什么是缓存
缓存就是内存中的一个对象,用于对数据库查询结果的保存,用于减少与数据库的交互次数从而降低数据库的压力,进而提高响应速度。
MyBatis 缓存机制原理
Mybatis 缓存机制原理是将第一次从数据库 SQL 查询的结果数据保存到缓存(内存中),当下一次 SQL 查询和第一次相同,如果缓存中有数据则直接获取,而不用再从数据库获取,从而减少数据库访问频率,大大提升数据库性能。
MyBatis 一级缓存
一级缓存是 Sqlssion 级别的缓存。
在操作数据库时需要构造 SqlSession 对象,在对象中有一个(内存区域)数据结构(HashMap)用于存储缓存数据。
不同的 SqlSession 对象之间的缓存数据是互相不影响的。
一级缓存的作用范围是同一个 SqlSession 对象,在同一个 SqlSession 对象中再次执行相同的 SQL 语句,第一次执行完毕会将数据库中查询的数据写到缓存,第二次会从缓存中获取数据,不必再从数据库中查询,从而提升查询效率。当 SqlSession 对象释放后,该 SqlSession 对象中的一级缓存也就不存在了。
MyBatis 默认开启一级缓存,并且无法关闭
一级缓存工作原理如下:
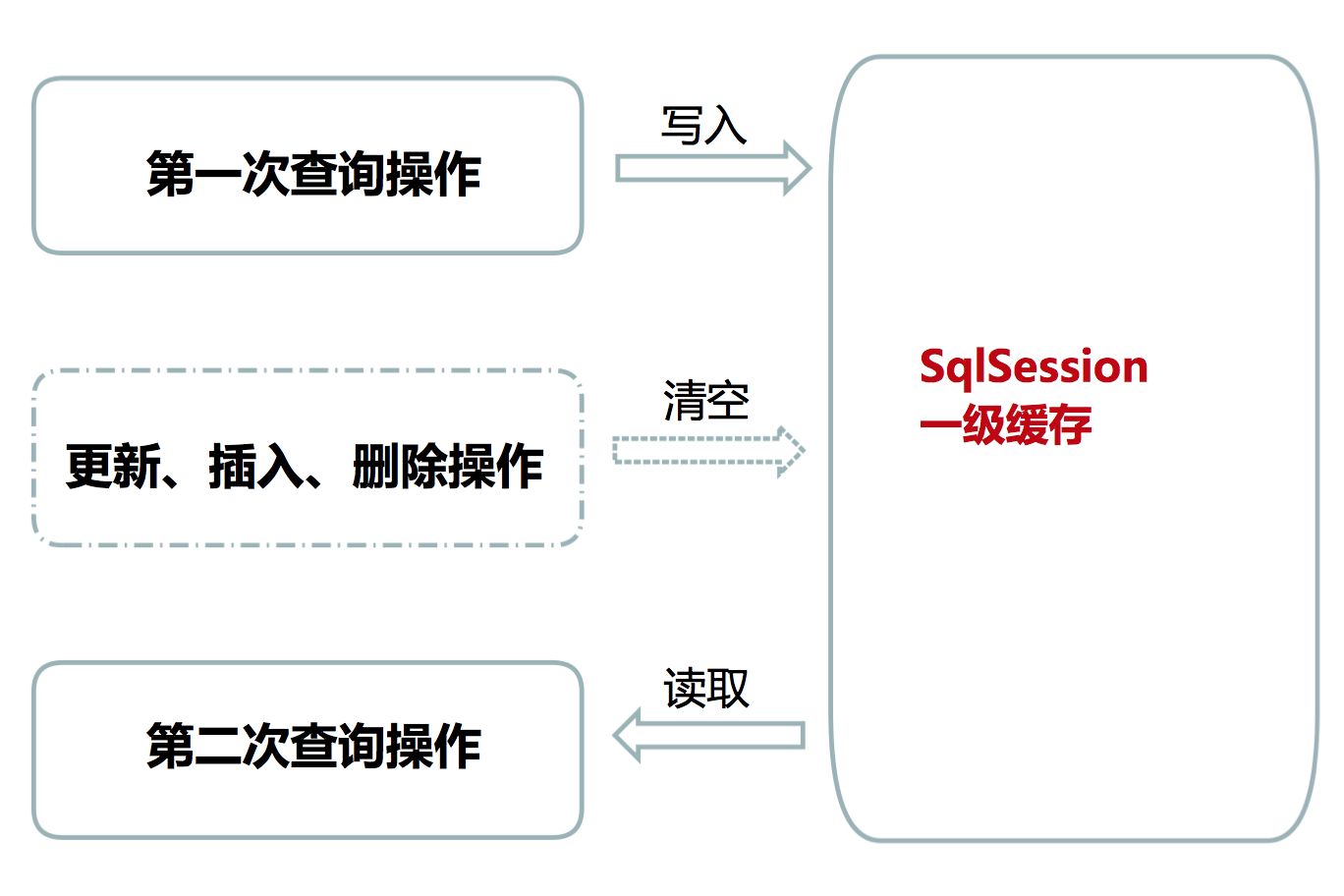
一级缓存满足条件如下:
- 同一个 SqlSession 对象
- 相同的 SQL 语句和参数
注:使用 SqlSession.clearCache( ) 方法可以强制清除一级缓存
测试 MyBatis 一级缓存
既然每个 SqlSession 都会有自己的一个缓存,那么我们用同一个 SqlSession 是不是就能感受到一级缓存的存在呢?调用多次 getMapper 方法,生成对应的SQL语句,判断每次SQL语句是从缓存中取还是对数据库进行操作,下面的例子来证明一下
@Test
public void cacheTest() {
List<UserEntity> userEntities = userMapper.selectUserByAge(20);
System.out.println(userEntities);
List<UserEntity> userEntities2 = userMapper.selectUserByAge(20);
System.out.println(userEntities2);
List<UserEntity> userEntities3 = userMapper.selectUserByAge(20);
System.out.println(userEntities3);
}
执行测试,输出结果如下:
2020-08-10 16:14:44,790 [main] [mapper.UserMapper.selectUserByAge]-[DEBUG] ==> Preparing: select * from tb_user where age > ?
2020-08-10 16:14:44,837 [main] [mapper.UserMapper.selectUserByAge]-[DEBUG] ==> Parameters: 20(Integer)
2020-08-10 16:14:44,884 [main] [mapper.UserMapper.selectUserByAge]-[DEBUG] <== Total: 7
