参考链接:
http://www.cnblogs.com/yixuan-xu/p/5858595.html
http://www.cnblogs.com/zf-blog/p/6139044.html
http://blog.csdn.net/zb1165048017/article/details/51355143?locationNum=6&fps=1
http://blog.csdn.net/zb1165048017/article/details/52980102
搭建一个完整的运行环境,不出错是很难的。尤其是对于我这样的小白。上面是我为搭建此环境参考的前辈博客链接。
这里做下总结,Windows7 64下搭建Caffe+python接口环境。(有些资源是前辈博客里的)
1.软件
Caffe下载链接(caffe-master):
https://github.com/Microsoft/caffe
百度云下载:http://pan.baidu.com/s/1hs8ngpA 密码:ith0
微软的Windows三方包(Nuget程序包):http://pan.baidu.com/s/1pKQKJJP 密码:2vzy
VS2013安装包链接:http://pan.baidu.com/s/1dF5OTWH 密码:16fn
anaconda2下载: 官网下载 https://repo.continuum.io/archive/Anaconda2-4.2.0-Windows-x86_64.exe
(千万要下载支持python2.7的anaconda2,不然后面会遇到找不到python27.lib,折腾了我一下午时间)
2.软件下载完成之后,开始一步一步来搭建环境。
(1)首先解压caffe-master.zip压缩包,打开caffe-master文件夹。在windows文件夹下复制CommonSettings.props.example文件,
重命名为CommonSettings.props文件。
 (2)在windows文件夹下找到Caffe.sln,并用VS2013打开->项目/解决方案。
在CommonSettings.props文件中修改相应内容:(下面Python路径一定要改为anaconda2的路径,图片中是anaconda3路径)
(2)在windows文件夹下找到Caffe.sln,并用VS2013打开->项目/解决方案。
在CommonSettings.props文件中修改相应内容:(下面Python路径一定要改为anaconda2的路径,图片中是anaconda3路径)

由于PC只有CPU没有GPU,修改第7、8行;想要支持Python接口,修改第13行,并添加Python路径,修改第48行 打开Caffe.sln出现了libcaffe和test_all加载失败。出现这个情况,原因可能和更改配置有关系,就将项目/解决方案关闭,重新打开就好了。

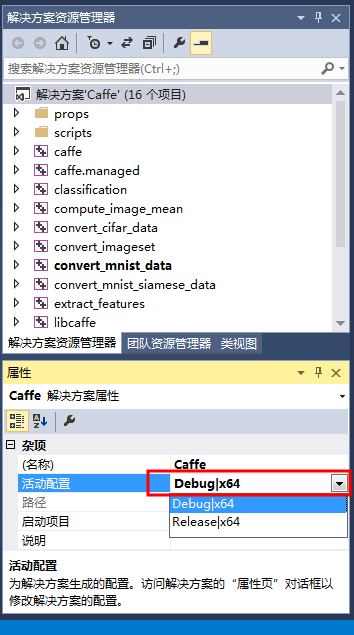
(3)配置文件修改好后,可以编译Caffe了。(有两种Debug和Release活动配置,都可以编译)
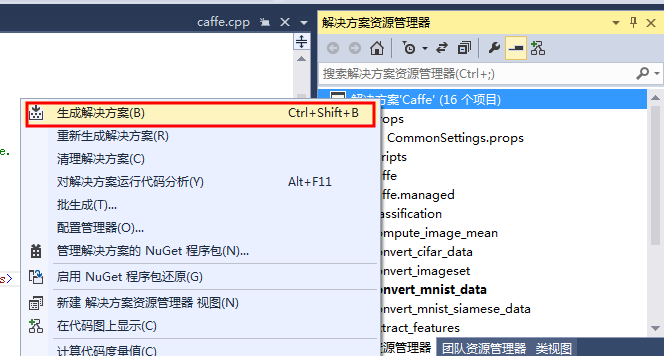
 这时,可能会弹出一个对话框,表示正在下载第三方包。
也可以这么做,在编译之前直接将NugetPackages文件夹(由于我们已经下载好NugetPackages),放在与Caffe-Master并列文件夹中。下载完成后,如图。
这时,可能会弹出一个对话框,表示正在下载第三方包。
也可以这么做,在编译之前直接将NugetPackages文件夹(由于我们已经下载好NugetPackages),放在与Caffe-Master并列文件夹中。下载完成后,如图。
 (4)设置一下运行项。
(4)设置一下运行项。

