ORM API
新版本8:这章记录了Odoo 8.0中添加的新API,它应该是未来的主要开发API。它还提供了关于从版本7和更早版本的“旧API”移植或桥接的信息,但是没有显式地记录那个API。请参阅旧文档。
模型和记录的交互是通过记录集执行的,记录集是同一模型的一组排序记录。
注意
与名称所暗示的相反,目前记录集可以包含重复的内容。这种情况在未来可能会发生变化。
模型上定义的方法在记录集中执行,而它们的self是一个记录集:
class AModel(models.Model):
_name = 'a.model'
def a_method(self):
# self can be anywhere between 0 records and all records in the
# database
self.do_operation()
print self可以得到account.asset.asset(5,) 可以看出打印出了操作的记录
迭代一个记录集将产生一个单一记录(“单例”)的新集合,就像在Python字符串上迭代一样,会产生单个字符的字符串:
def do_operation(self):
print self # => a.model(1, 2, 3, 4, 5)
for record in self:
print record # => a.model(1), then a.model(2), then a.model(3), ...
字段访问
记录集提供了一个“Active Record”接口:模型字段可以作为属性直接从记录中读取和写入,但仅在单例(单记录记录集)上。字段值也可以字典集被访问,比如,对于动态字段名来说,它比getattr()更优雅、更安全。设置字段的值会触发数据库的更新:
>>> record.name
Example Name
>>> record.company_id.name
Company Name
>>> record.name = "Bob"
>>> field = "name"
>>> record[field]
Bob
尝试在多个记录上读取或写入字段会引起错误。
访问一个关联字段(Many2one, One2many, Many2many) 总是返回一个记录集,如果字段没有设置,则清空。
注意
每一次指定到一个字段都会触发一个数据库更新,当在同一时间设置多个字段或在多个记录(到相同的值)上设置字段时,使用write():
# 3 * len(records) database updates
for record in records:
record.a = 1
record.b = 2
record.c = 3
# len(records) database updates
for record in records:
record.write({'a': 1, 'b': 2, 'c': 3})
# 1 database update
records.write({'a': 1, 'b': 2, 'c': 3})
记录缓存和预取(Record cache and prefetching)
Odoo为记录的字段保留了一个缓存,因此不是每个字段访问都会发出数据库请求,这对性能来说是很糟糕的。下面的例子只针对第一个语句查询数据库:
record.name # first access reads value from database
record.name # second access gets value from cache
为了避免一次在一个记录上读取一个字段,Odoo会根据一些试探法预先获取记录和字段,以获得良好的性能。一旦一个字段必须在给定的记录上读取,ORM实际上会在较大的记录集中读取该字段,并将归还的值储存在缓存中以供以后使用。预取的记录集通常是由迭代产生的记录集。而且,所有简单的存储字段 (boolean, integer, float, char, text, date, datetime, selection, many2one)都是可以完全获取的;它们对应于model表的列,并在同一个查询中有效地获取。
考虑下面的例子,其中partners是1000 条记录的记录集。如果没有预取,循环将向数据库发出2000个查询。通过预取,只进行了一次查询:
for partner in partners:
print partner.name # first pass prefetches 'name' and 'lang'
# (and other fields) on all 'partners'
print partner.lang
预取也适用于二级记录(secondary records):当读取关系字段时,它们的值(即记录)将被订阅以备将来预取。访问这些二次记录中的一个,可以从相同的模型中获取所有的二级记录。这使得下面的示例只生成两个查询,一个用于partners ,一个用于countries:
countries = set()
for partner in partners:
country = partner.country_id # first pass prefetches all partners
countries.add(country.name) # first pass prefetches all countries
集合操作(Set operations)
记录集是不可变的,但是相同的模型集可以使用不同的set操作来组合,返回新的记录集。设置操作不保存顺序。
record in set返回中是否record(必须是一个 1-元素记录集)在集合中出现。记录不在集合中是逆操作set1<=set2和set1<set2返回set1是否是set2的子集(resp,严格的)set1 >= set2和set1 > set2返回是否set1是set2的超集(resp,严格的)set1 | set2返回两个记录集的并集,这是一个新的记录集,其中包含了两个来源的所有记录set1 & set2返回两个记录集的交集,一个新的记录集,其中只包含两个来源的记录。set1 - set2返回一个新的纪录集,其中只包含set1的记录,它不在set2中
其他记录集操作
记录集是可迭代的,所以通常的Python工具可以用于转换(map(), sorted(), itertools.ifilter, …)。然而,这些返回要么是一个列表,要么是一个迭代器,删除了在结果上调用方法的能力,或者使用set操作。
filtered()
返回一个记录集,其中只包含满足所提供的断言功能的记录。断言也可以是一个字符串,由字段为真或假来过滤:
通过条件过滤产生一个记录集
# only keep records whose company is the current user's
records.filtered(lambda r: r.company_id == user.company_id)
# only keep records whose partner is a company
records.filtered("partner_id.is_company")
sorted()
返回按所提供的key函数排序的记录集。如果没有提供key,请使用该模型的默认排序顺序:
# sort records by name
records.sorted(key=lambda r: r.name)
mapped()
将所提供的函数应用到记录集中的每个记录,如果结果是记录集,则返回一个记录集:
# returns a list of summing two fields for each record in the set
records.mapped(lambda r: r.field1 + r.field2)
所提供的函数可以是一个字符串去获取对应的字段值:
# returns a list of names
records.mapped('name')
# returns a recordset of partners
record.mapped('partner_id')
# returns the union of all partner banks, with duplicates removed
record.mapped('partner_id.bank_ids')
环境(Environment)
Environment是odoo中操作db的总句柄
Environment存储ORM所使用的各种上下文数据:数据库游标(cursor)(用于数据库查询)、当前用户(current user)(用于访问权限检查)和当前上下文(储存任意元数据)。环境也存储缓存。
引入了环境的概念,它的主要目标是提供对游标、用户、模型、上下文、记录集、和缓存的封装。
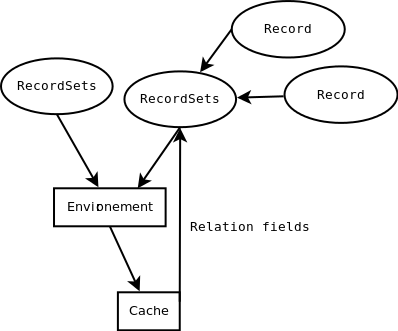
所有记录集都有一个不可变的环境,可以使用env访问,并允许访问当前用户(user)、光标(cr)或上下文(context):
>>> records.env
<Environment object ...>
>>> records.env.user
res.user(3)
>>> records.env.cr
<Cursor object ...)
