很多场合下,我们感兴趣的试验进行了很多次,但其中成功的却发生的相当稀少。例如一个芯片的生厂商想要把生产出的芯片做一番检测后再出售。每个芯片都有一个不能正常工作的微小概率p,在数量为n的一大批芯片中,出现r个故障芯片的概率是多少?
相关阅读
二项式的泊松近似
问题似乎很简单,芯片故障的概率符合二项分布X~B(n,p),我们可以用二项分布计算出现r个故障芯片的概率:
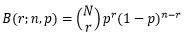
实际问题是,芯片的数量很大,但故障率又是一个很小的数值,虽然二项分布提供了一个精确的概率模型,但计算起来并不容易,而且在计算时还会丢掉大量的精度。既然这样,还不如一开始就使用一个近似式计算预期的概率。
我们首先看看全部芯片都合格(每次试验都不成功)的概率:
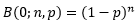
等号两边同时取对数:

接下来需要利用一点无穷级数和积分的知识:
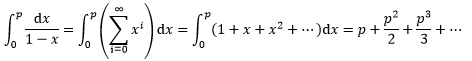
同时我们也知道∫dx/1-x的精确表达:

由此可以得到:
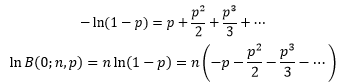
当p远远小于1,且np2远远小于1时,可以忽略p的高阶项,得到近似式:
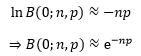
n个芯片全部合格的概率约等于e-np,出现r个故障芯片的概率又是多少呢?直接计算并不容易,幸运的是,我们可以用二项分布精确表达r个和r-1个故障芯片的概率的比值:
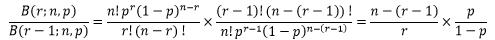
当n很大时,对于少量r个故障芯片来说,n-(r-1) ≈ n;对于很小概率p来说,p/(1-p) ≈ p,因此上式可以得到近似地表达为:
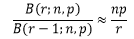
类似地,可以计算出B(r-1;n,p)/B(r-2;n,p)……直到B(1;n,p)/B(0;n,p):

这就是二项分布的泊松近似,对于给定的n和r来说,泊松分布计算起来比二项分布简单多了。泊松近似经常用P(r; λ)表示。当n很大,λ2/n(即np2)远远小于1时,泊松近似非常理想。
泊松分布
我们知道ex的泰勒展开式:
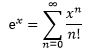
现在把r = 0,1,2,…的所有P(r; λ)相加:
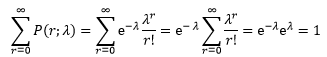
由此看出二项分布的泊松近似有一个很好的性质:r = 0,1,2,…的所有P(r; λ)之和等于1。因此可以把P(X=r; λ)用于离散型随机变量的质量函数,其中随机变量取正整数,对于每一个正实数λ,都可以指定一个泊松分布:

