一、oracle执行计划
1.原理:Explain可以用来迅速方便地查出对于给定SQL语句中的查询数据是如何得到的即搜索路径(我们通常称为Access Path)。从而使我们选择最优的查询方式达到最大的优化效果。
2.使用:explain PLAN [ SET STATEMENT_ID [=] < string literal > ] [ INTO < table_name > ] FOR < sql_statement >
STATEMENT_ID:是一个唯一的字符串,把当前执行计划与存储在同一PLAN中的其它执行计划区别开来。
TABLE_NAME:是plan表名,它结构如前所示,你可以任意设定这个名称。
SQL_STATEMENT:是真正的SQL语句。
3.查看:select * from table(dbms_xplan.display);
SELECT plan_table_output FROM TABLE(DBMS_XPLAN.DISPLAY('PLAN_TABLE'));
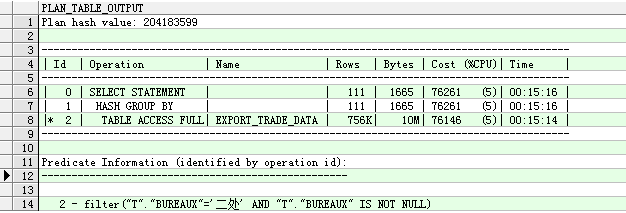
1、查看总COST,获得资源耗费的总体印象
执行计划第一行所对应的COST,反应了运行这段SQL的总体估计成本,通常COST低的执行计划要好一些。
2、 按照从左至右,从上至下的方法,了解执行计划的执行步骤
缩进最多的那一步,最先执行;结果集(对应ROWS/基数);来分析表的访问方式,连接顺序以及连接方式是否合理。
3.分析表的访问方式
表的访问方式主要是两种:全表扫描(TABLE ACCESS FULL)和索引扫描(INDEX SCAN)
4、 分析表的连接方式和连接顺序
表的连接顺序:就是以哪张表作为驱动表来连接其他表的先后访问顺序。
表的连接方式:简单来讲,就是两个表获得满足条件的数据时的连接过程。主要有三种表连接方式,嵌套循环(NESTED LOOPS)、哈希连接(HASH JOIN)和排序-合并连接(SORT MERGE JOIN)。
我们常见得是嵌套循环和哈希连接。
嵌套循环:最适用也是最简单的连接方式。类似于用两层循环处理两个游标,外层游标称作驱动表,Oracle检索驱动表的数据,一条一条的代入内层游标,查找满足WHERE条件的所有数据,因此内层游标表中可用索引的选择性越好,嵌套循环连接的性能就越高。
哈希连接:先将驱动表的数据按照条件字段以散列的方式放入内存,然后在内存中匹配满足条件的行。哈希连接需要有合适的内存,而且必须在CBO优化模式下,连接两表的WHERE条件有等号的情况下才可以使用。哈希连接在表的数据量较大,表中没有合适的索引可用时比嵌套循环的效率要高。
5、谓词说明
access("A"."EMPNO"="B"."MGR")
filter("A"."EMPNO"="B"."MGR")
filter("B"."MGR" IS NOT NULL)
Access: 表示这个谓词条件的值将会影响数据的访问路劲(表还是索引)。
Filter:表示谓词条件的值不会影响数据的访问路劲,只起过滤的作用。
在谓词中主要注意access,要考虑谓词的条件,使用的访问路径是否正确。
二、oracle索引
1、建立索引:CREATE [UNIQUE] INDEX index_name ON table_name(column_name[,column_name…])
唯一索引、普通索引 索引名称 表名 列名 单列索引、组合索引
2、索引失效:如果条件中有or,即使其中有条件带索引也不会使用(这也是为什么尽量少用or的原因)
对于多列索引,不是使用的首位索引,则不会使用索引
like查询是以%_开头(%号在前或在后都不一定走索引,和数据量有关,走不走索引说白了还是看实际情况的成本多少。)
对索引列进行运算.需要建立函数索引.
如果列类型是字符串,那一定要在条件中将数据使用引号引用起来,否则不使用索引
not in ,not exist.
