Redis散列类型可以存储一组无序的键值对,它特别适用于存储一个对象数据。
> HSET fruit name apple price 7.6 origin china
3
> HGET fruit price
"7.6"
本文分析Redis中散列类型以及其底层数据结构--字典的实现原理。
字典
Redis通常使用字典结构存储用户散列数据。
字典是Redis的重要数据结构。除了散列类型,Redis数据库也使用了字典结构。
Redis使用Hash表实现字典结构。分析Hash表,我们通常关注以下几个问题:
(1)使用什么Hash算法?
(2)Hash冲突如何解决?
(3)Hash表如何扩容?
提示:本章代码如无特别说明,均在dict.h、dict.c中。
定义
字典中键值对的定义如下:
typedef struct dictEntry {
void *key;
union {
void *val;
uint64_t u64;
int64_t s64;
double d;
} v;
struct dictEntry *next;
} dictEntry;
- key、v:键、值。
- next:下一个键值对指针。可见Redis字典使用链表法解决Hash冲突的问题。
提示:C语言union关键字用于声明共用体,共用体的所有属性共用同一空间,同一时间只能储存其中一个属性值。也就是说,dictEntry.v可以存放val、u64、s64、d中的一个属性值。使用sizeof函数计算共用体大小,结果不会小于共用体中最大的成员属性大小。
字典中Hash表的定义如下:
typedef struct dictht {
dictEntry **table;
unsigned long size;
unsigned long sizemask;
unsigned long used;
} dictht;
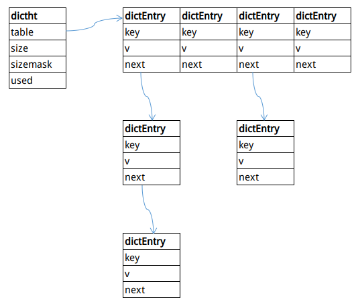
- table:Hash表数组,负责存储数据。
- used:记录存储键值对的数量。
- size:Hash表数组长度。
dictht的结构如图3-1所示。
字典的定义如下:
typedef struct dict {
dictType *type;
void *privdata;
dictht ht[2];
long rehashidx;
unsigned long iterators;
} dict;
- type:指定操作数据的函数指针。
- ht[2]:定义两个Hash表用于实现字典扩容机制。通常场景下只使用ht[0],而在扩容时,会创建ht[1],并在操作数据时中逐步将ht[0]的数据移到ht[1]中。
- rehashidx:下一次执行扩容单步操作要迁移的ht[0]Hash表数组索引,-1代表当前没有进行扩容操作。
- iterators:当前运行的迭代器数量,迭代器用于遍历字典键值对。
dictType定义了字典中用于操作数据的函数指针,这些函数负责实现数据复制、比较等操作。
typedef struct dictType {
uint64_t (*hashFunction)(const void *key);
void *(*keyDup)(void *privdata, const void *key);
void *(*valDup)(void *privdata, const void *obj);
int (*keyCompare)(void *privdata, const void *key1, const void *key2);
void (*keyDestructor)(void *privdata, void *key);
void (*valDestructor)(void *privdata, void *obj);
} dictType;
通过dictType指定操作数据的函数指针,字典就可以存放不同类型的数据了。但在一个字典中,键、值可以是不同的类型,但键必须类型相同,值也必须类型相同。
Redis为不同的字典定义了不同的dictType,如数据库使用的server.c/dbDictType,散列类型使用的server.c/setDictType等。
操作分析
dictAddRaw函数可以在字典中插入或查找键:
dictEntry *dictAddRaw(dict *d, void *key, dictEntry **existing)
{
long index;
dictEntry *entry;
dictht *ht;
// [1]
if (dictIsRehashing(d)) _dictRehashStep(d);
// [2]
if ((index = _dictKeyIndex(d, key, dictHashKey(d,key), existing)) == -1)
return NULL;
// [3]
ht = dictIsRehashing(d) ? &d->ht[1] : &d->ht[0];
// [4]
entry = zmalloc(sizeof(*entry));
entry->next = ht->table[index];
ht->table[index] = entry;
ht->used++;
// [5]
dictSetKey(d, entry, key);
return entry;
}
参数说明:
- existing:如果字典中已存在参数key,则将对应的dictEntry指针赋值给*existing,并返回null,否则返回创建的dictEntry。
【1】如果该字典正在扩容,则执行一次扩容单步操作。
【2】计算参数key的Hash表数组索引,返回-1,代表键已存在,这时dictAddRaw函数返回NULL,代表该键已存在。
【3】如果该字典正在扩容,则将新的dictEntry添加到ht[1]中,否则添加到ht[0]中。
【4】创建dictEntry,头插到Hash表数组对应位置的链表中。Redis字典使用链表法解决Hash冲突,Hash表数组的元素都是链表。
【5】将键设置到dictEntry中。
dictAddRaw函数只会插入键,并不插入对应的值。可以使用返回的dictEntry插入值:
entry = dictAddRaw(dict,mykey,NULL);
if (entry != NULL) dictSetSignedIntegerVal(entry,1000);
Hash算法
dictHashKey宏调用dictType.hashFunction函数计算键的Hash值:
#define dictHashKey(d, key) (d)->type->hashFunction(key)
