python环境安装
过于基础,此处就不细写了,可参考:https://www.runoob.com/python/python-install.html
Python基本数据类型
可变、不可变数据类型
可变数据类型 列表、字典、集合--不可哈希 集合里存的元素必须是不可变的数据类型,无序,不重复(去重) 不可变数据类型 元组、数字、字符串--可哈希
字符串
字符串是 Python 中最常用的数据类型。我们可以使用引号('或")来创建字符串。创建字符串很简单,只要为变量分配一个值即可


'strs'.capitalize() #首字母大写 'strs'.title() #每个单词首字母大写 'strs'.upper() #每个字母变为大写 'strs'.lower() #每个字母变为小写 'strs'.swapcase() #大小写互换 'strs'.count() #计算指定字符串或字符出现的次数 'strs'.find() #根据指定的字符获取该字符在字符串中第一次出现的索引位置(找不到索引返回-1) 'strs'.index() #根据指定的字符获取该字符在字符串中第一次出现的索引位置(找不到索引返回一个异常错误) 'strs'.startswith() #检测字符串是否以指定字符开头 'strs'.endswith() #检测字符串是否以指定字符结尾 'strs'.isupper() #检测字符串是否都为大写字母 'strs'.islower() #检测字符串是否都为小写字母 'strs'.istitle() #检测字符串是否都为单词首字母大写 'strs'.isalnum() #检测字符串是否只由字母和数字字符组成 'strs'.isalpha() #检测字符串是否只由字母字符(含中文字符)组成 'strs'.isdigit() #检测字符串是否只由十进制数字字符组成 'strs'.isnumeric() #检测字符串是否以数字字符组成 'strs'.isdecimal() #检测字符串是否以数字字符组成 'strs'.isspace() #检测字符串是否由空白字符组成 'strs'.split() #使用指定字符,将字符串进行切割并装入列表 'strs'.splitlines() #使用回车字符,切割字符串并装入列表中 'strs'.join(['a','b','c']) #将容器中的字符串使用指定字符拼接成一个字符串 'strs'.zfill() #使用0填充字符串,参数为填充后的总位数 'strs'.center() #用指定字符,将字符串居中填充到指定长度,参数(长度,使用的字符) 'strs'.ljust() #用指定字符,将字符串左对齐填充到指定长度,参数(长度,使用的字符) 'strs'.rjust() #用指定字符,将字符串右对齐填充到指定长度,参数(长度,使用的字符) 'strs'.strip() #去掉字符串中,两侧指定重复的字符(如果不指定字符,则删除空格) 'strs'.lstrip() #去掉字符串中,左侧指定重复的字符(如果不指定字符,则删除空格) 'strs'.rjust() #去掉字符串中,右侧指定重复的字符(如果不指定字符,则删除空格) #替换字符串中的字符 'strs'.maketrans() #制作字典 'strs'.translate() #使用字典替换 #exampel var = 'wiz good guy,wiz super cool' flag = ''.maketrans('wiz','wwr') res = var.translate(flag)
字典
字典中的每个元素都有一个名字,这个名字叫键(key)。
字典(也叫散列表)是Python中唯一内建的映射类型。
字典的键可以是数字、字符串或者是元组,键必须唯一。
在Python中,数字、字符串和元组都被设计成不可变类型,而常见的列表以及集合(set)都是可变的,所以列表和集合不能作为字典的键。
键可以为任何不可变类型,这正是Python中的字典最强大的地方。
|
函数 |
说明 |
|
D |
代表字典对象 |
|
D.clear() |
清空字典 |
|
D.pop(key) |
移除键,同时返回此键所对应的值 |
|
D.copy() |
返回字典D的副本,只复制一层(浅拷贝) |
|
D.update(D2) |
将字典 D2 合并到D中,如果键相同,则此键的值取D2的值作为新值 |
|
D.get(key, default) |
返回键key所对应的值,如果没有此键,则返回default |
|
D.keys() |
返回可迭代的 dict_keys 集合对象 |
|
D.values() |
返回可迭代的 dict_values 值对象 |
|
D.items() |