实际测试打印:
print self.env
<odoo.api.Environment object at 0x7fc51e797f90>
print self.env.cr
<odoo.sql_db.Cursor object at 0x7fc51e71a410>
当从另一个记录集创建一个记录集时,环境是继承的。环境可用于在另一个模型中获得空记录集,并查询该模型:
>>> self.env['res.partner']
res.partner
>>> self.env['res.partner'].search([['is_company', '=', True], ['customer', '=', True]])
res.partner(7, 18, 12, 14, 17, 19, 8, 31, 26, 16, 13, 20, 30, 22, 29, 15, 23, 28, 74)
改变环境
可以根据记录集对环境进行定制。这将使用修改后的环境返回记录集的新版本。
sudo()
使用提供的用户集创建一个新环境,如果没有用户提供,则创建一个管理员环境(在安全的上下文中绕过访问权限/规则),新环境被调用时,返回记录集的副本:
# create partner object as administrator
env['res.partner'].sudo().create({'name': "A Partner"})
# list partners visible by the "public" user
public = env.ref('base.public_user')
env['res.partner'].sudo(public).search([])
实际测试
print self.env['account.asset.asset'].sudo().search([])
account.asset.asset(1, 2, 3, 4, 5)
public = self.env.ref('base.public_user')
print self.env['res.partner'].sudo(public).search([])
# res.partner() 感觉是env是切换表,sudo是拿指定的环境进行关联查询
print self.env.user
# res.users(1,)
with_context()
-
可以采用单个位置参数,取代当前环境的上下文
-
可以通过关键字获取任意数量的参数,这些参数被添加到当前环境的上下文或步骤1中设置的上下文环境中。
# look for partner, or create one with specified timezone if none is
# found
env['res.partner'].with_context(tz=a_tz).find_or_create(email_address)
with_env()
完全取代现有的环境
常见的ORM方法
search()
获取一个搜索域,返回一个匹配记录的记录集。可以返回匹配记录的子集(offset和limit参数)并被排序(order参数):
>>> # searches the current model
>>> self.search([('is_company', '=', True), ('customer', '=', True)])
res.partner(7, 18, 12, 14, 17, 19, 8, 31, 26, 16, 13, 20, 30, 22, 29, 15, 23, 28, 74)
>>> self.search([('is_company', '=', True)], limit=1).name
'Agrolait'
要检查任何记录是否与域相匹配,或者计算记录的数量,使用searchcount()
create()
获取许多字段值,并返回一个记录集,内含的记录被创建:
>>> self.create({'name': "New Name"})
res.partner(78)
个人测试:
print self.create({'name':'饮水机','employee_id':11,'number':'90876','serial':'az11111','device_status':'normal','category.id':1})
#报错了
management odoo.sql_db: bad query: INSERT INTO "account_asset_asset" ("id", "method_number", "employee_id", "method_progress_factor", "prorata", "company_id", "device_status", "number", "currency_id", "active", "state", "method_period", "start_date", "date", "method_time", "serial", "method", "name", "create_uid", "write_uid", "create_date", "write_date") VALUES(nextval('account_asset_asset_id_seq'), 5, 11, 0.3, false, 1, 'normal', '90876', 3, true, 'draft', 12, '2018-07-06', '2018-07-06', 'number', 'az11111', 'linear', '饮水机', 1, 1, (now() at time zone 'UTC'), (now() at time zone 'UTC')) RETURNING id
write()
获取大量的字段值,将它们写到记录集中的所有记录。不返回任何值:
self.write({'name': "Newer Name"})
browse
获取一个数据库id或一个ids列表,并返回一个记录集,当从Odoo外部获得记录id时(例如通过外部系统的往返)或在旧API中调用方法时,会很有用:
>>> self.browse([7, 18, 12])
res.partner(7, 18, 12)
exists()
返回一个新的记录集,其中只包含数据库中存在的记录。可以用来检查记录(如从外部获得的)是否仍然存在:
if not record.exists():
raise Exception("The record has been deleted")
或者在调用了一个可以删除一些记录的方法之后:
records.may_remove_some()
# only keep records which were not deleted
records = records.exists()
ref()
环境方法返回与提供的外部id匹配的记录(external id):
>>> env.ref('base.group_public')
res.groups(2)
ensure_one()
检查记录集是不是一个单例(只包含一个记录),否则会产生一个错误:
records.ensure_one()
# is equivalent to but clearer than:
assert len(records) == 1, "Expected singleton"
创建模型(Creating Models)
模型字段被定义为模型本身的属性:
from odoo import models, fields
class AModel(models.Model):
_name = 'a.model.name'
field1 = fields.Char()
警告
这意味着你不能定义一个字段和一个同名的方法,它们会冲突
默认情况下,field的标签(user-visible name)是字段名的大写版本,可以用string参数覆盖:
field2 = fields.Integer(string="an other field")
对于各种字段类型和参数,请参阅fields引用。
默认值(default)被定义为字段上的参数,或者是值:
a_field = fields.Char(default="a value")
或者调用一个函数来计算默认值,它应该返回那个值:
def compute_default_value(self):
return self.get_value()
a_field = fields.Char(default=compute_default_value)
计算字段(Computed fields)
可以使用compute参数计算字段(而不是直接从数据库读取)。它必须将计算的值分配给字段。如果它使用其他字段的值,那么它应该使用depends()来指定那些字段:
from odoo import api
total = fields.Float(compute='_compute_total')
@api.depends('value', 'tax')
def _compute_total(self):
for record in self:
record.total = record.value + record.value * record.tax
- 在使用子字段时,依赖项可以是虚线(dotted paths):(dependencies can be dotted paths when using sub-fields:)
@api.depends('line_ids.value')
def _compute_total(self):
for record in self:
record.total = sum(line.value for line in record.line_ids)
- 计算字段不是默认存储的,它们是在被请求时计算和返回的。设置
store=True会将它们存储在数据库中并自动启用搜索 - 还可以通过设置
search参数来启用计算字段。value是返回一个域的方法名:
upper_name = field.Char(compute='_compute_upper', search='_search_upper')
def _search_upper(self, operator, value):
if operator == 'like':
operator = 'ilike'
return [('name', operator, value)]
- 为了允许在计算字段上设置值,请使用
inverse参数。它是一个颠倒计算和设置相关字段的函数的名称:
document = fields.Char(compute='_get_document', inverse='_set_document')
def _get_document(self):
for record in self:
with open(record.get_document_path) as f:
record.document = f.read()
def _set_document(self):
for record in self:
if not record.document: continue
with open(record.get_document_path()) as f:
f.write(record.document)
- 多个字段可以通过相同的方法同时计算,只需在所有字段上使用相同的方法,并设置所有字段:
- @api.depends
discount_value = fields.Float(compute='_apply_discount')
total = fields.Float(compute='_apply_discount')
@depends('value', 'discount')
def _apply_discount(self):
for record in self:
