以下文章来源于Python猫 ,作者豌豆花下猫
偶然看到了 stackoverflow 上的一个问题,还挺有启发,故分享一下。
题目大意是:有从 A 到 F 的 5 个等级,现要判断某个数值(从 0 到 1 之间)所属的等级。举例,如数值 >= 0.9,则属于 A;若数值 >= 0.8,则属于 B;以此类推。
若使用 if-elif 语句,可能写成这样:
if scr >= 0.9:
print('A')
elif scr >= 0.8:
print('B')
elif scr >= 0.7:
print('C')
elif scr >= 0.6:
print('D')
else:
print('F')
此写法出现了很多重复的模式,不够简洁优雅。有什么更好的写法,来实现这个目的呢?
该问题下的回答挺多的,实现思路五花八门。我挑几个可读性比较好:
方法一:使用bisect模块(数字可调)

方法二:使用 zip() 与 next()

方法三:使用字典(仅适用于 Python 3.6 以上的有序字典)

还有其它几个回答,虽然都能实现数字分级的目的,但是其可读性要差很多,因为它们要么需要你作计算和推理,要么就是引入了额外的变量。
感兴趣的话,你可在这个地址查看全部答案:https://stackoverflow.com/questions/61030617/how-can-i-simplify-repetitive-if-elif-statements
纵观全部答案后,我认为还是使用bisect的方法最高效优雅,不愧是它获得了最高的赞同票。
这里简单分析下它的实现过程。
bisect是 Python 内置的标准库,实现了二分查找算法。所谓二分查找,也被称为“折半查找”(Binary Search),其基本思想是把有序排列的 n 个元素平均分成两半,然后将待查找的 x 与中间元素比较,若 x 小于中间元素,则将左半段二分,再将 x 与其中间元素比对,以此类推。
这是一个简单的图示例子:
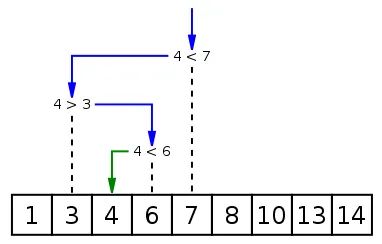
bisect库中的 bisect() 方法,查找元素 x 在一个升序序列中的插入点 i,使得插入点左侧的元素都小于等于 x,插入点右侧的元素都大于 x。
对照前面的例子:
from bisect import bisect
def grade(score, breakpoints=[60, 70, 80, 90], grades='FDCBA'):
i = bisect(breakpoints, score)
return grades[i]
可以化简成两部分:
-
bisect([60, 70, 80, 90], score),返回插入点的值。假如 score 是 59,计算得出插入点在 60 的左侧,而 Python 列表的索引值是以 0 开始,所以返回插入点的值为 0;假如 score 是 60,计算得出插入点在 60 的右侧,即返回索引值为 1。
-
'FDCBA'[i],返回索引值为 i 的字符。假如 i 是 0,得到“F”;假如 i 是 3,得到“B”……
二分查找算法是效率较高的算法,时间复杂度为 O(logn)。该题目的查找范围很小,所以时间效率差别不大。但是其写法称得上是 Pythonic,值得借鉴。
另外,再看看前面的方法三(使用字典),它的可读性很强,即顺次将 scr 与字典中的值比较(从高往低,即 0.9~0.5),以此得出对应的键值。(PS:它多分了一个“E”级,可去掉)
如果 Python 版本低于 3.6,则 grades.items() 会是无序的,将会破坏比较的顺序。为了兼容性,可以修改成 sorted(grades.items()):

这种写法没有引入额外的库,使用的 items() 与 sorted() 都是基础知识(相比于方法二的 zip() 与 next()),简单实用,也非常值得推荐。
不管怎么说,反复使用 if-elif 语句的判断方式是挺笨拙的,必须改进。文中列出的都是目前比较受认可的回答。