[UserEntity{id=1, userName='张三', password='123456', name='张三', age=22, sex=1, birthday=Sun Sep 02 00:00:00 IRKST 1990, created='2020-06-17 09:30:58.0', updated='2020-06-17 09:30:58.0', interests=null}
[UserEntity{id=1, userName='张三', password='123456', name='张三', age=22, sex=1, birthday=Sun Sep 02 00:00:00 IRKST 1990, created='2020-06-17 09:30:58.0', updated='2020-06-17 09:30:58.0', interests=null}
可以看到,连续执行三次查询 SQL 语句,但只打印了一条 SQL 语句,其他两条 SQL 语句都是从缓存中查询的,所以它们生成了相同的 UsereEntity 对象。
接着我在第一条和第二条 SQL语句 之间插入更新的 SQL 语句,代码如下:
@Test
public void cacheTest() {
List<UserEntity> userEntities = userMapper.selectUserByAge(20);
System.out.println(userEntities);
int result = userMapper.updateUser(1,"张三");
sqlSession.commit();
List<UserEntity> userEntities2 = userMapper.selectUserByAge(20);
System.out.println(userEntities2);
}
执行测试,结果如下:
020-08-10 16:20:47,384 [main] [mapper.UserMapper.selectUserByAge]-[DEBUG] ==> Preparing: select * from tb_user where age > ?
2020-08-10 16:20:47,431 [main] [mapper.UserMapper.selectUserByAge]-[DEBUG] ==> Parameters: 20(Integer)
2020-08-10 16:20:47,478 [main] [mapper.UserMapper.selectUserByAge]-[DEBUG] <== Total: 7
[UserEntity{id=1, userName='张三', password='123456', name='张三', age=22, sex=1, birthday=Sun Sep 02 00:00:00 IRKST 1990, created='2020-06-17 09:30:58.0', updated='2020-06-17 09:30:58.0', interests=null}
2020-08-10 16:20:47,478 [main] [mapper.UserMapper.updateUser]-[DEBUG] ==> Preparing: update tb_user set name=? where id=?