# compute actual discount from discount percentage
discount = record.value * record.discount
record.discount_value = discount
record.total = record.value - discount
关联字段(Related fields)
计算字段的特殊情况是关联(代理)字段(related (proxy) fields),它提供了当前记录下子字段的值。它们的定义是设置related参数,以及它们可以存储的常规计算字段:
nickname = fields.Char(related='user_id.partner_id.name', store=True)
onchange:动态更新UI(onchange: updating UI on the fly)
当用户在表单中改变字段的值时(但还没有保存表单),根据该值自动更新其他字段可能会很有用,例如,在更改税或添加新的发票行时更新最终总数。
- 计算字段(computed fields)会自动检查和重新计算,它们不需要
onchange - 对于非计算字段,
onchange()装饰器用于提供新的字段值:
@api.onchange('field1', 'field2') # if these fields are changed, call method
def check_change(self):
if self.field1 < self.field2:
self.field3 = True
在方法期间执行的更改被发送到客户端程序,并对用户可见
- 计算字段和new-API
onchanges都是由客户端自动调用的,而无需在视图中添加它们 - 可以通过在视图中添加
onchange="0"来抑制来自特定字段的触发器:
<field name="name" on_change="0"/>
当用户编辑字段时,即使有功能字段或显式的onchange,也不会触发任何接口更新。(添加了onchange="0",不会触发字段更新)
onchange方法对这些记录的虚拟记录分配工作没有写到数据库中,只是用来了解要返回给客户的值
警告
对于一个one2many或者many2many领域来说,通过onchange来修改自身是不可能的。这是一个webclient限制-参见#2693。
低级的SQL(Low-level SQL)
环境中的cr属性是当前数据库事务的游标,并且允许直接执行SQL,或者用于难以用ORM来表达的查询(例如复杂连接),或者出于性能方面的原因:
self.env.cr.execute("some_sql", param1, param2, param3)
由于模型使用相同的游标,并且Environment 持有不同的缓存,所以当在原始SQL中更改数据库时,这些缓存必须失效,否则模型的进一步使用可能会变得不连贯。有必要在SQL中使用CREATE、UPDATE或DELETE时清除缓存,而不是SELECT(只需读取数据库即可)。
清除缓存可以使用Environment对象的invalidate_all()方法来执行。
新API与旧API之间的兼容性(Compatibility between new API and old API)
Odoo目前正从一个较老的(不是很正规的)API过渡,它可能需要手动地从一个到另一个的连接:
- RPC层(XML-RPC和JSON-RPC)都是用旧的API来表达的,纯粹在新API中表达的方法在RPC上是不可用的。
- 可覆盖的方法可以从旧的代码中调用,这些代码仍然是用旧的API样式编写的
旧的和新的api之间的巨大差异是:
Environment的值(游标、用户id和上下文)被显式地传递给方法- 记录数据(
ids)被显式地传递给方法,并且可能根本没有通过。 - 方法倾向于使用id列表而不是记录集
默认情况下,方法被假定使用新的API样式,并且不能从旧的API样式调用。
新API调用旧API的调用被桥接
当使用新的API样式时,对使用旧API定义的方法的调用会自动转换,不需要做任何特别的事情:
>>> # method in the old API style
>>> def old_method(self, cr, uid, ids, context=None):
... print ids
>>> # method in the new API style
>>> def new_method(self):
... # system automatically infers how to call the old-style
... # method from the new-style method
... self.old_method()
>>> env[model].browse([1, 2, 3, 4]).new_method()
[1, 2, 3, 4]
两个装饰器可以将一种新型的方法暴露给旧的API:
model()
该方法是在不使用ids的情况下公开的,它的记录集通常是空的。它的“旧API”签名是cr、uid、*arguments, context:
@api.model
def some_method(self, a_value):
pass
# can be called as
old_style_model.some_method(cr, uid, a_value, context=context)
multi()
这个方法被公开为获取一个ids列表(可能是空的),它的“旧API”签名是cr、uid、id、*arguments, context:
@api.multi
def some_method(self, a_value):
pass
# can be called as
old_style_model.some_method(cr, uid, [id1, id2], a_value, context=context)
因为新型的api倾向于返回记录集,而旧式的api倾向于返回ids列表,还有一个装饰器管理着:
returns()
这个函数被假定返回一个记录集,第一个参数应该是记录集的模型或self的名称(对于当前的模型)。
如果这种方法在新的API风格中被调用,则不会产生任何影响,但是当从旧的API样式调用时,将记录集转换为id列表:
>>> @api.multi
... @api.returns('self')
... def some_method(self):
... return self
>>> new_style_model = env['a.model'].browse(1, 2, 3)
>>> new_style_model.some_method()
a.model(1, 2, 3)
>>> old_style_model = pool['a.model']
>>> old_style_model.some_method(cr, uid, [1, 2, 3], context=context)
[1, 2, 3]
参考模型(Model Reference)
class odoo.models.Model(pool, cr)
用于常规数据库的主超级类。
Odoo的模型是通过继承这个类来创建的:
class user(Model):
...
该系统稍后将实例化每个数据库(安装类模块)的类。
结构属性(Structural attributes)
_name
业务对象名称,在点符号(在模块名称空间中)
_rec_name
使用名称的替代字段,osv的name _get()(默认:'name')
_inherit
如果_name被设置,则继承父模型的名称。可以是一个str如果继承了单一父节点
如果_name是未设置的,则可以将单个模型的名称扩展到该模型内
参考继承与扩展
_order
在没有指定顺序的情况下进行搜索的排序字段(默认:'id')
_auto
是否应该创建一个数据库表(默认值:
True)
如果设置为False,覆盖init()来创建数据库表
要创建一个没有任何表的模型,可以从
odoo.model.abstractmodel继承。
_table
默认情况下自动生成的模型的表的名称。
_inherits
字典将父业务对象的名称映射到要使用的相应外键字段的名称:
_inherits = {
'a.model': 'a_field_id',
'b.model': 'b_field_id'
}
实现基于组合的继承:新模型公开了_inherits模型的所有字段,但没有存储它们:这些值本身仍然存储在链接的记录中。
警告
是否同一个字段是在多个继承的基础上定义的
_constraints
定义Python约束的(constraint_function, message, fields)列表。字段列表是指示性的
自版本8:使用constrains()
_sql_constraints
列出(name, sql_definition, message)的三元组,定义SQL约束,以便在生成后备表时执行
_parent_store
除了parent_left和parent_right,设置一个嵌套集,以便在当前模型的记录上启用快速层次查询(默认为False)
Type: bool
CRUD
create(vals) → record
为模型创建一个新的记录。
新的记录使用来自于valS的值和来自default_get()的值来初始化。
参数: vals (dict) :模型字段的值,作为字典:
有关详细信息,请参write()
返回值: 新的记录被创建
Raises
AccessError –
if user has no create rights on the requested object
if user tries to bypass access rules for create on the requested object
如果用户在被请求的对象上没有创建权限
如果用户试图绕过在被请求对象上创建的访问规则
ValidateError – if user tries to enter invalid value for a field that is not in selection
如果用户试图为一个不在选择中的字段输入无效值
UserError – if a loop would be created in a hierarchy of objects a result of the operation (such as setting an object as its own parent)
如果一个循环将在对象的层次结构中创建,这是操作的结果(例如将对象设置为其母公司)
browse([ids]) → records
在当前环境中为作为参数提供的ids返回一个记录集。
不能使用任何ids、单个id或一系列ids。
unlink()
删除当前集合的记录
Raises
AccessError –
if user has no unlink rights on the requested object
if user tries to bypass access rules for unlink on the requested object
如果用户在被请求的对象上没有unlink权限
如果用户试图绕过被请求对象上的unlink的访问规则
UserError – if the record is default property for other records
如果记录是其他记录的默认属性
write(vals)
用所提供的值更新当前集合中的所有记录。
参数: vals (dict)
要更新的字段和设置的值
{'foo': 1, 'bar': "Qux"}
如果这些是有效的(否则它将触发一个错误),将把field foo设置为1,并将field bar设置为“Qux”。
Raises
AccessError –
if user has no write rights on the requested object
if user tries to bypass access rules for write on the requested object