泊松分布记作X~Po(λ)。
二项分布产生于对同一个伯努利试验的多次重复,而泊松分布用于描述时间发生在随机的区间点(时间或空间,比如一星期或一公里)上的情形。例如某一服务设施在一定时间内到达的人数,电话交换机接到呼叫的次数,汽车站台的候客人数,机器出现的故障数,自然灾害发生的次数,一块产品上的缺陷数,显微镜下单位分区内的细菌分布数等等。假设这种事件发生在一个区间点上的可能性与发生在其他任何时间点上的可能性完全一致,而且这些事件的发生时相互独立的,那么在任何给定的单位区间内发生r个事件的概率可以由泊松分布P(X=r; λ)给出,其中随机变量X表示在给定的单位区间内发生的事件的个数,λ是事件的平均发生率(单位区间内事件发生的平均发生次数)。
泊松分布的形状取决于λ的大小,λ较小,则分布向右偏斜,随着λ的增大,分布逐渐变得对称:
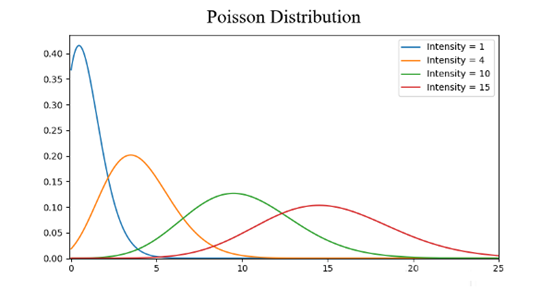
泊松分布成立的条件是λ2/n(即np2)远远小于1。我们用2个示例看看泊松分布是如何应用于实际的。
噪声数据的分布
图像的在传播过程中可能会受到某些干扰,从而使某个像素点变成了噪声。假设一个给定像素出错的概率是1/10-5,且每个像素出错相互独立的。对于一幅1000×1000的图像来说,噪声的分布是什么?
对于传播后的图像来说,每个像素不是正确就是错误,我们可以使用二项分布得到精确概率模型,但是相关的参数要么极大,要么极小,因此使用泊松近似看起来是个不错的主意。1000×1000的图像有n=106个像素,错误率是p=10-5,n和p是个悬殊的比率,λ2/n=10-4远远小于1,泊松近似将非常理想。
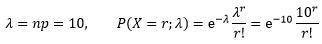
下面的代码对比了泊松分布和二项分布:
1 import numpy as np 2 import matplotlib.pyplot as plt 3 from scipy import stats 4 5 n = 10 ** 6 # 单位区间上的点 6 p = 10 ** -5 # 事件在单位区间上发生的概率 7 lam = n * p # λ = np 8 print('X ~ Po(X=r;λ)'.format(lam)) 9 10 rs = np.array(range(1, 26, 1)) # 随机变量的取值 11 # 泊松分布 X ~ Po(X=r;λ) 12 ps = stats.poisson.pmf(rs, lam) # 每个随机变量对应的概率 13 # 二项分布 X ~ B(X=r;n,p) 14 bs = stats.binom.pmf(rs, n, p) # 每个随机变量对应的概率 15 16 fig = plt.figure(figsize=(10, 4)) 17 plt.subplots_adjust(hspace=0.5) # 调整子图之间的上下边距 18 19 ax1 = fig.add_subplot(2, 2, 1) 20 ax1.set_xlabel('r') 21 ax1.set_ylabel('P(X=r;λ)'.format(lam)) 22 ax1.set_title('泊松分布') 23 ax1.bar(left=rs, height=ps, width=0.5) 24 25 ax2 = fig.add_subplot(2, 2, 2) 26 ax2.set_xlabel('r') 27 ax2.set_ylabel('P(X=r;{0},{1})'.format(n, p)) 28 ax2.set_title('二项分布') 29 ax2.bar(left=rs, height=bs, width=0.5) 30 31 ax3 = fig.add_subplot(2, 2, 3) 32 ax3.set_xlabel('r') 33 ax3.set_ylabel('泊松分布-二项分布'.format(n, p)) 34 ax3.set_title('误差') 35 ax3.bar(left=rs, height=(bs - ps), width=0.5) 36 37 plt.rcParams['font.sans-serif'] = ['SimHei'] # 用来正常显示中文标签 38 plt.rcParams['axes.unicode_minus'] = False # 解决中文下的坐标轴负号显示问题 39 plt.show() 40 41 print('最大误差', np.max(bs - ps))
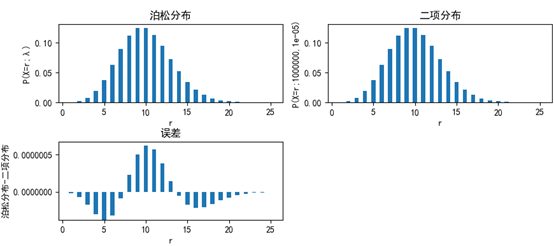
可以看到,两个分布的形状几乎相同,二者的最大误差是6.254614978717932e-07,该数值远远小于1。
程序无故障的概率
假设某个公司开有一个带伤上线的系统,每周平均的故障次数是2次,在下周不发生故障概率是多少?
泊松分布是离散概率分布,是一个描述给定的时间间隔内事件发生次数的模型,而时间是一个连续区间。面对连续区间,一个自然的选择是把区间分成n等份,每个时间小段事件发生的概率就是pn = p/n,n越大,pn越小,npn2<<1时泊松近似非常理想。当n→∞时,pn→0,此时将得到一个准确的模型。也就是说,如果事件的平均发生率是λ,那么泊松分布就是一个单位时间内事件发生的准确模型。
回到问题,每周平均的故障次数是2次,我们可以把“一周”看作单位时间,程序的故障率是λ=2,在下周不发生故障的概率相当于发生了0个故障的概率:
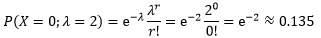
类似的例子还有很多,比如根据历史数据预测网站的访问量在1小时内达到某个值的概率;根据历史报告预测某个路段发生事故的概率。
期望和方差
泊松分布告诉我们,事件在单位区间内平均发生的次数是λ,也就是E[X]= λ。更简洁的地方在于,泊松分布的方差也是λ。
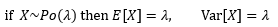
也就是说,如果给出了一个泊松分布X~Po(λ),那么你根本不用计算,它的参数就是期望和方差
出处:微信公众号 "我是8位的"
本文以学习、研究和分享为主,如需转载,请联系本人,标明作者和出处,非商业用途!
扫描二维码关注作者公众号“我是8位的”
