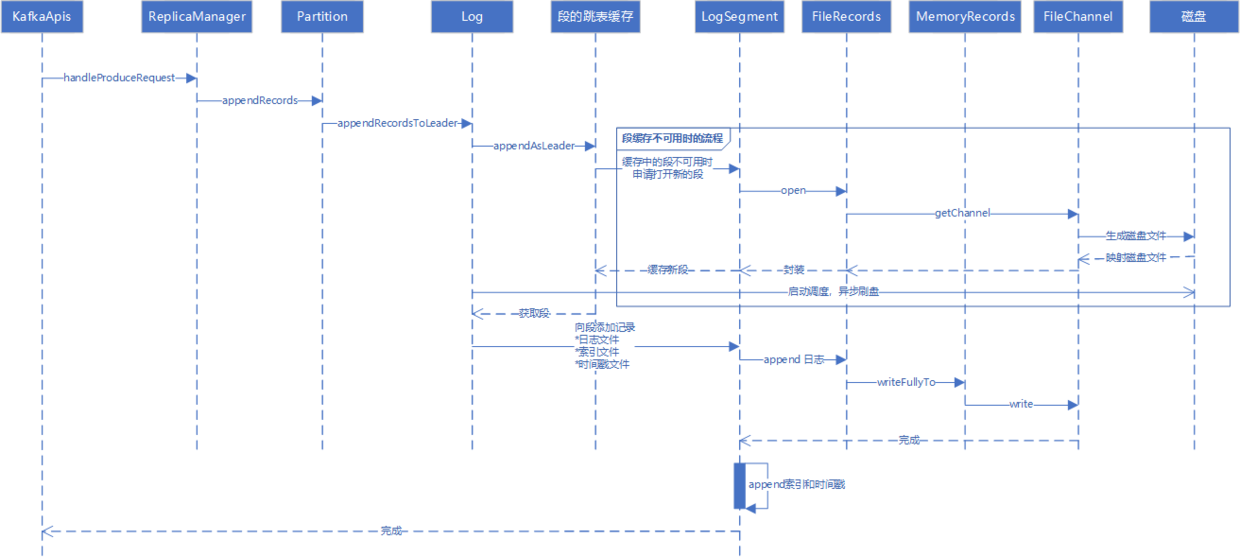
写入流程
Kafka 服务端通过KafkaApis的handle()方法来统一处理请求,ApiKeys枚举了能被handle() 方法处理的请求类型吗,如果是PRODUCE类型,表示有生产者客户端发送了消息,之后将消息传递给副本管理器处理。
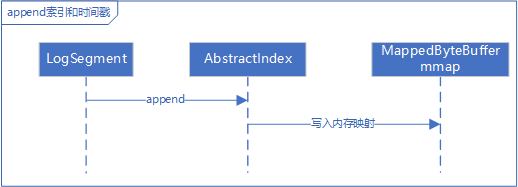
副本管理器会将消息追加到分区 leader 副本的日志文件中,然而实际上并不是直接写入磁盘的,Kafka 会将日志的段 segment 缓存到跳跃表ConcurrentSkipListMap。写入日志时,首先会从缓存中查找段,如果能找到,则向该段中追加记录,记录包含日志文件、索引文件、时间戳文件。日志文件会被写入FileChannel 中,索引文件和时间戳文件会被写入MappedByteBuffer中。最后,后台调度程序会周期地将段文件刷新到磁盘持久化。
如果段缓存中没有找到合适的段,则通过FileChannel来打开一个新的段,返回磁盘文件的段映射,封装为 segment 后,再缓存到跳跃表中,供下一次追加日志时使用。
日志的写入处理流程
索引和偏移量的写入处理流程
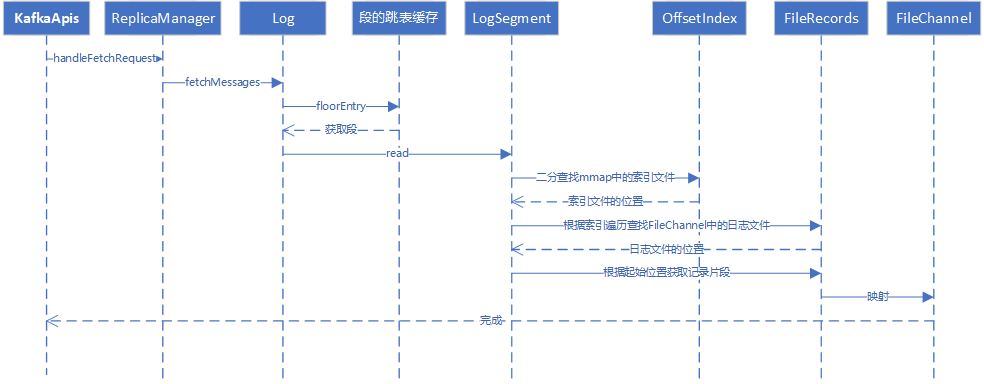
读取流程
如果请求是FETCH类型,表示有消费者客户端发送了拉取请求,同样,将请求传递给副本管理器处理。
副本管理器在写入日志时,将段缓存到了跳跃表中,因此读取时,可以直接从跳跃表中获取段,向该段发起读取操作。首先,利用二分查找算法,查找mmap中的索引文件,根据索引文件记录的日志偏移量,遍历查找FileChannel中的日志文件所在的位置,最后,根据偏移量和需要拉取的大小获取日志片段,返回给消费者。
日志的读取处理流程