置前置(广告运营)
# 1.增加一个分数字段,该字段用来设置分数 # 2.给的钱越多,该值越大 # 3.关键字需要能匹配上 # 4.计算方式: query-score * script_score GET product/_search { "query": { "function_score": { "query": { "match_all": {} }, "script_score": { "script": { "source": "Math.log(1 + doc['collected_num'].value)" } } } } }