1.五大核心组件工作流程:

- 引擎(Scrapy)
用来处理整个系统的数据流处理, 触发事务(事务:函数调用、方法触发、类实例化)【框架核心】 - 调度器(Scheduler)
用来接受引擎发过来的请求, 【队列】压入队列中, 并在引擎再次请求的时候返回. 可以想像成一个URL(抓取网页的网址或者说是链接)的优先队列, 由它来决定下一个要抓取的网址是什么, 【过滤器】同时去除重复的网址- - 队列:先进先出的处理请求对象
- 过滤器:过滤掉重复请求对象
- - 队列:先进先出的处理请求对象
- 下载器(Downloader)
用于下载网页内容, 并将网页内容返回给spider(Scrapy下载器是建立在twisted这个高效的异步模型上的) - 爬虫(Spiders)
爬虫是主要干活的, 用于从特定的网页中提取自己需要的信息, 即所谓的实体(Item)。用户也可以从中提取出链接,让Scrapy继续抓取下一个页面 - 项目管道(Pipeline)
负责处理爬虫从网页中抽取的实体,主要的功能是持久化存储实体、验证实体的有效性、清除不需要的信息。当页面被爬虫解析后,将被发送到项目管道,并经过几个特定的次序处理数据。
2.请求传参
- 使用场景:如果使用scrapy爬取的数据没有在同一张页面中,则必须使用请求传参
- 编码流程:
- 需求:爬取的是首页中电影的名称和详情页中电影的简介(全站数据爬去)
- 基于起始url进行数据解析(parse)
- 解析数据
- 电影名称
- 详情页url
- 对详情页的url发起手动请求(指定的回调函数detail_parse),进行请求传参(meta),meta传递给detail_parse这个回调函数
- 封装一个其他页码对应url的一个通用的url模板
- 在for循环外部,手动对其他也的url进行手动请求发送(需要制定回调函数-->parse)
- 定义detail_parse回调方法,在其内部对电影的简介进行解析。解析玩不后,需要将解析到的电影名称和电影的简介封装到同一个item中
- 接受传递过来的item,并且将解析到的数据存储到item中,将item提交给管道
请求传参实例:爬取电影数据
# 1.spider文件
import scrapy
from moviePro.items import MovieproItem
class MovieSpider(scrapy.Spider):
name = 'movie'
# allowed_domains = ['www.xxx.com']
start_urls = ['https://www.4567tv.tv/frim/index1.html']
# 通用url模板适用于非第一页
url = 'https://www.4567tv.tv/frim/index1-%d.html'
page = 2
#电影名称(首页),简介(详情页)
def parse(self, response):
li_list = response.xpath('/html/body/div[1]/div/div/div/div[2]/ul/li')
for li in li_list:
name = li.xpath('./div/a/@title').extract_first()
detail_url = "https://www.4567tv.tv" + li.xpath('./div/a/@hreh').extract_first()
item = MovieproItem()
item['name'] = name
#对详情页的url发起get请求
# 请求传参:meta参数对应的字典就可以传递给请求对象中指定好的回调函数
yield scrapy.Request(url=detail_url,callback=self.detail_parse,meta={'item':item})
if self.page <= 5:
new_url = format(self.url%self.page)
self.page += 1
yield scrapy.Request(url=new_url,callback=self.parse)
# 解析详情页数据
def detail_parse(self,response):
# 回调函数内部通过response.meta就可以接受到请求传参传递过来的字典
item = response.meta['item']
desc = response.xpath('html/body/div[1]/div/div/div/div[2]/p[5]/span[2]/text()').extract_first()
item['desc'] = desc
yield item
------------------------------------------------------------------
# 2.items文件
import scrapy
class MovieproItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
name = scrapy.Field()
desc = scrapy.Field()
-------------------------------------------------------------------
# 3.管道文件
class MovieproPipeline(object):
def process_item(self, item, spider):
print(item)
return item
-----------------------------------------------------------------
# 4.setting文件
BOT_NAME = 'moviePro'
SPIDER_MODULES = ['moviePro.spiders']
NEWSPIDER_MODULE = 'moviePro.spiders'
USER_AGENT = 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/76.0.3809.132 Safari/537.36'
ROBOTSTXT_OBEY = False
LOG_LEVEL = 'ERROR'
ITEM_PIPELINES = {
'moviePro.pipelines.MovieproPipeline': 300,
}
3.中间件:下载中间件
框架图:
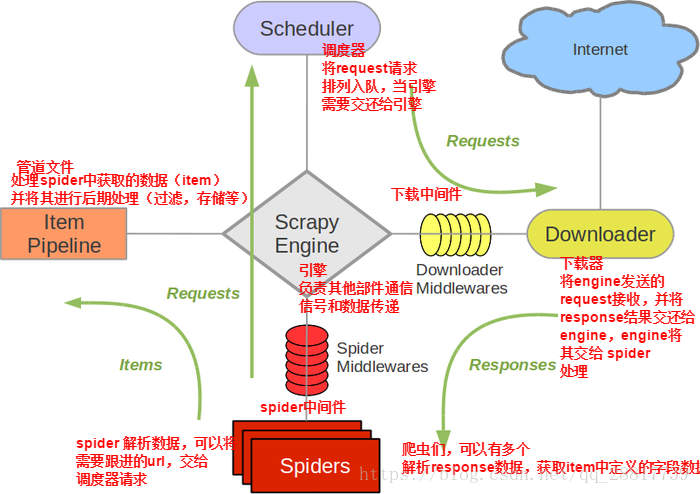
- 下载中间件的作用:批量拦截整个工程中发起的所有请求和相应
(1)引擎将请求传递给下载器过程中, 下载中间件可以对请求进行一系列处理。比如设置请求的 User-Agent,设置代理等
(2)在下载器完成将Response传递给引擎中,下载中间件可以对响应进行一系列处理。比如进行gzip解压等。
- 拦截请求:
- UA伪装:UA池
- 代理IP设置:代理池
- 拦截响应:
实例:
# 1.spider文件
import scrapy
class MiddleSpider(scrapy.Spider):
name = 'middle'
# allowed_domains = ['www.xxx.com']
start_urls = ['https://www.baidu.com/s?wd=ip']
def parse(self, response):
print(response)
----------------------------------------------------------------------------------------
# 2.items文件
import scrapy
class MiddlewearproItem(scrapy.Item):
pass
----------------------------------------------------------------------------------------
# 3.middlewares中间件文件
from scrapy import signals
import random
