Zookeeper 源码(六)Leader-Follower-Observer
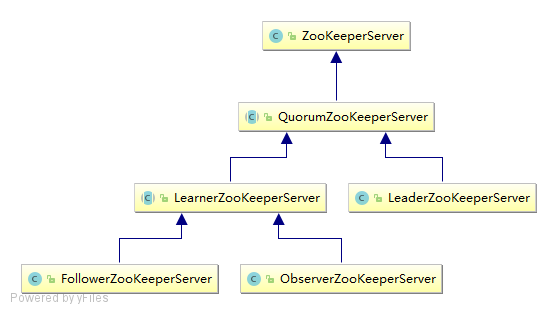
上一节介绍了 Leader 选举的全过程,本节讲解一下 Leader-Follower-Observer 服务器的三种角色。经过 Leader 选举后各服务器都能确定自己的角色,下一步就是初始化各自的角色。
先回顾一下【QuorumPeer】的 run 方法选举结束后创建对应的角色:
case OBSERVING:
setObserver(makeObserver(logFactory));
observer.observeLeader();
break;
case FOLLOWING:
setFollower(makeFollower(logFactory));
follower.followLeader();
break;
case LEADING:
// 3.1 初始化 Leader 对象
setLeader(makeLeader(logFactory));
// 3.2 lead 线程在这里阻塞
leader.lead();
setLeader(null);
break;
一、Leader
Leader 服务器是整个 Zookeeper 集群工作机制中的核心,其主要工作有以下两个。
- 事务请求的唯一调度和处理者,保证集群事务处理的顺序性。
- 集群内部各服务器的调度者
(1) Leader 初始化 【Leader】
protected Leader makeLeader(FileTxnSnapLog logFactory) throws IOException {
return new Leader(this, new LeaderZooKeeperServer(logFactory, this, this.zkDb));
}
// Leader 启动时启动 2888 的端口,用于服务器内部通信(如数据同步等)
Leader(QuorumPeer self,LeaderZooKeeperServer zk) throws IOException {
this.self = self;
try {
if (self.getQuorumListenOnAllIPs()) {
ss = new ServerSocket(self.getQuorumAddress().getPort());
} else {
ss = new ServerSocket();
}
ss.setReuseAddress(true);
if (!self.getQuorumListenOnAllIPs()) {
ss.bind(self.getQuorumAddress());
}
} catch (BindException e) {
// 省略...
}
this.zk = zk;
}
(2) lead 【Leader】
void lead() throws IOException, InterruptedException {
// 1. 恢复本地数据
zk.loadData();
// 2. 启动 lead 端口的监听线程,专门用来监听新的 follower
cnxAcceptor = new LearnerCnxAcceptor();
cnxAcceptor.start();
// 3. 启动服务
startZkServer();
while (true) {
// 省略...
}
}
(3) LearnerCnxAcceptor 【Leader】
follower 连上 leader 后,此时 leader 会为每个 follower 启动单独 IO 线程,请看 LearnerCnxAcceptor 代码
class LearnerCnxAcceptor extends ZooKeeperCriticalThread {
private volatile boolean stop = false;
@Override
public void run() {
while (!stop) {
Socket s = ss.accept();
// 读超时设为 initLimit 时间
s.setSoTimeout(self.tickTime * self.initLimit);
s.setTcpNoDelay(nodelay);
// 为每个 follower 启动单独线程,处理 IO
LearnerHandler fh = new LearnerHandler(s, Leader.this);
fh.start();
}
}
LearnerHandler 持有 Leader 与 Learner 的 Socket 对象,专门用来处理服务器之间的通信。
(4) startZkServer 【Leader】
private synchronized void startZkServer() {
// 省略...
zk.startup();
// 省略...