 (5)运行caffe.cpp,直接双击打开caffe.cpp,然后ctrl+F5直接编译。出现如下命令窗口说明编译成功。
(5)运行caffe.cpp,直接双击打开caffe.cpp,然后ctrl+F5直接编译。出现如下命令窗口说明编译成功。


3.用Caffe来测试mnist数据集
(1)去官网http://yann.lecun.com/exdb/mnist/下载数据集。将图里的数据都下载下来,备用。
 下载后解压到.caffe-masterdatamnist放在两个文件夹下。
下载后解压到.caffe-masterdatamnist放在两个文件夹下。

 (2)在caffe-master目录下,新建一个create_mnist.bat文件,写入下面代码:
(2)在caffe-master目录下,新建一个create_mnist.bat文件,写入下面代码:
.Buildx64Releaseconvert_mnist_data.exe .datamnistmnist_train_lmdb rain-images.idx3-ubyte .datamnistmnist_train_lmdb rain-labels.idx1-ubyte .examplesmnistmnist_train_lmdb echo. .Buildx64Releaseconvert_mnist_data.exe .datamnistmnist_test_lmdb 10k-images.idx3-ubyte .datamnistmnist_test_lmdb 10k-labels.idx1-ubyte .examplesmnistmnist_test_lmdb pause
双击该脚本运行,会在.caffe-masterexamplesmnist下生成相应的lmdb数据文件。

可能会遇到这个问题:
convert_mnist_data.cpp:103] Check failed: mdb_env_open(mdb_env, db_path, 0, 0664) == 0 (112 vs. 0) mdb_env_open failed
解决:在convert_mnist_data.cpp第103行代码中
CHECK_EQ(mdb_env_set_mapsize(mdb_env, 1099511627776), MDB_SUCCESS) //1TB
将数字改为107374182(100M),再重新生成一下convert_mnist_data.cpp
再次运行脚本,又出现这个问题:
convert_mnist_data.cpp:98] Check failed: _mkdir(db_path) == 0 (-1 vs. 0) mkdir .examplesmnistmnist_test_lmdbfailed
解决:前面虽然出现了错误,但数据文件夹同样生成了。在convert_mnist_data.cpp第98行代码中mkdir(db_path, 0744)表示为数据库创建文件夹。
如果文件夹已经存在,程序会报错退出。程序不会覆盖已有的数据库。已有的数据库如果不要了,需要手动删除。
(3)修改.caffe-masterexamplesmnistlenet_solver.prototxt 将最后一行改为solver_mode:CPU
修改.caffe-masterexamplesmnistlenet_train_test.prototxt,如下图。