2020-08-10 16:20:47,478 [main] [mapper.UserMapper.updateUser]-[DEBUG] ==> Parameters: 张三(String), 1(Integer)
2020-08-10 16:20:47,478 [main] [mapper.UserMapper.updateUser]-[DEBUG] <== Updates: 1
2020-08-10 16:20:47,493 [main] [mapper.UserMapper.selectUserByAge]-[DEBUG] ==> Preparing: select * from tb_user where age > ?
2020-08-10 16:20:47,493 [main] [mapper.UserMapper.selectUserByAge]-[DEBUG] ==> Parameters: 20(Integer)
2020-08-10 16:20:47,509 [main] [mapper.UserMapper.selectUserByAge]-[DEBUG] <== Total: 7
[UserEntity{id=1, userName='张三', password='123456', name='张三', age=22, sex=1, birthday=Sun Sep 02 00:00:00 IRKST 1990, created='2020-06-17 09:30:58.0', updated='2020-06-17 09:30:58.0', interests=null},
[UserEntity{id=1, userName='张三', password='123456', name='张三', age=22, sex=1, birthday=Sun Sep 02 00:00:00 IRKST 1990, created='2020-06-17 09:30:58.0', updated='2020-06-17 09:30:58.0', interests=null},
可以看到,在两次查询 SQL 语句中使用插入 SQL 语句,会对一级缓存进行刷新,会导致一级缓存失效。
我们知道一级缓存就是 SqlSession 级别的缓存,而同一个 SqlSession 会有相同的一级缓存,那么使用不同的 SqlSession 是不是会对一级缓存产生影响呢?
@Test
public void cacheTest() {
List<UserEntity> userEntities = userMapper.selectUserByAge(20);
System.out.println(userEntities);
UserMapper userMapper2
= sqlSessionFactory.openSession().getMapper(UserMapper.class);
List<UserEntity> userEntities2 = userMapper2.selectUserByAge(20);
System.out.println(userEntities2);
执行测试,结果如下:
2020-08-10 16:26:36,243 [main] [mapper.UserMapper.selectUserByAge]-[DEBUG] ==> Preparing: select * from tb_user where age > ?
2020-08-10 16:26:36,290 [main] [mapper.UserMapper.selectUserByAge]-[DEBUG] ==> Parameters: 20(Integer)
2020-08-10 16:26:36,322 [main] [mapper.UserMapper.selectUserByAge]-[DEBUG] <== Total: 7
[UserEntity{id=1, userName='张三', password='123456', name='张三', age=22, sex=1, birthday=Sun Sep 02 00:00:00 IRKST 1990, created='2020-06-17 09:30:58.0', updated='2020-06-17 09:30:58.0', interests=null}
2020-08-10 16:26:36,337 [main] [mapper.UserMapper.selectUserByAge]-[DEBUG] ==> Preparing: select * from tb_user where age > ?
2020-08-10 16:26:36,337 [main] [mapper.UserMapper.selectUserByAge]-[DEBUG] ==> Parameters: 20(Integer)
2020-08-10 16:26:36,353 [main] [mapper.UserMapper.selectUserByAge]-[DEBUG] <== Total: 7
[UserEntity{id=1, userName='张三', password='123456', name='张三', age=22, sex=1, birthday=Sun Sep 02 00:00:00 IRKST 1990, created='2020-06-17 09:30:58.0', updated='2020-06-17 09:30:58.0', interests=null}
上面代码使用了不同的 SqlSession 对同一个 SQL 语句执行了相同的查询操作,却对数据库执行了两次相同的查询操作,生成了不同的 UserEnity 对象,由此可见,不同的 SqlSession 是肯定会对一级缓存产生影响的。
//手动清除一级缓存方法
sqlSession.clearCache();
在开启一级缓存时,当有两个 SqlSession 对象存在,一个用于查询数据,一个用于更新数据,如果查询和更新是同一张表的相同数据,这时可能会出现数据脏读,而解决办法是查询时手动清空缓存。
MyBatis 二级缓存
二级缓存是 Mapper 级别的缓存。
多个 SqlSession 对象 SQL 语句查询数据库结果会存放二级缓存区域,而多个SqlSession对象可以共用二级缓存。
二级缓存是多个 SqlSesion 对象共用的。
其作用范围是 Mapper 的同一个 namespace ,不同的 SqlSession 对象再次执行相同 namepace 下的 SQL 语句,第一次执行会将数据库中查询结果数据存储到二级缓存中,第二次会从二级缓存中获取数据,而不再从数据库中获取,从而提高查询效率。
MyBatis 二级缓存默认关闭,需要手动开启二级缓存。
MyBatis 的二级缓存是 Mapper 范围级别,除了在 MyBatis 环境配置 mybatis-config.xml 设置二级缓存总开关,还要在具体的 mapper.xml 中加入
步骤如下:
-
mybatis-config.xml 设置二级缓存总开关
