Outline
用jupyter处理数据时,需要循环打印多个DataFrame,但打印出来的df看起来很难看;
想要的效果是比较规整美观的df展示,例如单独展示df时那样,是一个完整的table视图。
下面美化下jupyter notebook中for循环输出DataFrame
解决
解决前
for 循环打印DataFrame效果:

看起来很不舒服
解决后
for 循环打印DataFrame效果:
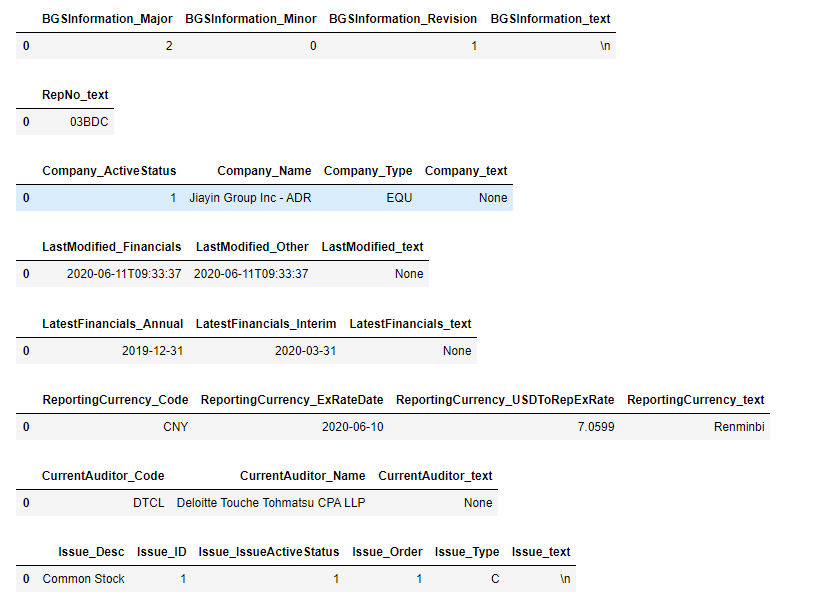
这下就舒服多了
解决方法
通过 from IPython.display import display 模块
代码中导入次模块,把print(df) 替换为 display(df)
from collections import Counter import xml.etree.ElementTree as ET from IPython.display import display from pandas.io.json import json_normalize # 需要解析的xml文件路径 path = '/data1/gaochao/refinitiv_sample/BGSBS02/BGSBS_03BDC.xml' tree = ET.parse(path) root = tree.getroot() iter_root = root.iter('BGSInformation') ret = [] def get_xml_content(iter_root): for node in iter_root: dic = node.attrib text = node.text if len(dic) == 0 and text == ' ': pass else: dic['text'] = text ret.append({node.tag: dic}) get_xml_content(node) get_xml_content(iter_root) def parse_data(): # 获取标签名重复次数 latest_ret = [] conters = Counter([list(i.keys())[0] for i in ret]) # 整合标签名只出现一次的 for r_dict in ret: # 查看当前dict的key出现几次,如果只出现1次直接加入new_ret current_key = list(r_dict.keys())[0] repeat_num = conters[current_key] if repeat_num == 1: latest_ret.append(r_dict) # 整理标签名重复的字典 for c in conters: # 查看当前dict的key出现几次,如果只出现1次直接加入new_ret current_key = c repeat_num = conters[current_key] if repeat_num != 1: # 出现几次,就去ret里拿几次 tem_list = [] for g in ret: if list(g.keys())[0] == current_key: tem_list.append(g[current_key]) else: continue latest_ret.append({current_key: tem_list}) return latest_ret def get_df(): # 生成DataFrame for p in parse_data(): d_key = list(p.keys())[0] d_value = p[d_key] if type(d_value) is list: df = json_normalize(p, d_key) df_columns = df.columns.tolist() new_columns = [d_key + '_' + column for column in df_columns] df.set_axis(new_columns, axis='columns', inplace=True) display(df) # print(df) else: tem_dict = {} dict_value = p[d_key] for k in dict_value: tem_dict[d_key+'_'+k] = dict_value[k] # print(json_normalize(tem_dict)) display(json_normalize(tem_dict)) get_df()