(4)在.caffe-master目录下,新建train_mnist.bat,然后写入下面代码: .Buildx64Releasecaffe.exe train --solver=.examplesmnistlenet_solver.prototxt
pause
然后双击运行,就会开始训练,训练完毕后会得到相应的准确率和损失率。(用Debug配置运行时,大概要一个小时左右才能训练完) 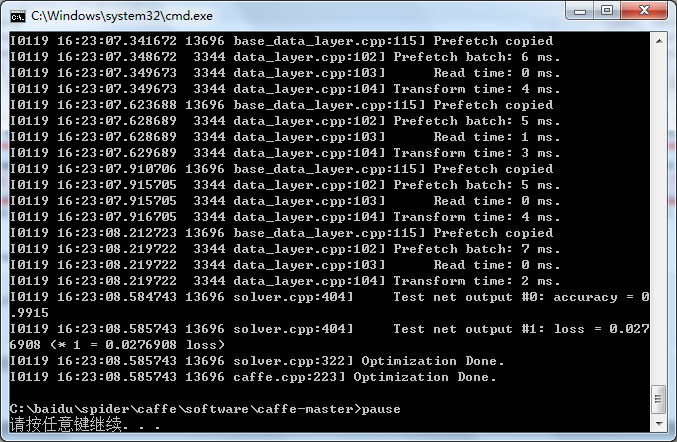
4.配置Python接口
(1)编译caffe接口,确认配置文件CommonSettings.props的参数中第13、48行已修改,如下。
<PythonSupport>true</PythonSupport>
<PythonDir>C:Anaconda2</PythonDir>
保存之后,去编译pycaffe,配置模式改为Release
 编译完成以后,会出现.caffe-masterBuildx64Releasepycaffe文件夹
编译完成以后,会出现.caffe-masterBuildx64Releasepycaffe文件夹
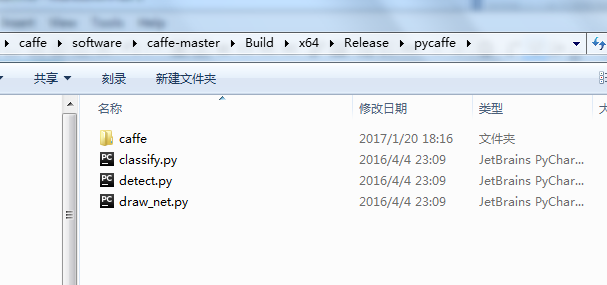 将caffe文件夹复制到Anaconda2安装目录下C:Anaconda2Libsite-packages
将caffe文件夹复制到Anaconda2安装目录下C:Anaconda2Libsite-packages
 (2)import caffe
由于我PC装了很多版本的Python,在cmd里指定下目录,调用C:Anaconda2里的Python.exe
再import caffe
(2)import caffe
由于我PC装了很多版本的Python,在cmd里指定下目录,调用C:Anaconda2里的Python.exe
再import caffe
 这时会出现 ImportError: No module named google.protobuf.internal 这个错误。
原因是没有protobuf这个模块。使用pip install protobuf(这个安装也需要注意,在cmd里指定下目录,
调用C:Anaconda2Scripts里的pip.exe 即pip.exe install protobuf).
这时会出现 ImportError: No module named google.protobuf.internal 这个错误。
原因是没有protobuf这个模块。使用pip install protobuf(这个安装也需要注意,在cmd里指定下目录,
调用C:Anaconda2Scripts里的pip.exe 即pip.exe install protobuf).