如果用户在被请求的对象上没有写权限
如果用户试图绕过访问规则,以便在被请求的对象上书写
ValidateError – if user tries to enter invalid value for a field that is not in selection
如果用户试图为一个不在选择中的字段输入无效值
UserError – if a loop would be created in a hierarchy of objects a result of the operation (such as setting an object as its own parent)
如果一个循环将在对象的层次结构中创建,这是操作的结果(例如将对象设置为其母公司)
- 对于数字字段(
Integer, Float),值应该是对应类型的值 - 对于
Boolean来说,值应该是bool - 对于
Selection,值应该与选择值相匹配(通常是str,有时是int) - 对于
Many2one来说,值应该是设置记录的数据库标识符 - 其他非关系字段使用字符串作为值
危险
出于历史和兼容性的原因,Date和Datetime字段使用字符串作为值(书面和读取),而不是date或datetime。这些日期字符串是utc,并根据odoo.tools.misc.DEFAULT_SERVER_DATE_FORMAT和odoo.tools.misc.DEFAULT_SERVER_DATETIME_FORMAT
One2many和Many2many使用一种特殊的“命令”格式来操作与该字段相关联的一组记录。
这种格式是按顺序执行的三胞胎列表,其中每一个triplet都是在记录集上执行的命令。并不是所有的命令都适用于所有情况。可能的命令是:
(0, _, values)
添加一个从提供的value中创建的新记录。
(1, id, values)
用values的值更新id id的现有记录。不能在create()中使用。
(2, id, _)
从集合中删除id id的记录,然后删除它(来自数据库)。不能在create()中使用。
(3, id, _)
从集合中删除id id的记录,但不会删除它。不能用在One2many上。不能在create()中使用。
(4, id, _)
将id id的现有记录添加到集合中。不能在One2many上使用。
(5, _, _)
从集合中删除所有记录,相当于在每个记录上显式地使用命令3。不能用在One2many上。不能在create()中使用。
(6, _, ids)
用ids列表替换集合中所有现有的记录,相当于使用命令5,然后在ids中为每个id执行命令4。
在上面的列表中标记
_的值被忽略,可以是任何东西,通常是0或False。
read([fields])
在self、low-level/rpc方法中读取所请求的字段。在Python代码中,更喜欢browse()。
Parameters fields – list of field names to return (default is all fields)
返回的字段名列表(默认为所有字段)
Returns a list of dictionaries mapping field names to their values, with one dictionary per record
一列字典将字段名映射到它们的值,每个记录有一个字典
Raises AccessError – if user has no read rights on some of the given records
如果用户对某些记录没有读权限
read_group(domain, fields, groupby, offset=0, limit=None, orderby=False, lazy=True)
获取列表视图中的记录列表,按给定的groupby字段分组
Parameters
domain – list specifying search criteria [[‘field_name’, ‘operator’, ‘value’], …] 列表中指定搜索条件[[‘field_name’, ‘operator’, ‘value’],…]
fields (list) – list of fields present in the list view specified on the object 在对象上指定的列表视图中显示的字段列表
groupby (list) – list of groupby descriptions by which the records will be grouped. A groupby description is either a field (then it will be grouped by that field) or a string ‘field:groupby_function’. Right now, the only functions supported are ‘day’, ‘week’, ‘month’, ‘quarter’ or ‘year’, and they only make sense for date/datetime fields. 按组的描述,记录将被分组。一个群的描述要么是一个字段(然后它将被该字段分组)或一个字符串'field:groupby_function'。目前,唯一支持的功能是‘day’, ‘week’, ‘month’, ‘quarter’ or ‘year’,它们只对date/datetime字段有意义。
offset (int) – optional number of records to skip 可选的记录数量
limit (int) – optional max number of records to return 可选的最大记录数
orderby (list) – optional order by specification, for overriding the natural sort ordering of the groups, see also search() (supported only for many2one fields currently) 按规范的可选顺序,为了覆盖组的自然排序顺序,请参阅search()(目前只支持许多21个字段)
lazy (bool) – if true, the results are only grouped by the first groupby and the remaining groupbys are put in the __context key. If false, all the groupbys are done in one call.
如果是TRUE,那么结果只会被第一个groupby分组,剩下的groupbys将被放在_context键中。如果是False,所有的组都是在一个调用中完成的
Returns
list of dictionaries(one dictionary for each record) containing:
字典列表(每个记录的一个字典)包含:
the values of fields grouped by the fields in groupby argument
字段按组群分组的字段值
__domain: list of tuples specifying the search criteria 指定搜索条件的元组列表
__context: dictionary with argument like groupby 像groupby这样的参数字典
Return type :[{‘field_name_1’: value, ..]
Raises: AccessError –
if user has no read rights on the requested object
如果用户在被请求的对象上没有读权限
if user tries to bypass access rules for read on the requested object
如果用户试图绕过访问规则来读取所请求的对象
查询(Searching)
search(args[, offset=0][, limit=None][, order=None][, count=False])
搜索基于args搜索域的记录。
Parameters:
args – A search domain. Use an empty list to match all records. 一个搜索领域。使用空链表来匹配所有记录。
offset (int) – number of results to ignore (default: none)
忽略的结果数(默认值:none)
limit (int) – maximum number of records to return (default: all) 要返回的记录的最大数目(默认值:all)
order (str) – sort string 排序字符串
count (bool) – if True, only counts and returns the number of matching records (default: False) 如果是True,只计算并返回匹配记录的数量(默认:False)
Returns: at most limit records matching the search criteria 在大多数限制与搜索条件匹配的记录
Raises: AccessError –
if user tries to bypass access rules for read on the requested object. 如果用户试图绕过访问规则,以便在被请求的对象上阅读。
search_count(args) → int
如果用户试图绕过访问规则,以便在被请求的对象上阅读。
name_search(name='', args=None, operator='ilike', limit=100) → records
与给定的operator相比,搜索具有与给定name模式匹配的显示名称的记录,同时还匹配可选搜索域(args)。
例如,它用于提供基于关系字段的部分值的建议。有时被看作是name_get()的逆函数,但它不能保证是。
这个方法相当于调用search(),它的搜索域基于display_name,然后在搜索结果上的name_get()。
Parameters:
name (str) – the name pattern to match 匹配的名称模式
args (list) – optional search domain (see search() for syntax), specifying further restrictions 可选的搜索域(参见search()语法),指定进一步的限制
operator (str) – domain operator for matching name, such as 'like' or '='. 域名操作符匹配名称,如“like”或“=”。
limit (int) – optional max number of records to return 可选的最大记录数
Return type: list 列表
Returns: list of pairs (id, text_repr) for all matching records.所有匹配记录的成对列表(id,text_repr)。
记录集操作(Recordset operations)
ids
在这个记录集中的实际记录ids列表(忽略记录创建的占位符ids)
ensure_one()
验证当前记录集保存单个记录。提出了一个例外。
exists() → records
返回存在的self记录的子集,并在缓存中标记删除记录。它可以作为记录的测试:
if record.exists():
...