B-tree索引 is null不会走,is not null会走,位图索引 is null,is not null 都会走
三、MYSQL执行计划
explain select...
explain extended select... 将执行计划“反编译”成select语句 运行show warnings可以得到被mysql优化后的查询语句
explain partitions select...用于分区表
每列含义:
1.id 执行顺序 越大越早执行
2.select_type simple、primary、subquery..有没有包括子查询,查询复杂度
3.type ALL全表、index遍历索引树、range索引范围扫描、ref非唯一索引、eq_ref唯一索引、constsystem查询被编译为常量、N
4、possinle_keys 列出可能被用的索引
5、key 实际使用的索引 TIPS覆盖索引 只用索引二没有查表
6、key_len 索引的字节数,索引的最大可能索引
7、ref 表连接匹配条件
8、rows 估算要查找的记录条数
9、Extra 附录 Using index覆盖索引、Using where用where过滤结果集、Using temporary使用临时表、Using filesort使用文件排序
四、MYSQL查询线程
show processlist;前一百条
show full processlist;全部
id:线程id
user:单列用户
host:哪个ip发起的
db列:现在连接哪个数据库
command列,显示当前连接的执行的命令,一般就是休眠(sleep),查询(query),连接(connect)
time列,此这个状态持续的时间,单位是秒
state列,显示使用当前连接的sql语句的状态
info列,显示这个sql语句
最重要的额是state列,有
这个命令中最关键的就是state列,mysql列出的状态主要有以下几种:
Checking table
正在检查数据表(这是自动的)。
Closing tables
正在将表中修改的数据刷新到磁盘中,同时正在关闭已经用完的表。这是一个很快的操作,如果不是这样的话,就应该确认磁盘空间是否已经满了或者磁盘是否正处于重负中。
Connect Out
复制从服务器正在连接主服务器。
Copying to tmp table on disk
由于临时结果集大于 tmp_table_size,正在将临时表从内存存储转为磁盘存储以此节省内存。
Creating tmp table
正在创建临时表以存放部分查询结果。
deleting from main table
服务器正在执行多表删除中的第一部分,刚删除第一个表。
deleting from reference tables
服务器正在执行多表删除中的第二部分,正在删除其他表的记录。
Flushing tables
正在执行 FLUSH TABLES,等待其他线程关闭数据表。
Killed
发送了一个kill请求给某线程,那么这个线程将会检查kill标志位,同时会放弃下一个kill请求。MySQL会在每次的主循环中检查kill标志位,不过有些情况下该线程可能会过一小段才能死掉。如果该线程程被其他线程锁住了,那么kill请求会在锁释放时马上生效。
Locked
被其他查询锁住了。
Sending data
正在处理 SELECT 查询的记录,同时正在把结果发送给客户端。
Sorting for group
正在为 GROUP BY 做排序。
Sorting for order
正在为 ORDER BY 做排序。
Opening tables
这个过程应该会很快,除非受到其他因素的干扰。例如,在执 ALTER TABLE 或 LOCK TABLE 语句行完以前,数据表无法被其他线程打开。 正尝试打开一个表。
Removing duplicates
正在执行一个 SELECT DISTINCT 方式的查询,但是MySQL无法在前一个阶段优化掉那些重复的记录。因此,MySQL需要再次去掉重复的记录,然后再把结果发送给客户端。
Reopen table
获得了对一个表的锁,但是必须在表结构修改之后才能获得这个锁。已经释放锁,关闭数据表,正尝试重新打开数据表。
Repair by sorting
修复指令正在排序以创建索引。
Repair with keycache
修复指令正在利用索引缓存一个一个地创建新索引。它会比 Repair by sorting 慢些。
Searching rows for update
正在讲符合条件的记录找出来以备更新。它必须在 UPDATE 要修改相关的记录之前就完成了。
Sleeping
正在等待客户端发送新请求.
System lock
正在等待取得一个外部的系统锁。如果当前没有运行多个 mysqld 服务器同时请求同一个表,那么可以通过增加 --skip-external-locking参数来禁止外部系统锁。
Upgrading lock
INSERT DELAYED 正在尝试取得一个锁表以插入新记录。
Updating
正在搜索匹配的记录,并且修改它们。
User Lock
正在等待 GET_LOCK()。
Waiting for tables
该线程得到通知,数据表结构已经被修改了,需要重新打开数据表以取得新的结构。然后,为了能的重新打开数据表,必须等到所有其他线程关闭这个表。以下几种情况下会产生这个通知:FLUSH
TABLES tbl_name, ALTER TABLE, RENAME TABLE, REPAIR TABLE, ANALYZE
TABLE, 或 OPTIMIZE TABLE。
waiting for handler insert
INSERT DELAYED 已经处理完了所有待处理的插入操作,正在等待新的请求