返回可迭代的 dict_items 对象 |
集合
集合(Set)在Python 2.3引入,通常使用较新版Python可直接创建,如下所示:
strs=set(['jeff','wong','cnblogs']) nums=set(range(10))
看上去,集合就是由序列(或者其他可迭代的对象)构建的。
集合的几个重要特点和方法如下(S 为集合对象):
|
方法 |
意义 |
|
S.add(e) |
在集合中添加一个新的元素e;如果元素已经存在,则不添加 |
|
S.remove(e) |
从集合中删除一个元素,如果元素不存在于集合中,则会产生一个KeyError错误 |
|
S.discard(e) |
从集合S中移除一个元素e,在元素e不存在时什么都不做; |
|
S.clear() |
清空集合内的所有元素 |
|
S.copy() |
将集合进行一次浅拷贝 |
|
S.pop() |
从集合S中删除一个随机元素;如果此集合为空,则引发KeyError异常 |
|
S.update(s2) |
用 S与s2得到的全集更新变量S |
|
S.difference(s2) |
用S - s2 运算,返回存在于在S中,但不在s2中的所有元素的集合 |
|
S.difference_update(s2) |
等同于 S = S - s2 |
|
S.intersection(s2) |
等同于 S & s2 |
|
S.intersection_update(s2) |
等同于S = S & s2 |
|
S.isdisjoint(s2) |
如果S与s2交集为空返回True,非空则返回False |
|
S.issubset(s2) |
如果S与s2交集为非空返回True,空则返回False |
|
S.issuperset(...) |
如果S为s2的子集返回True,否则返回False |
|
S.symmetric_difference(s2) |
返回对称补集,等同于 S ^ s2 |
|
S.symmetric_difference_update(s2) |
用 S 与 s2 的对称补集更新 S |
|
S.union(s2) |
生成 S 与 s2的全集 |
列表
列表是可变的,这是它区别于字符串和元组的最重要的特点,一句话概括即:列表可以修改,而字符串和元组不能。
列表操作包含以下函数:
cmp(list1, list2):比较两个列表的元素
len(list):列表元素个数
max(list):返回列表元素最大值
min(list):返回列表元素最小值
list(seq):将元组转换为列表
列表操作包含以下方法:
list.append(obj):在列表末尾添加新的对象 list.count(obj):统计某个元素在列表中出现的次数 list.extend(seq):在列表末尾一次性追加另一个序列中的多个值(用新列表扩展原来的列表) list.index(obj):从列表中找出某个值第一个匹配项的索引位置 list.insert(index, obj):将对象插入列表 list.pop(obj=list[-1]):移除列表中的一个元素(默认最后一个元素),并且返回该元素的值 list.remove(obj):移除列表中某个值的第一个匹配项 list.reverse():反向列表中元素 list.sort([func]):对原列表进行排序
copy()与deepcopy()的区别:
对于不可变的对象来说(数字,字符串,元组),深浅拷贝没有区别 深复制,即将被复制对象完全再复制一遍作为独立的新个体单独存在。所以改变原有被复制对象不会对已经复制出来的新对象产生影响。 等于赋值,并不会产生一个独立的对象单独存在,他只是将原有的数据块打上一个新标签,所以当其中一个标签被改变的时候,数据块就会发生变化,另一个标签也会随之改变。 浅复制要分两种情况进行讨论: 1)当浅复制的值是不可变对象(数值,字符串,元组)时和“等于赋值”的情况一样,对象的id值与浅复制原来的值相同。 2)当浅复制的值是可变对象(列表和元组)时会产生一个“不是那么独立的对象”存在。有两种情况: 第一种情况:复制的对象中无复杂子对象,原来值的改变并不会影响浅复制的值,同时浅复制的值改变也并不会影响原来的值。 原来值的id值与浅复制原来的值不同。 第二种情况:复制的对象中有 复杂 子对象 (例如列表中的一个子元素是一个列表),如果不改变其中复杂子对象, 浅复制的值改变并不会影响原来的值。 但是改变原来的值 中的复杂子对象的值 会影响浅复制的值。
元组
Python的元组与列表类似,不同之处在于元组的元素不能修改。元组使用小括号,列表使用方括号。元组创建很简单,只需要在括号中添加元素,并使用逗号隔开即可。
元组操作包含以下函数:
cmp(list1, list2):比较两个元组的元素
len(list):元组元素个数
max(list):返回元组元素最大值
min(list):返回元组元素最小值
tuple(seq):将列表转换为元组
修改元组:
元组中的元素值是不允许修改的,但我们可以对元组进行连接组合,如下实例: tup1 = (12, 34.56) tup2 = ('abc', 'xyz') # 以下修改元组元素操作是非法的。 # tup1[0] = 100 # 创建一个新的元组 tup3 = tup1 + tup2 print(tup3)
删除元组:
元组中的元素值是不允许删除的,但我们可以使用del语句来删除整个元组
注意:只含一个值的元组,必须加个逗号(,);
栈、队列
堆栈:先进后出
队列:先进先出 FIFO
from collections import namedtuple Point=namedtuple('point', ['x','y']) p=Point(1,2) print(p.x) #1 print(p.y) #2 print(p) #point(x=1,y=2)
队列:先进先出 import queue Q=queue.Queue() Q.put(10) Q.put(5) Q.put(6) print(Q) #<queue.Queue object at 0x0000000001DCA198> print(Q.get()) print(Q.get()) print(Q.get()) print(Q.get()) #阻塞 print(Q.qsize()) #查看大小
from collections import deque q=deque([1,2]) q.append('a')#从后面放数据 q.appendleft('b')#从前面放数据 q.insert(1,3) print(q.pop())#从后面取数据 #a print(q.popleft())#从前面取数据 #b print(q) #deque([3, 1, 2])
Python基本语法
控制语句
函数
文件读写
参考廖大的教程:文件读写
pandas|numpy环境安装
python终端下,执行:
pip install pandas # 安装pandas
pip install numpy # 安装numpy
【强烈推荐使用Anaconda:anaconda安装步骤 (anaconda是个集成式的工具包,能一站式的完成你工作学习所需的大部分文件安装)】
pandas数据结构
Seriers
一种类似于一维数组的对象,是由一组数据(各种NumPy数据类型)以及一组与之相关的数据标签(即索引)组成。仅由一组数据也可产生简单的Series对象。注意:Series中的索引值是可以重复的。
Seriers的创建
使用列表生成Seriers:
import numpy as np import pandas as pd # 使用一个列表生成一个Series s1 = pd.Series([1, 2, 3, 4]) print(s1) ''' 0 1 1 2 2 3 3 4 dtype: int64 ''' # 返回所有的索引 print(s1.index) ''' RangeIndex(start=0, stop=4, step=1) '''
使用数组生成Seriers:
import numpy as np import pandas as pd # 使用数组生成一个Series s2 = pd.Series(np.arange(7)) print(s2) ''' 0 0 1 1 2 2 3 3 4 4 5 5 6 6 dtype: int64 '''
使用字典生成Seriers:
# 使用一个字典生成Series,其中字典的键,就是索引 s3 = pd.Series({'1':1, '2':2, '3':3}) print(s3) print(s3.values) print(s3.index) ''' 1 1 2 2 3 3 dtype: int64 [1 2 3] Index(['1', '2', '3'], dtype='object') '''
Seriers基本操作