<settings> <!-- 开启二级缓存 --> <setting name="cacheEnabled" value="true" /> </settings> -
在具体的 mapper.xml 中加扩
标签 <mapper> <!--开启二级缓存(表示对哪个mapper 开启缓存)--> <cache /> </mapper>设置 cache 标签的属性
cache 标签有多个属性
-
eviction: 缓存回收策略
- LRU - 最近最少回收,移除最长时间不被使用的对象(默认)
- FIFO - 先进先出,按照缓存进入的顺序来移除它们
- SOFT - 软引用,移除基于垃圾回收器状态和软引用规则的对象
- WEAK - 弱引用,更积极的移除基于垃圾收集器和弱引用规则的对象
-
flushinterval:缓存刷新间隔,缓存多长时间刷新一次,默认不清空,设置一个毫秒值
-
readOnly: 是否只读;true 只读,MyBatis 认为所有从缓存中获取数据的操作都是只读操作,不会修改数据。MyBatis 为了加快获取数据,直接就会将数据在缓存中的引用交给用户。不安全,速度快。读写(默认):MyBatis 觉得数据可能会被修改
-
size : 缓存存放多少个元素
-
type: 指定自定义缓存的全类名(实现Cache 接口即可)
-
blocking: 若缓存中找不到对应的key,是否会一直blocking,直到有对应的数据进入缓存。
注:开启二级缓存后,MyBatis要求返回的实体类对象必须是可序列化的
开启二级缓存后,在不同 SqlSesion 下执行相同查询 SQL 语句,代码如下:
@Test public void cacheTest() { List<UserEntity> userEntities = userMapper.selectUserByAge(20); System.out.println(userEntities); sqlSession.commit(); //提交SQL语句到数据库返回查询结果 UserMapper userMapper2 = sqlSessionFactory.openSession().getMapper(UserMapper.class); List<UserEntity> userEntities2 = userMapper2.selectUserByAge(20); System.out.println(userEntities2); }执行测试,结果如下 :
-
2020-08-10 16:41:43,119 [main] [mapper.UserMapper]-[DEBUG] Cache Hit Ratio [mapper.UserMapper]: 0.0
2020-08-10 16:41:43,509 [main] [mapper.UserMapper.selectUserByAge]-[DEBUG] ==> Preparing: select * from tb_user where age > ?
2020-08-10 16:41:43,572 [main] [mapper.UserMapper.selectUserByAge]-[DEBUG] ==> Parameters: 20(Integer)
2020-08-10 16:41:43,603 [main] [mapper.UserMapper.selectUserByAge]-[DEBUG] <== Total: 7
[UserEntity{id=1, userName='张三', password='123456', name='张三', age=22, sex=1, birthday=Sun Sep 02 00:00:00 IRKST 1990, created='2020-06-17 09:30:58.0', updated='2020-06-17 09:30:58.0', interests=null},
2020-08-10 16:41:43,634 [main] [mapper.UserMapper]-[DEBUG] Cache Hit Ratio [mapper.UserMapper]: 0.5
[UserEntity{id=1, userName='张三', password='123456', name='张三', age=22, sex=1, birthday=Sun Sep 02 00:00:00 IRKST 1990, created='2020-06-17 09:30:58.0', updated='2020-06-17 09:30:58.0', interests=null},
通过结果可以得知,首次执行的SQL语句是从数据库中查询得到的结果,然后第一个 SqlSession 执行提交,第二个 SqlSession 执行相同的查询后是从二级缓存中查取的。
值得注意的是,SqlSession 在未提交的时候,SQL 语句产生的查询结果还没有放入二级缓存中,这个时候 SqlSession2 在查询的时候是感受不到二级缓存的存在的。
与一级缓存一样,更新操作很可能对二级缓存造成影响。
多表操作对二级缓存也会产生影响,如下:
GameMapper.java 文件添加一个接口方法,代码如下:
@Update("update tb_game set name = #{name} where id = #{id}")
public int updateGameNameById(@Param("name") String name, @Param("id") int id);
在测试 MyBatisTest.java中添加一个测试方法,代码 如下:
@Test
public void cacheJoinTableTest() {
GameEntity gameEntity = gameMapper.selectGameByName("英雄联盟");
System.out.println(gameEntity);
SqlSession sqlSession2 = sqlSessionFactory.openSession();
GameMapper gameMapper2 = sqlSession2.getMapper(GameMapper.class);
gameMapper2.updateGameNameById("王者荣耀",1);
sqlSession2.commit();
gameEntity = gameMapper.selectGameByName("英雄联盟");
System.out.println(gameEntity);
}
执行测试,结果如下:
2020-08-10 22:58:51,867 [main] [mapper.GameMapper]-[DEBUG] Cache Hit Ratio [mapper.GameMapper]: 0.0
2020-08-10 22:58:52,289 [main] [mapper.GameMapper.selectGameByName]-[DEBUG] ==> Preparing: select * from tb_game where name =?