按照惯例,新的记录将作为现有的记录返回。
filtered(func)
选择self的记录,这样func(rec)是正确的,并将它们作为记录集返回。
Parameters: func – a function or a dot-separated sequence of field names
一个函数或一个点分隔的字段名序列
sorted(key=None, reverse=False)
返回按key排序的记录集self。
Parameters:
key – either a function of one argument that returns a comparison key for each record, or a field name, or None, in which case records are ordered according the default model’s order 要么是一个参数的函数,它返回每个记录的比较key,或者一个字段名,或者为None,在这种情况下,根据默认模型的顺序排列记录
reverse – if True, return the result in reverse order 如果是真的,则以相反的顺序返回结果
mapped(func)
将func应用于self的所有记录,并将结果作为列表或记录集返回(如果func返回记录集)。在后一种情况下,返还记录集的顺序是任意的。
Parameters func – a function or a dot-separated sequence of field names (string); any falsy value simply returns the recordset
self
一个函数或一个点分隔的字段名称序列(字符串);任何falsy的值都只返回记录集的“self”
环境切换(Environment swapping)
sudo([user=SUPERUSER])
返回给所提供的用户的这个记录集的新版本。
默认情况下,这会返回一个超级用户SUPERUSER记录集,其中访问控制和记录规则被忽略。
使用
sudo可能导致数据访问跨越记录规则的边界,可能混合了被隔离的记录(例如,在多公司环境中来自不同公司的记录)。
它可能会导致不直观的结果,在许多方法中选择一个记录——例如,获得默认的公司,或者选择一个材料清单。
with_context([context][, **overrides]) → records
返回一个附加到扩展上下文的记录集的新版本。
扩展的context要么提供的overrides的context被合并,要么当前context被overrides的被合并,例如:
# current context is {'key1': True}
r2 = records.with_context({}, key2=True)
# -> r2._context is {'key2': True}
r2 = records.with_context(key2=True)
# -> r2._context is {'key1': True, 'key2': True}
with_env(env)
返回一个附加到所提供环境的新版本的记录集
警告
新环境不会从当前环境的数据缓存中受益,因此以后的数据访问可能会在从数据库重新取回时产生额外的延迟。返回的记录集具有与self相同的预取对象。
- 个人注记:切换环境就是放弃原来的缓存数据,因为odoo访问数据库,访问一次后会存储缓存,切换环境为了避免原来的缓存
字段和视图查询(Fields and views querying)
fields_get([fields][, attributes])
返回每个字段的定义。
返回的值是字典中的(用字段名表示)字典。包括_inherits’d的字段。string, help, and selection (if present) 属性被翻译。
Parameters:
allfields – list of fields to document, all if empty or not provided
文件的字段列表,如果没有提供,所有的字段都是空的
attributes – list of description attributes to return for each field, all if empty or not provided
为每个字段返回的描述属性列表,全部如果空或未提供
fields_view_get([view_id | view_type='form'])
获得所请求视图的详细组成,如字段、模型、视图架构
Parameters:
view_id – id of the view or None 视图的id或None
view_type – type of the view to return if view_id is None (‘form’, ‘tree’, …) 如果viewid是None('form','tree',…)的视图类型。
toolbar – true to include contextual actions 确实包括上下文动作
submenu – deprecated 不推荐使用
Returns: dictionary describing the composition of the requested view (including inherited views and extensions) 描述被请求视图的组成(包括继承的视图和扩展)的字典
Raises:
AttributeError –
if the inherited view has unknown position to work with other than ‘before’, ‘after’, ‘inside’, ‘replace’
如果继承的视图有未知的位置可以与‘before’, ‘after’, ‘inside’, ‘replace’一起工作
if some tag other than ‘position’ is found in parent view
如果在父视图中发现了“位置”以外的一些标记1
Invalid ArchitectureError – if there is view type other than form, tree, calendar, search etc defined on the structure 如果在结构上定义了视图类型,而不是表单、树、日历、搜索等
杂项工具(各种各样的方法)(Miscellaneous methods)
default_get(fields) → default_values
返回fields_list中的字段的默认值。默认值由上下文、用户违约和模型本身决定。
Parameters:
fields_list – a list of field names 字段名列表
Returns a dictionary mapping each field name to its corresponding default value, if it has one. 如果有一个字典,将每个字段名映射到对应的默认值。
copy(default=None)
重复记录self更新它的默认值
Parameters
default (dict) – dictionary of field values to override in the original values of the copied record, e.g: {'field_name': overridden_value, ...}
在复制记录的原始值中覆盖字段值的字典, e.g: {'field_name': overridden_value, ...}
Returns: new record
name_get() → [(id, name), ...]
返回self中的记录的文本表示法。默认情况下,这是display_name字段的值。
Returns: list of pairs (
id, text_repr) for each records 对每个记录的成对列表(“id,text_repr”)
Return type:list(tuple)
name_create(name) → record
通过调用create()来创造一个新的记录,只提供一个值:新记录的显示名称。
新的记录将使用任何适用于该模型的默认值进行初始化,或者通过context提供。create()通常的行为是适用的。
Parameters:
name – display name of the record to create 显示创建记录的名称
Return type:tuple
Returns: the name_get() pair value of the created record 所创建记录的name_get()配对值
自动字段(Automatic fields)
id
定义字段id
_log_access
日志访问字段(create_date、write_uid、…)是否应该生成(默认:True)
create_date
创建记录的日期
Type :Datetime
create_uid
创建记录的用户的关系字段
Type: res.users
write_date
记录最后一次修改的日期
Type: Datetime
write_uid
对最后一个修改记录的用户的关系字段
Type: res.users
保留字段名称
一些字段名被预留给预先定义的行为,超出了自动化字段的范围。当需要相关的行为时,应该在模型上定义它们:
name
_rec_name的默认值,用于在需要有代表性的“naming”的context显示记录。
Type: Char
active
如果active被设置为False,那么在大多数搜索和列表中,记录是不可见的。
Type: Boolean
sequence
可修改的排序标准,允许在列表视图中对模型进行拖放重新排序
Type: Integer
state
对象的生命周期阶段,由各state属性在字段上使用
Type: Selection
parent_id
用于在树状结构中订单记录,并支持域内的child of操作员
Type: Many2one
parent_left
用于_parent_store,允许更快的树结构访问
parent_right
详见parent_right
方法装饰器(Method decorators)
这个模块提供了管理两种不同API风格的元素,即“traditional”和“record”样式。
在“traditional”样式中,诸如database cursor(数据库游标), user id(用户id), context dictionary(上下文字典) 和record ids(记录ids)(通常表示为cr、uid、context、id)等参数被显式地传递给所有方法。在“record”样式中,这些参数隐藏在模型实例中,这使它具有更面向对象的感觉。
例如,语句:
model = self.pool.get(MODEL)
ids = model.search(cr, uid, DOMAIN, context=context)
for rec in model.browse(cr, uid, ids, context=context):
print rec.name
model.write(cr, uid, ids, VALUES, context=context)
也可以写成:
env = Environment(cr, uid, context) # cr, uid, context wrapped in env
model = env[MODEL] # retrieve an instance of MODEL
recs = model.search(DOMAIN) # search returns a recordset
for rec in recs: # iterate over the records
print rec.name
recs.write(VALUES) # update all records in recs
用“traditional”风格编写的方法会自动修饰,遵循一些基于参数名的启发式。
odoo.api.multi(method)
装饰一个记录风格的方法,self是一个记录集。这个方法通常定义一个记录上的操作。这样一个方法:
@api.multi
def method(self, args):
...
可以在记录和传统风格中被调用,比如:
# recs = model.browse(cr, uid, ids, context)
recs.method(args)
model.method(cr, uid, ids, args, context=context)
odoo.api.model(method)
装饰一种记录式的方法,自我是一个记录集,但它的内容是不相关的,只有模型是。这样一个方法:
@api.model
def method(self, args):
...