#series #操作的基本技巧:数据查看 / 重新索引 / 对齐 / 添加、修改、删除值 # 数据查看 s = pd.Series(np.random.rand(50)) print(s.head(10)) print(s.tail()) # 重新索引reindex # .reindex将会根据索引重新排序,如果当前索引不存在,则引入缺失值 s = pd.Series(np.random.rand(3), index = ['a','b','c']) print(s) s1 = s.reindex(['c','b','a','d']) print(s1) # .reindex()中也是写列表 # 这里'd'索引不存在,所以值为NaN s2 = s.reindex(['c','b','a','d'], fill_value = 0) print(s2) # fill_value参数:填充缺失值的值 # 删除:.drop s = pd.Series(np.random.rand(5), index = list('ngjur')) print(s) s1 = s.drop('n') s2 = s.drop(['g','j']) # 添加: # 直接通过下标索引/标签index添加值 s2 = pd.Series(np.random.rand(5), index = list('ngjur')) s2['a'] = 100 s1 = pd.Series(np.random.rand(5)) s1[5] = 100 # 通过.append方法,直接添加一个数组 s3 = s1.append(s2) # .append方法生成一个新的数组,不改变之前的数组 # 修改 s = pd.Series(np.random.rand(3), index = ['a','b','c']) print(s) s['a'] = 100 s[['b','c']] = 200 print(s) # 通过索引直接修改,类似序列
Dataframe
一个表格型的数据结构,包含有一组有序的列,每列可以是不同的值类型(数值、字符串、布尔型等),DataFrame即有行索引也有列索引,可以被看做是由Series组成的字典。
Dataframe的创建
包含列表的字典创建:
data = {'水果':['苹果','梨','草莓'],
'数量':[3,2,5],
'价格':[10,9,8]}
df = DataFrame(data)
print(df)
价格 数量 水果 0 10 3 苹果 1 9 2 梨 2 8 5 草莓
嵌套字典创建:
data = {'数量':{'苹果':3,'梨':2,'草莓':5},
'价格':{'苹果':10,'梨':9,'草莓':8}}
df = DataFrame(data)
print(df)
价格 数量
梨 9 2
苹果 10 3
草莓 8 5
包含Series的字典创建
data = {'水果':Series(['苹果','梨','草莓']),
'数量':Series([3,2,5]),
'价格':Series([10,9,8])}
df = DataFrame(data)
print(df)
价格 数量 水果
0 10 3 苹果
1 9 2 梨
2 8 5 草莓
Dataframe基本操作
#dataframe #数据查看、转置 / 添加、修改、删除值 / 对齐 / 排序 # 数据查看、转置 同series df = pd.DataFrame(np.random.rand(16).reshape(8,2)*100, columns = ['a','b']) print(df.head(2)) print(df.tail()) print(df.T) # 添加与修改 df = pd.DataFrame(np.random.rand(16).reshape(4,4)*100, columns = ['a','b','c','d']) # 新增列 df['e'] = 10 # 新增行并赋值 df.loc[4] = 20 a b c d e 0 17.148791 73.833921 39.069417 5.675815 10 1 91.572695 66.851601 60.320698 92.071097 10 2 79.377105 24.314520 44.406357 57.313429 10 3 84.599206 61.310945 3.916679 30.076458 10 4 20.000000 20.000000 20.000000 20.000000 20 # 索引后直接修改值 df['e'] = 20 df[['a','c']] = 100 # 删除 del / drop() # drop()删除行,inplace=False → 删除后生成新的数据,不改变原数据 df.drop(0) df.drop([1,2]) # drop()删除列,需要加上axis = 1,inplace=False → 删除后生成新的数据,不改变原数据 df.drop(['d'], axis = 1) # del语句 - 删除列 del df['a']
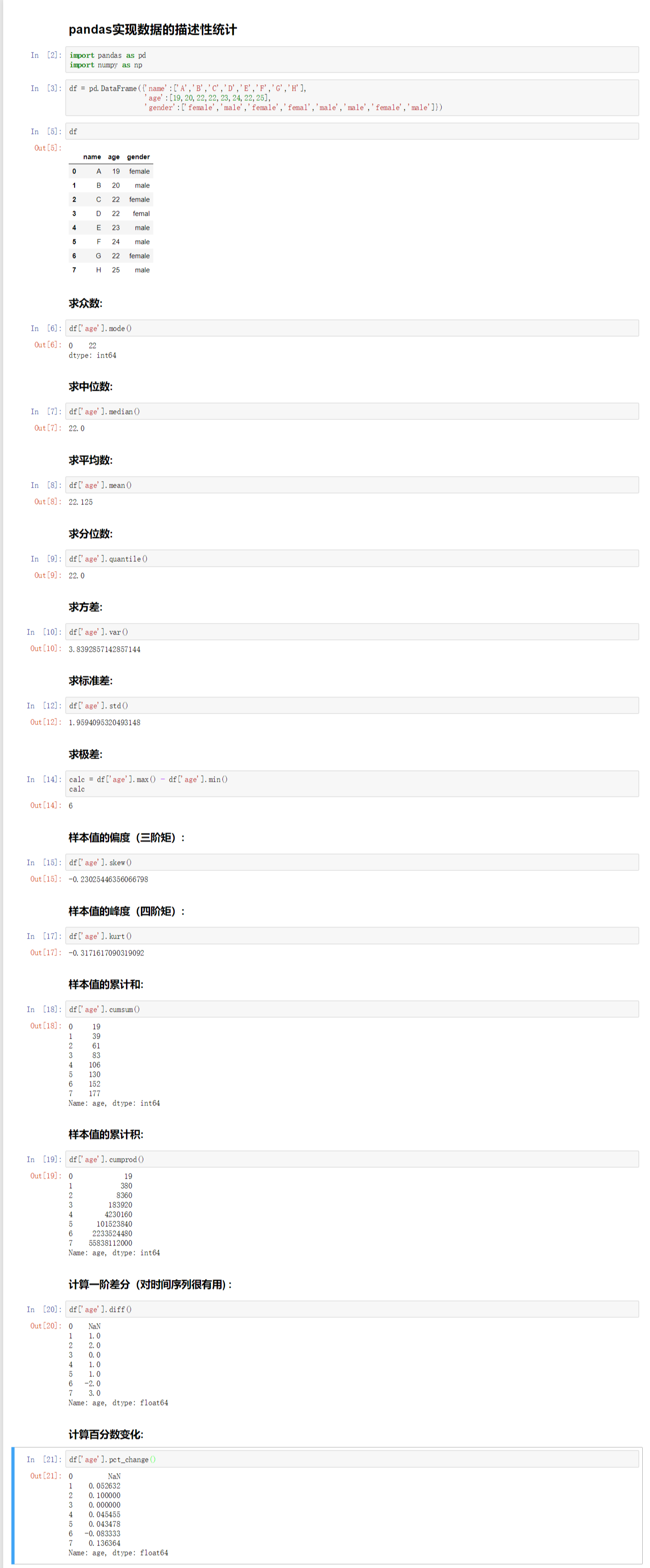
pandas简单实现描述性数据分析