2020-08-10 22:58:52,320 [main] [mapper.GameMapper.selectGameByName]-[DEBUG] ==> Parameters: 英雄联盟(String)
2020-08-10 22:58:52,367 [main] [mapper.GameMapper]-[DEBUG] Cache Hit Ratio [mapper.GameMapper]: 0.0
2020-08-10 22:58:52,367 [main] [mapper.GameMapper.selectAccountById]-[DEBUG] ====> Preparing: select * from tb_account where id=?
2020-08-10 22:58:52,367 [main] [mapper.GameMapper.selectAccountById]-[DEBUG] ====> Parameters: 1(Integer)
2020-08-10 22:58:52,367 [main] [mapper.GameMapper.selectAccountById]-[DEBUG] <==== Total: 1
2020-08-10 22:58:52,367 [main] [mapper.GameMapper.selectGameByName]-[DEBUG] <== Total: 1
GameEntity{id=1, name='英雄联盟', type='MOBA', operator='腾讯游戏', accounts=[AccountEntity{id=1, userName='潇洒哥', password='12345'}]}
2020-08-10 22:58:52,382 [main] [mapper.GameMapper.updateGameNameById]-[DEBUG] ==> Preparing: update tb_game set name = ? where id = ?
2020-08-10 22:58:52,382 [main] [mapper.GameMapper.updateGameNameById]-[DEBUG] ==> Parameters: 王者荣耀(String), 1(Integer)
2020-08-10 22:58:52,398 [main] [mapper.GameMapper.updateGameNameById]-[DEBUG] <== Updates: 1
2020-08-10 22:58:52,398 [main] [mapper.GameMapper]-[DEBUG] Cache Hit Ratio [mapper.GameMapper]: 0.0
GameEntity{id=1, name='英雄联盟', type='MOBA', operator='腾讯游戏', accounts=[AccountEntity{id=1, userName='潇洒哥', password='12345'}]}
在对 tb_game 表执行了一次更新后,再次进行联查,发现数据库中查询出的还是游戏名仍是王者荣耀,也就是说,最后一次联查实际上查询的是第一次查询结果的缓存,而不是从数据库中查询得到的值,这样就读到了脏数据。
如果是两个 mapper 命名空间的话,解决办法是可以使用 cache-ref 来把一个命名空间指向另外一个命名空间,从而消除上述的影响,再次执行,就可以查询到正确的数据。
一级缓存和二级缓存的区别
二级缓存是 Mapper 级别,一级缓存是 SqlSession 级别,多个 SqlSession 级别的一级缓存可以共享一个 Mapper 级别的二级缓存。
当开启二级缓存后,数据的查询执行的流程是二级缓存 -> 一级缓存 -> 数据库
MyBatis 缓存使用注意事项
-
缓存是以
namespace为单位的,不同namespace下的操作互不影响。 -
insert,update,delete操作会清空所在
namespace下的全部缓存。 -
通常使用MyBatis Generator 生成的代码中,都是各个表独立的,每个表都有自己的
namespace。 -
多表操作一定不要使用二级缓存,因为多表操作进行更新操作,一定会产生脏数据。
如果你遵守二级缓存的注意事项,那么你就可以使用二级缓存。但是,如果不能使用多表操作,二级缓存不就可以用一级缓存来替换掉吗?而且二级缓存是表级缓存,开销大,没有一级缓存直接使用 HashMap 来存储的效率更高,所以二级缓存并不推荐使用。