可以在记录和传统风格中被调用,比如:
# recs = model.browse(cr, uid, ids, context)
recs.method(args)
model.method(cr, uid, args, context=context)
请注意,没有任何ids以传统的方式传递给该方法。
odoo.api.depends(*args)
返回一个装饰器,它指定了“compute”方法(用于新型功能字段)的字段依赖项。每一个参数都必须是一个字符串,它由一个点分隔的字段名序列组成:
pname = fields.Char(compute='_compute_pname')
@api.one
@api.depends('partner_id.name', 'partner_id.is_company')
def _compute_pname(self):
if self.partner_id.is_company:
self.pname = (self.partner_id.name or "").upper()
else:
self.pname = self.partner_id.name
你也可以把一个函数作为参数传递。在这种情况下,依赖关系是通过调用field模型的函数来给出的。
odoo.api.constrains(*args)
装饰约束检查。每个参数必须是检查中使用的字段名:
@api.one
@api.constrains('name', 'description')
def _check_description(self):
if self.name == self.description:
raise ValidationError("Fields name and description must be different")
在已被修改的指定字段的记录上调用。
如果验证失败,会引起ValidationError 。
警告
@constrains只支持简单的field names(字段名),dotted names (点名)(关系字段的字段,例如partnerid.customer)不受支持,并且将被忽略。
只有在修饰方法中声明的字段包含在
create或write调用中,才会触发@constrains。它意味着在一个视图中不存在的字段不会在创建记录时触发调用。为了确保始终会触发一个约束(例如测试没有值),必须重写create。
odoo.api.onchange(*args)
返回装饰器来装饰给定字段的onchange方法。每个参数必须是一个字段名:
@api.onchange('partner_id')
def _onchange_partner(self):
self.message = "Dear %s" % (self.partner_id.name or "")
在字段出现的表单视图中,当一个给定的字段被修改时,该方法将被调用。这个方法是在一个伪记录上被调用的,这个伪记录包含表单中存在的值。该记录上的字段分配会自动发送回客户端。
这个方法可以返回一个字典来改变字段域,并弹出一个警告消息,就像在旧的API中一样:
return {
'domain': {'other_id': [('partner_id', '=', partner_id)]},
'warning': {'title': "Warning", 'message': "What is this?"},
}
警告
@onchange只支持简单的字段名,虚线名(如partnerid.tz)的字段名不受支持,将被忽略。
odoo.api.returns(model, downgrade=None, upgrade=None)
返回装饰器返回模型实例的方法。
Parameters:
model: – a model name, or 'self' for the current model 模型名称或当前模型名称‘self’
downgrade: – a functiondowngrade(self, value, *args, **kwargs)to convert the record-style value to a traditional-style output 将记录样式的值转化到传统样式的输出
upgrade: – a functionupgrade(self, value, *args, **kwargs)to convert the traditional-style value to a record-style output 将传统样式的值转化为记录样式输出
参数self、*args和**kwargs是在记录样式中传递给该方法的参数。
装饰器将方法输出调整到api样式:传统样式的id、ids或False,以及记录样式的记录集:
@model
@returns('res.partner')
def find_partner(self, arg):
... # return some record
# output depends on call style: traditional vs record style
partner_id = model.find_partner(cr, uid, arg, context=context)
# recs = model.browse(cr, uid, ids, context)
partner_record = recs.find_partner(arg)
请注意,装饰方法必须满足该约定。
这些修饰符是自动继承的:覆盖修饰过的现有方法的方法将使用相同的@returns(model)来装饰。
odoo.api.one(method)(已弃用)
装饰一个记录样式的方法,在这个方法中,self被期望是一个单例实例。修饰的方法会自动在记录上循环,并使用结果列出一个列表。如果方法使用returns()来装饰,则会将产生的实例连接起来。如下列方法:
@api.one
def method(self, args):
return self.name
可以在记录和传统风格中被调用,比如:
# recs = model.browse(cr, uid, ids, context)
names = recs.method(args)
names = model.method(cr, uid, ids, args, context=context)
自版本9.0弃用以来:one(),弃用的代码常常使代码不那么清晰,并且以开发人员和读者可能想不到的方式表现出来。
强烈建议使用multi(),并在self记录集上进行迭代,或者确保记录集是带有ensure_one()的单个记录。
odoo.api.v7(method_v7)
只支持旧式api的方法。一种新型的api可以通过重新定义具有相同名称的方法来提供,并使用v8()进行修饰:
@api.v7
def foo(self, cr, uid, ids, context=None):
...
@api.v8
def foo(self):
...
如果一种方法调用另一个方法,则必须特别小心,因为该方法可能会被覆盖!在这种情况下,应该从当前类(比如MyClass)调用该方法,例如:
@api.v7
def foo(self, cr, uid, ids, context=None):
# Beware: records.foo() may call an overriding of foo()
records = self.browse(cr, uid, ids, context)
return MyClass.foo(records)
注意装饰器方法使用第一个方法的docstring。
odoo.api.v8(method_v8)
仅对新型api的装修方法进行修饰。一个旧式的api可以通过重新定义一个同名的方法来提供,并使用v7()进行修饰:
@api.v8
def foo(self):
...
@api.v7
def foo(self, cr, uid, ids, context=None):
...
注意装饰器方法使用第一个方法的docstring。
字段(Fields)
基础字段(Basic fields)
class odoo.fields.Field(string=<object object>, **kwargs)
字段描述符包含字段定义,并管理记录上相应字段的存取和赋值。当一个字段的立即执行时,可以提供以下属性:
Parameters:
string: – the label of the field seen by users (string); if not set, the ORM takes the field name in the class (capitalized). 用户看到的字段的标签(字符串);如果没有设置,ORM就会在类中获取字段名(大写)。
help – the tooltip of the field seen by users (string) 用户看到的字段的提示(字符串)
readonly – whether the field is readonly (boolean, by default False) 字段是否为readonly(布尔值,默认为False)
required – whether the value of the field is required (boolean, by default False) 是否需要字段的值(布尔值,默认为False)
index – whether the field is indexed in database (boolean, by default False) 字段是否在数据库中被索引(布尔值,默认为False)
default – the default value for the field; this is either a static value, or a function taking a recordset and returning a value; use default=None to discard default values for the field
该字段的缺省值;这是一个静态值,或者是一个使用记录集并返回一个值的函数;使用default=None取消字段的默认值
states – a dictionary mapping state values to lists of UI attribute-value pairs; possible attributes are: ‘readonly’, ‘required’, ‘invisible’. Note: Any state-based condition requires thestatefield value to be available on the client-side UI. This is typically done by including it in the relevant views, possibly made invisible if not relevant for the end-user.
字典将状态值映射到UI属性-值对列表;可能的属性是:‘readonly’, ‘required’, ‘invisible’。注意:任何基于状态的条件都需要在客户端UI上提供state字段值。这通常是通过将其包含在相关视图中来完成的,可能是不可见的,如果与最终用户无关的话
groups – comma-separated list of group xml ids (string); this restricts the field access to the users of the given groups only
逗号分隔的组xml ids列表(字符串);这限制了只对给定组的用户进行字段访问
copy (bool) – whether the field value should be copied when the record is duplicated (default: True for normal fields, False for one2many and computed fields, including property fields and related fields)
当记录被复制时,是否应该复制字段值(默认情况:True值用于正常字段来,False值用于one2many和计算字段,包括属性字段和相关字段)
oldname (string) – the previous name of this field, so that ORM can rename it automatically at migration 这个字段的前一个名称,以便ORM可以在迁移时自动重命名它
计算字段(Computed fields)
你可以定义一个值被计算的字段,而不是简单地从数据库中读取。下面给出了特定于计算字段的属性。要定义这样的字段,只需为属性compute提供一个值。
Parameters:
compute – name of a method that computes the field 计算该字段的方法的名称
inverse – name of a method that inverses the field (optional) 反向字段(可选)的方法的名称
search – name of a method that implement search on the field (optional)
在字段实现搜索的方法的名称(可选)
store – whether the field is stored in database (boolean, by default False on computed fields) 字段是否存储在数据库中(布尔值,默认情况下False在计算字段上)
compute_sudo – whether the field should be recomputed as superuser to bypass access rights (boolean, by default False)
该字段是否应该重新计算为超级用户,以绕过访问权限(布尔值,默认为False)
compute, inverse and search的方法是模型方法。他们的签名如下面的例子所示:
upper = fields.Char(compute='_compute_upper',
inverse='_inverse_upper',
search='_search_upper')
@api.depends('name')
def _compute_upper(self):
for rec in self:
rec.upper = rec.name.upper() if rec.name else False
def _inverse_upper(self):
for rec in self:
rec.name = rec.upper.lower() if rec.upper else False
def _search_upper(self, operator, value):
if operator == 'like':
operator = 'ilike'
return [('name', operator, value)]
计算方法必须在被调用的记录集中的所有记录上指定字段。装饰器odoo.api.depends()必须应用于计算方法,以指定字段依赖项;这些依赖关系用于确定何时重新计算字段;重新计算是自动的,并保证缓存/数据库的一致性。请注意,同样的方法可以用于几个字段,您只需分配方法中的所有给定字段;该方法将在所有的这些字段中被调用一次。
默认情况下,计算字段不会存储到数据库中,并且是动态计算的。添加属性store=True将把字段的值存储在数据库中。存储字段的优点是,在该字段上进行搜索是由数据库本身完成的。缺点是,当字段必须重新计算时,它需要数据库更新。
inverse方法,如其名称所示,是计算方法的倒数:被调用的记录对字段有一个值,并且您必须在字段依赖项上应用必要的更改,以便计算给出预期的值。注意,没有inverse方法的计算字段在默认情况下是readonly。