}
(4) startup 【LeaderZooKeeperServer】
LeaderZooKeeperServer 继承自 ZooKeeperServer,重写了 startup 和 setupRequestProcessors,这里重点关注 Leader 服务器的请求处理链。
@Override
public synchronized void startup() {
super.startup();
if (containerManager != null) {
containerManager.start();
}
}
/**
* Leader 服务器的请求处理链
* LeaderRequestProcessor -> PrepRequestProcessor -> ProposalRequestProcessor ->
* CommitProcessor -> ToBeAppliedRequestProcessor -> FinalRequestProcessor
*/
@Override
protected void setupRequestProcessors() {
RequestProcessor finalProcessor = new FinalRequestProcessor(this);
RequestProcessor toBeAppliedProcessor = new Leader.ToBeAppliedRequestProcessor(finalProcessor, getLeader());
commitProcessor = new CommitProcessor(toBeAppliedProcessor,
Long.toString(getServerId()), false,
getZooKeeperServerListener());
commitProcessor.start();
ProposalRequestProcessor proposalProcessor = new ProposalRequestProcessor(this, commitProcessor);
proposalProcessor.initialize();
prepRequestProcessor = new PrepRequestProcessor(this, proposalProcessor);
prepRequestProcessor.start();
firstProcessor = new LeaderRequestProcessor(this, prepRequestProcessor);
setupContainerManager();
}
(1) PrepRequestProcessor 请求预处理器。在Zookeeper中,那些会改变服务器状态的请求称为事务请求(创建节点、更新数据、删除节点、创建会话等),PrepRequestProcessor能够识别出当前客户端请求是否是事务请求。对于事务请求,PrepRequestProcessor处理器会对其进行一系列预处理,如创建请求事务头、事务体、会话检查、ACL检查和版本检查等。
(2) ProposalRequestProcessor 事务投票处理器。Leader服务器事务处理流程的发起者,对于非事务性请求,ProposalRequestProcessor会直接将请求转发到CommitProcessor处理器,不再做任何处理,而对于事务性请求,处理将请求转发到CommitProcessor外,还会根据请求类型创建对应的Proposal提议,并发送给所有的Follower服务器来发起一次集群内的事务投票。同时,ProposalRequestProcessor还会将事务请求交付给SyncRequestProcessor进行事务日志的记录。
(3) CommitProcessor 事务提交处理器。对于非事务请求,该处理器会直接将其交付给下一级处理器处理;对于事务请求,其会等待集群内针对Proposal的投票直到该Proposal可被提交,利用CommitProcessor,每个服务器都可以很好地控制对事务请求的顺序处理。
(4) ToBeCommitProcessor 该处理器有一个toBeApplied队列,用来存储那些已经被CommitProcessor处理过的可被提交的Proposal。其会将这些请求交付给FinalRequestProcessor处理器处理,待其处理完后,再将其从toBeApplied队列中移除。
(5) FinalRequestProcessor 用来进行客户端请求返回之前的操作,包括创建客户端请求的响应,针对事务请求,该处理还会负责将事务应用到内存数据库中去。
(6) SyncRequestProcessor 事务日志记录处理器。用来将事务请求记录到事务日志文件中,同时会触发Zookeeper进行数据快照。
(7) AckRequestProcessor 负责在SyncRequestProcessor完成事务日志记录后,向Proposal的投票收集器发送ACK反馈,以通知投票收集器当前服务器已经完成了对该Proposal的事务日志记录。
二、Follower
Follower 的初始化与 Leader 类似,重点关注一下 Follower 的请求处理链。
void followLeader() throws InterruptedException {
// 省略...
try {
InetSocketAddress addr = findLeader();
try {
connectToLeader(addr);
// 省略...
syncWithLeader(newEpochZxid);
QuorumPacket qp = new QuorumPacket();
while (self.isRunning()) {
readPacket(qp);
processPacket(qp);
}
} catch (Exception e) {
// 省略...
}
}
}
/**
* Follower 服务器的请求处理链
* 1. FollowerRequestProcessor -> CommitProcessor -> FinalRequestProcessor
* 2. SyncRequestProcessor -> SendAckRequestProcessor
*/
@Override
protected void setupRequestProcessors() {
RequestProcessor finalProcessor = new FinalRequestProcessor(this);
commitProcessor = new CommitProcessor(finalProcessor,
Long.toString(getServerId()), true, getZooKeeperServerListener());
commitProcessor.start();
firstProcessor = new FollowerRequestProcessor(this, commitProcessor);
((FollowerRequestProcessor) firstProcessor).start();
syncProcessor = new SyncRequestProcessor(this,
new SendAckRequestProcessor((Learner)getFollower()));
syncProcessor.start();
}
(1) FollowerRequestProcessor 其用作识别当前请求是否是事务请求,若是,那么Follower就会将该请求转发给Leader服务器,Leader服务器是在接收到这个事务请求后,就会将其提交到请求处理链,按照正常事务请求进行处理。
(2) SendAckRequestProcessor其承担了事务日志记录反馈的角色,在完成事务日志记录后,会向Leader服务器发送ACK消息以表明自身完成了事务日志的记录工作。
参考:
- 《Zookeeper源码分析之六 Leader/Follower初始化》:https://blog.csdn.net/haihongazar/article/details/52709244
- 《zookeeper源码分析之五服务端(集群leader)处理请求流程》:https://www.cnblogs.com/davidwang456/p/5004599.html
- 从 Paxos 到 Zookeeper : 分布式一致性原理与实践
每天用心记录一点点。内容也许不重要,但习惯很重要!