模块安装完成以后,再import caffe,就OK了。

(3)看一个实例
实现的是利用噪声生成一张真实图片,使用的实例是Texture Synthesis Using Convolutional Neural Networks
原文地址: http://blog.csdn.net/zb1165048017/article/details/52980102
github地址:https://github.com/leongatys/DeepTextures
下载github的程序,新建一个DeepTextures-master.py文件。
import glob
import sys
import os
from collections import OrderedDict
import caffe
import numpy as np
from matplotlib import pyplot as plt
import qtpy
base_dir1 = os.getcwd()
print base_dir1
sys.path.append(r'C:Anaconda2Libsite-packagesPyQt5')
print sys.path
#How to call custom moudles(DeepTextures-master)?
#1.find the site-packages folder in the python installation directory(.Libsite-packages)
#2.create a path file in this directory,such as myPython.pth
#3.open the myPython.pth,write the folder path for the user module(xxx.DeepTextures-master)
#4.restart python container(IDLE/command line)
#5.from DeepImageSynthesis import *
base_dir = r"C:aiduspidercaffePDFexampleDeepTextures-master"
from DeepImageSynthesis import *
VGGweights = os.path.join(base_dir,r'Modelsvgg_normalised.caffemodel')
VGGmodel = os.path.join(base_dir,r'ModelsVGG_ave_pool_deploy.prototxt')
imagenet_mean = np.array([ 0.40760392, 0.45795686, 0.48501961]) #mean for color channels (bgr)
im_dir = os.path.join(base_dir, 'Images/')
caffe.set_mode_cpu() #for cpu mode do 'caffe.set_mode_cpu()'
#if cpu mode we should not call,below 3 line of code is just for using GPU mode.
#gpu = 0
#caffe.set_mode_gpu()
#caffe.set_device(gpu)
#load source image
source_img_name = glob.glob1(im_dir,'pebbles.jpg')[0]
print source_img_name
source_img_org = caffe.io.load_image(im_dir + source_img_name)
im_size = 256.
[source_img,net] = load_image(im_dir + source_img_name, im_size,
VGGmodel, VGGweights, imagenet_mean,
show_img=True)
im_size = np.asarray(source_img.shape[-2:])
#l-bfgs parameters optimisation
maxiter = 2000
m = 20
#define layers to include in the texture model and weights w_l
tex_layers = ['pool4', 'pool3', 'pool2', 'pool1', 'conv1_1']
tex_weights = [1e9,1e9,1e9,1e9,1e9]
#pass image through the network and save the constraints on each layer
constraints = OrderedDict()
net.forward(data = source_img)
for l,layer in enumerate(tex_layers):
constraints[layer] = constraint([LossFunctions.gram_mse_loss],
[{'target_gram_matrix': gram_matrix(net.blobs[layer].data),
'weight': tex_weights[l]}])
#get optimisation bounds
bounds = get_bounds([source_img],im_size)
#generate new texture
result = ImageSyn(net, constraints, bounds=bounds,
callback=lambda x: show_progress(x,net),
minimize_options={'maxiter': maxiter,
'maxcor': m,
'ftol': 0, 'gtol': 0})
#match histogram of new texture with that of the source texture and show both images
new_texture = result['x'].reshape(*source_img.shape[1:]).transpose(1,2,0)[:,:,::-1]
new_texture = histogram_matching(new_texture, source_img_org)
plt.imshow(new_texture)
pltfigure()
plt.imshow(source_img_org)
调试可能遇到下面几个问题:
(1). F0122 16:28:32.843454 14000 common.cpp:75] Cannot use GPU in CPU-only Caffe
因为在前面caffe配置过程中,只配置了CPU模式。无法使用GPU,代码中已更改。
(2). This application failed to start because it could not find or load the Qt platform plugin "windows" in "".
由于没有配置系统的环境变量QT_QPA_PLATFORM_PLUGIN_PATH,找到pyqt的plugin目录
C:Anaconda2Libraryplugins(可能每个人安装的路径不同)
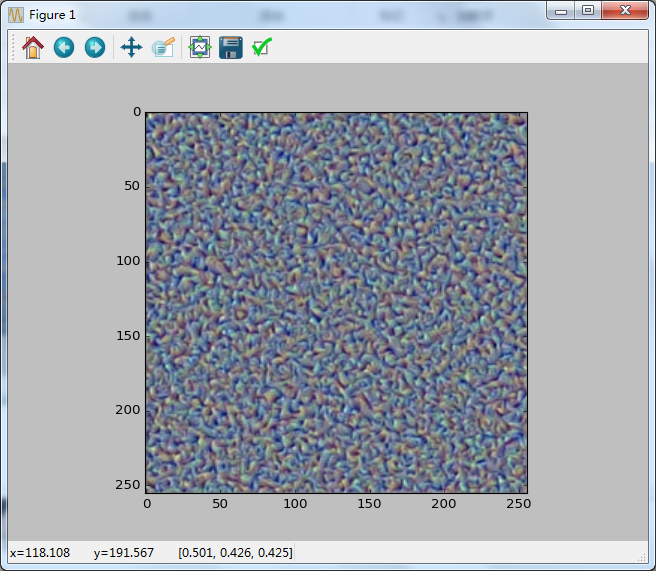
不知道是什么问题。结果却不敬人意,待续解决。