在对模型进行实际搜索之前,当处理域时调用search方法。它必须返回一个域相同的条件:field operator value(字段操作值)
关联字段(Related fields)
关联字段的值是通过一系列关联字段和在接近的模型读取字段。要遍历的字段的完整序列是由属性指定的
Parameters:
related – sequence of field names 一系列字段名称
如果没有重新定义的话,一些字段属性会自动从源字段中复制:string, help, readonly, required(只有在需要序列中的所有字段时才需要)、groups, digits, size, translate, sanitize, selection, comodel_name, domain, context。所有的语义不相关的属性都是从源字段中复制的。
默认情况下,相关字段的值不会存储到数据库中。添加属性store=True来使其存储,就像计算字段一样。当相关性被修改时,相关字段会自动重新计算。
公司依赖字段(Company-dependent fields)
以前被称为“property”字段,这些字段的价值取决于公司。换句话说,属于不同公司的用户在给定的记录中可能会看到该字段的不同值。
Parameters:
company_dependent – whether the field is company-dependent (boolean)
字段是否是公司依赖值(boolean)
增量定义(Incremental definition)
字段被定义为model类上的class属性。如果模型被扩展(参见Model),您还可以通过重新定义一个同名的字段来扩展字段定义,并在子类中定义相同的类型。在这种情况下,字段的属性取自父类,并由子类中给出的属性覆盖。
例如,下面的第二个类只会在字段state上添加一个提示:
class First(models.Model):
_name = 'foo'
state = fields.Selection([...], required=True)
class Second(models.Model):
_inherit = 'foo'
state = fields.Selection(help="Blah blah blah")
Char
class odoo.fields.Char(string=<object object>, **kwargs)
基类:odoo.fields._String
基本的字符串字段,可以是长度限制的,通常在客户端显示为单行字符串。
Parameters:
size (int) – the maximum size of values stored for that field
存储该字段的最大值的最大值
translate – enable the translation of the field’s values; use translate=True to translate field values as a whole; translate may also be a callable such that translate(callback, value) translates value by using callback(term) to retrieve the translation of terms.
允许翻译字段的值;使用translate=True将字段值转换为一个整体;translate也可以是一个可调用的函数,类似translate(callback, value)翻译通过使用callback(term)获取翻译的条目的value
Boolean
class odoo.fields.Boolean(string=<object object>, **kwargs)
基类:odoo.fields.Field
Float
class odoo.fields.Float(string=<object object>, digits=<object object>, **kwargs)
基类: odoo.fields.Field
精度数字是由属性给出的
Parameters:
digits – a pair (total, decimal), or a function taking a database cursor and returning a pair (total, decimal)
一对(总数,十进制),或者一个函数,取一个数据库游标并返回一对(总数,小数)
Text
class odoo.fields.Text(string=<object object>, **kwargs)
基类:Bases: odoo.fields._String
与Char非常相似,但用于较长的内容,没有大小,通常显示为多行文本框。
Parameters
translate – enable the translation of the field’s values; use translate=True to translate field values as a whole; translate may also be a callable such that translate(callback, value) translates value by using callback(term) to retrieve the translation of terms.
允许翻译字段的值;使用translate=True将字段值转换为一个整体;translate也可以是一个可调用的函数,类似translate(callback, value)翻译通过使用callback(term)获取翻译的条目的value
Selection
class odoo.fields.Selection(selection=<object object>, string=<object object>, **kwargs)
基类:Bases: odoo.fields.Field
Parameters
selection – specifies the possible values for this field. It is given as either a list of pairs (value, string), or a model method, or a method name.
指定该字段的可能值。它被作为成对的列表(值,字符串),或者一个模型方法,或者一个方法名。
selection_add – provides an extension of the selection in the case of an overridden field. It is a list of pairs (value, string).
在覆盖字段的情况下提供选择的扩展。它是一对对(值,字符串)的列表。
属性selection是强制性的,除非是相关字段或字段扩展名。
Html
class odoo.fields.Html(string=<object object>, **kwargs)
基类: odoo.fields._String
Date
class odoo.fields.Date(string=<object object>, **kwargs)
基类: odoo.fields.Field
static context_today(timestamp=None)
以格式化的样式或者日期字段返回在客户的时区中看到的当前日期。这个方法可以用来计算默认值。
Parameters:
timestamp (datetime) – optional datetime value to use instead of the current date and time (must be a datetime, regular dates can’t be converted between timezones.)
可选的datetime值代替当前日期和时间(必须是datetime,常规日期不能在时区之间转换)。
Return type :str
返回类型字符串
static from_string()
将ORMvalue转换为date值。
static to_string()
将date值转换为ORM所期望的格式。
static today()
以ORM期望的格式返回当前的日期。这个函数可以用来计算默认值。
Datetime
class odoo.fields.Datetime(string=<object object>, **kwargs)
基类:odoo.fields.Field
static context_timestamp(timestamp)
返回给定时间戳转换为客户端的时区。这种方法不适合作为默认的初始化器,因为datetime字段会在客户端显示时自动转换。对于默认值fields.datetime.now()应该使用。
Parameters
timestamp (datetime) – naive datetime value (expressed in UTC) to be converted to the client timezone
原始的datetime值(在UTC中表示)被转换为客户端时区
Return type datetime
Returns 时间戳在context时区转换为timezone-aware datetime
static from_string()
将ORMvalue转换为date值。
static now()
以ORM期望的格式返回当前的日期和时间。这个函数可以用来计算默认值。
static to_string()
将datetime值转换为ORM所期望的格式。
关系字段(Relational fields)
Many2one
class odoo.fields.Many2one(comodel_name=<object object>, string=<object object>, **kwargs)
基类:odoo.fields._Relational
这样一个字段的值是一个长度为0(没有记录)或1(单个记录)的记录集。
Parameters:
comodel_name – name of the target model (string)
目标模型的名称(字符串)
domain – an optional domain to set on candidate values on the client side (domain or string)
在客户端(域或字符串)上设置候选值的可选域
context – an optional context to use on the client side when handling that field (dictionary)
在处理该字段时在客户端使用的可选上下文(dictionary)
ondelete – what to do when the referred record is deleted; possible values are: 'set null', 'restrict', 'cascade'
当被引用的记录被删除时该怎么办;可能的值是:'set null', 'restrict', 'cascade'
auto_join – whether JOINs are generated upon search through that field (boolean, by default False)
是否通过该字段进行搜索(boolean,默认为False)
delegate – set it to True to make fields of the target model accessible from the current model (corresponds to _inherits)
将其设置为True,使目标模型的字段可从当前模型中访问(对应于_inherits)
除了相关字段或字段扩展的情况外,属性comodel_name是强制性的。
One2many
class odoo.fields.One2many(comodel_name=<object object>, inverse_name=<object object>, string=<object object>, **kwargs)
基类:odoo.fields._RelationalMulti
One2many字段;这样一个字段的值是所有记录的记录集在comodel_name,例如字段inverse_name 就等于当前记录。
Parameters:
comodel_name – name of the target model (string)
目标模型的名称(字符串)
inverse_name – name of the inverse Many2one field incomodel_name(string)
在comodel_name相反的Many2one字段的名称(string)
domain – an optional domain to set on candidate values on the client side (domain or string) 在客户端上设置候选值的可选域(域或字符串)
context – an optional context to use on the client side when handling that field (dictionary) 在处理该字段时在客户端使用的可选上下文(dictionary)
auto_join – whether JOINs are generated upon search through that field (boolean, by default False) 是否JOINs是通过字段搜索产生的(布尔值,默认为False)
limit – optional limit to use upon read (integer) 阅读时可选择的限制(integer)
除了相关字段或字段扩展名之外,属性comodel_name和inverse_name都是必需的。
Many2many
class odoo.fields.Many2many(comodel_name=<object object>, relation=<object object>, column1=<object object>, column2=<object object>, string=<object object>, **kwargs)
基类:odoo.fields._RelationalMulti
Many2many字段;这样一个字段的值就是记录集。
Parameters:
comodel_name – name of the target model (string) 目标模型名称(string)
除了相关字段或字段扩展的情况外,属性comodel_name是强制性的。
Parameters
relation – optional name of the table that stores the relation in the database (string) 在数据库中储存关系的表的可选名称(string)
column1 – optional name of the column referring to “these” records in the table relation (string) 列的可选名称,指的是表关系中的“这些”记录
column2 – optional name of the column referring to “those” records in the table relation (string) 列的可选名称,指的是表关系中的“那些”记录
属性ralation、column1和column2是可选的。如果没有给出,名称将自动从模型名称中生成,提供的model_name和comodel_name是不同的!