# 批量拦截所有的请求和相应
class MiddlewearproDownloaderMiddleware(object):
# UA池
user_agent_list = [
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.1 "
"(KHTML, like Gecko) Chrome/22.0.1207.1 Safari/537.1",
"Mozilla/5.0 (X11; CrOS i686 2268.111.0) AppleWebKit/536.11 "
"(KHTML, like Gecko) Chrome/20.0.1132.57 Safari/536.11",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.6 "
"(KHTML, like Gecko) Chrome/20.0.1092.0 Safari/536.6",
"Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.6 "
"(KHTML, like Gecko) Chrome/20.0.1090.0 Safari/536.6",
"Mozilla/5.0 (Windows NT 6.2; WOW64) AppleWebKit/537.1 "
"(KHTML, like Gecko) Chrome/19.77.34.5 Safari/537.1",
"Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/536.5 "
"(KHTML, like Gecko) Chrome/19.0.1084.9 Safari/536.5",
"Mozilla/5.0 (Windows NT 6.0) AppleWebKit/536.5 "
"(KHTML, like Gecko) Chrome/19.0.1084.36 Safari/536.5",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.3 "
"(KHTML, like Gecko) Chrome/19.0.1063.0 Safari/536.3",
"Mozilla/5.0 (Windows NT 5.1) AppleWebKit/536.3 "
"(KHTML, like Gecko) Chrome/19.0.1063.0 Safari/536.3",
"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_8_0) AppleWebKit/536.3 "
"(KHTML, like Gecko) Chrome/19.0.1063.0 Safari/536.3",
"Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.3 "
"(KHTML, like Gecko) Chrome/19.0.1062.0 Safari/536.3",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.3 "
"(KHTML, like Gecko) Chrome/19.0.1062.0 Safari/536.3",
"Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.3 "
"(KHTML, like Gecko) Chrome/19.0.1061.1 Safari/536.3",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.3 "
"(KHTML, like Gecko) Chrome/19.0.1061.1 Safari/536.3",
"Mozilla/5.0 (Windows NT 6.1) AppleWebKit/536.3 "
"(KHTML, like Gecko) Chrome/19.0.1061.1 Safari/536.3",
"Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.3 "
"(KHTML, like Gecko) Chrome/19.0.1061.0 Safari/536.3",
"Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/535.24 "
"(KHTML, like Gecko) Chrome/19.0.1055.1 Safari/535.24",
"Mozilla/5.0 (Windows NT 6.2; WOW64) AppleWebKit/535.24 "
"(KHTML, like Gecko) Chrome/19.0.1055.1 Safari/535.24"
]
# 代理池
PROXY_http = [
'153.180.102.104:80',
'195.208.131.189:56055',
]
PROXY_https = [
'120.83.49.90:9000',
'95.189.112.214:35508',
]
# 拦截正常请求:request就是该方法拦截到的请求,spider就是爬虫类实例化的一个对象
def process_request(self, request, spider):
print('this is process_request')
# 设置UA伪装
request.headers['User-Agent'] = random.choice(self.user_agent_list)
return None
# 拦截所有的响应:request是被拦截到的response对应的请求,spider就是爬虫类实例化的一个对象
def process_response(self, request, response, spider):
return response
# 拦截发生异常的请求对象
def process_exception(self, request, exception, spider):
print('this is process_exception')
# 代理IP的设定
if request.url.split(':')[0] == 'http':
request.meta['proxy'] = random.choice(self.PROXY_http)
else:
request.meta['proxy'] = random.choice(self.PROXY_https)
# 将修正后的请求对象重新进行请求发送
return request
----------------------------------------------------------------------------------------
# 4.pipelines文件
class MiddlewearproPipeline(object):
def process_item(self, item, spider):
return item
----------------------------------------------------------------------------------------
# 5.setting文件
BOT_NAME = 'MiddlewearPro'
SPIDER_MODULES = ['MiddlewearPro.spiders']
NEWSPIDER_MODULE = 'MiddlewearPro.spiders'
LOG_LEVEL = 'ERROR'
USER_AGENT = 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/76.0.3809.132 Safari/537.36'
ROBOTSTXT_OBEY = False
# 开启中间件
DOWNLOADER_MIDDLEWARES = {
'MiddlewearPro.middlewares.MiddlewearproDownloaderMiddleware': 543,
}