Parameters
domain – an optional domain to set on candidate values on the client side (domain or string) 在客户端上设置候选值的可选域(domain或者字符串)
context – an optional context to use on the client side when handling that field (dictionary) 在处理该字段时在客户端使用的可选context
limit – optional limit to use upon read (integer) 阅读时可选择的限制(integer)
project_ids = fields.Many2many('project.project', 'project_task_type_rel', 'type_id', 'project_id', string='Projects',
default=_get_default_project_ids)
project.project 对应的关联表
project_task_type_rel 自定义多对多关系表名字
type_id 自定义多对多关系表对方的表
project_id 自定义对方关系表本方字段
Reference
class odoo.fields.Reference(selection=<object object>, string=<object object>, **kwargs)
基类: odoo.fields.Selection
继承和扩展(Inheritance and extension)
Odoo提供了三种不同的机制来以模块化的方式扩展模型:
- 从现有的模型中创建一个新模型,向副本添加新信息,但保留原始模块(第一种Classical inheritance)
- 扩展其他模块中定义的模型,取代以前的版本(第二种扩展继承(Extension))
- 把模型的一些字段委托给它包含的记录(第三种委托继承(Delegation))
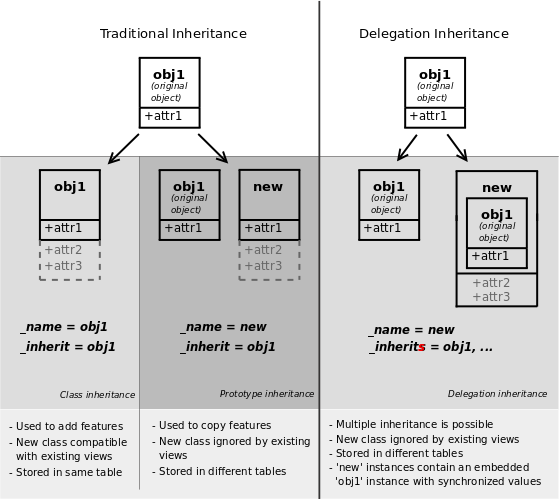
经典继承(Classical inheritance)
当使用inherit和_name属性时,Odoo使用现有的模型(通过继承提供的)作为基础创建一个新模型。这个新模型从它的基础上获得所有的字段、方法和元信息(defaults & al)。
class Inheritance0(models.Model):
_name = 'inheritance.0'
name = fields.Char()
def call(self):
return self.check("model 0")
def check(self, s):
return "This is {} record {}".format(s, self.name)
class Inheritance1(models.Model):
_name = 'inheritance.1'
_inherit = 'inheritance.0'
def call(self):
return self.check("model 1")
然后使用它们
a = env['inheritance.0'].create({'name': 'A'})
b = env['inheritance.1'].create({'name': 'B'})
a.call()
b.call()
会产生:
"This is model 0 record A"
"This is model 1 record B"
第二种模型继承了第一种模型的check方法及其name字段,但是重写了call方法,就像使用标准Python继承一样。
扩展继承(Extension)
当使用inherit而忽略_name时,新模型将替换现有的模型,本质上是将其扩展到适当的位置。这对于向现有模型(在其他模块中创建)添加新的字段或方法是很有用的,或者对它们进行定制或重新配置(例如,更改它们的默认排序顺序):
class Extension0(models.Model):
_name = 'extension.0'
name = fields.Char(default="A")
class Extension1(models.Model):
_inherit = 'extension.0'
description = fields.Char(default="Extended")
env = self.env
{'name': "A", 'description': "Extended"}
它还会产生各种自动字段(automatic fields),除非它们已经被禁用了
委托继承(Delegation)
第三种继承机制提供了更多的灵活性(可以在运行时进行修改),但更少的权力:使用inherits模型将模型中查找不能找到的任何字段的委托给“children(子)”模型。该委托继承是通过在父模型上自动建立的Reference字段来执行的:
class Child0(models.Model):
_name = 'delegation.child0'
field_0 = fields.Integer()
class Child1(models.Model):
_name = 'delegation.child1'
field_1 = fields.Integer()
class Delegating(models.Model):
_name = 'delegation.parent'
_inherits = {
'delegation.child0': 'child0_id',
'delegation.child1': 'child1_id',
}
child0_id = fields.Many2one('delegation.child0', required=True, ondelete='cascade')
child1_id = fields.Many2one('delegation.child1', required=True, ondelete='cascade')
record = env['delegation.parent'].create({
'child0_id': env['delegation.child0'].create({'field_0': 0}).id,
'child1_id': env['delegation.child1'].create({'field_1': 1}).id,
})
record.field_0
record.field_1
将产生如下结果
0
1
也可以直接写在委托的字段:
record.write({'field_1': 4})
域(Domains)
域是标准的列表,每个标准是(field_name、operator、value)的三重(即列表或元组):
field_name (str)
当前模型的一个字段名,或者是通过使用点符号的Many2one的关系遍历。“street”或“partner_id.country”
operator (str)
一个操作符用来比较字段名和值. 存在的操作符:
=
equals to
!=
not equals to
>
greater than
>=
greater than or equal to
<
less than
<=
less than or equal to
=?
unset or equals to (returns true if value is either None or False, otherwise behaves like =)
=like
matches field_name against the value pattern. An underscore _ in the pattern stands for (matches) any single character; a percent sign % matches any string of zero or more characters.
like
matches field_name against the %value% pattern. Similar to =like but wraps value with ‘%’ before matching
not like
doesn’t match against the %value% pattern
ilike
case insensitive like
not ilike
case insensitive not like
=ilike
case insensitive =like
in
is equal to any of the items from value, value should be a list of items
not in
is unequal to all of the items from value
child_of
is a child (descendant) of a value record.
Takes the semantics of the model into account (i.e following the relationship field named by _parent_name).
value
variable type, must be comparable (through operator) to the named field
Domain criteria can be combined using logical operators in prefix form:
'&'
logical AND, default operation to combine criteria following one another. Arity 2 (uses the next 2 criteria or combinations).
'|'
logical OR, arity 2.
'!'
logical NOT, arity 1.