Redis中字典基本都使用SipHash算法(server.c/dbDictType、server.c/setDictType等dictType的hashFunction属性指向的函数都使用了SipHash算法)。该算法能有效地防止Hash表碰撞攻击,并提供不错的性能。
Hash算法涉及较多的数学知识,本书并不讨论Hash算法的原理及实现,读者可以自行阅读相关代码。
提示:Redis 4.0之前使用的Hash算法是MurmurHash。即使输入的键是有规律的,该算法计算的结果依然有很好的离散性,并且计算速度非常快。Redis 4.0开始更换为SipHash算法,应该是出于安全的考虑。
计算键的Hash值后,还需要计算键的Hash表数组索引:
static long _dictKeyIndex(dict *d, const void *key, uint64_t hash, dictEntry **existing)
{
unsigned long idx, table;
dictEntry *he;
if (existing) *existing = NULL;
// [1]
if (_dictExpandIfNeeded(d) == DICT_ERR)
return -1;
// [2]
for (table = 0; table <= 1; table++) {
idx = hash & d->ht[table].sizemask;
he = d->ht[table].table[idx];
while(he) {
if (key==he->key || dictCompareKeys(d, key, he->key)) {
if (existing) *existing = he;
return -1;
}
he = he->next;
}
// [3]
if (!dictIsRehashing(d)) break;
}
return idx;
}
【1】根据需要进行扩容或初始化Hash表操作。
【2】遍历ht[0]、ht[1],计算Hash表数组索引,并判断Hash表中是否已存在参数key。若已存在,则将对应的dictEntry赋值给*existing。
【3】如果当前没有进行扩容操作,则计算ht[0]索引后便退出,不需要计算ht[1]。
扩容
Redis使用了一种渐进式扩容方式,这样设计,是因为Redis是单线程的。如果在一个操作内将ht[0]所有数据都迁移到ht[1],那么可能会引起线程长期阻塞。所以,Redis字典扩容是在每次操作数据时都执行一次扩容单步操作,扩容单步操作即将ht[0].table[rehashidx]的数据迁移到ht[1]。等到ht[0]的所有数据都迁移到ht[1],便将ht[0]指向ht[1],完成扩容。
_dictExpandIfNeeded函数用于判断Hash表是否需要扩容:
static int _dictExpandIfNeeded(dict *d)
{
...
if (d->ht[0].used >= d->ht[0].size &&
(dict_can_resize ||
d->ht[0].used/d->ht[0].size > dict_force_resize_ratio))
{
return dictExpand(d, d->ht[0].used*2);
}
return DICT_OK;
}
扩容需要满足两个条件:
(1)d->ht[0].used≥d->ht[0].size:Hash表存储的键值对数量大于或等于Hash表数组的长度。
(2)开启了dict_can_resize或者负载因子大于dict_force_resize_ratio。
d->ht[0].used/d->ht[0].size,即Hash表存储的键值对数量/Hash表数组的长度,称之为负载因子。dict_can_resize默认开启,即负载因子等于1就扩容。负载因子等于1可能出现比较高的Hash冲突率,但这样可以提高Hash表的内存使用率。dict_force_resize_ratio关闭时,必须等到负载因子等于5时才强制扩容。用户不能通过配置关闭dict_force_resize_ratio,该值的开关与Redis持久化有关,等我们分析Redis持久化时再讨论该值。
dictExpand函数开始扩容操作:
int dictExpand(dict *d, unsigned long size)
{
...
// [1]
dictht n;
unsigned long realsize = _dictNextPower(size);
...
// [2]
n.size = realsize;
n.sizemask = realsize-1;
n.table = zcalloc(realsize*sizeof(dictEntry*));
n.used = 0;
// [3]
if (d->ht[0].table == NULL) {
d->ht[0] = n;
return DICT_OK;
}
// [4]
d->ht[1] = n;
d->rehashidx = 0;
return DICT_OK;
}
参数说明:
- size:新Hash表数组长度。
【1】_dictNextPower函数会将size调整为2的n次幂。
【2】构建一个新的Hash表dictht。
【3】ht[0].table==NULL,代表字典的Hash表数组还没有初始化,将新dictht赋值给ht[0],现在它就可以存储数据了。这里并不是扩容操作,而是字典第一次使用前的初始化操作。
【4】否则,将新dictht赋值给ht[1],并将rehashidx赋值为0。rehashidx代表下一次扩容单步操作要迁移的ht[0] Hash表数组索引。
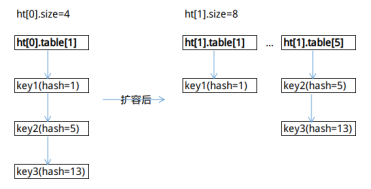
为什么要将size调整为2的n次幂呢?这样是为了ht[1] Hash表数组长度是ht[0] Hash表数组长度的倍数,有利于ht[0]的数据均匀地迁移到ht[1]。
我们看一下键的Hash表数组索引计算方法:idx=hash&ht.sizemask,由于sizemask= size-1,计算方法等价于:idx=hash%(ht.size)。
因此,假如ht[0].size为n,ht[1].size为2×n,对于ht[0]上的元素,ht[0].table[k]的数据,要不迁移到ht[1].table[k],要不迁移到ht[1].table[k+n]。这样可以将ht[0].table中一个索引位的数据拆分到ht[1]的两个索引位上。
图3-2展示了一个简单示例。
_dictRehashStep函数负责执行扩容单步操作,将ht[0]中一个索引位的数据迁移到ht[1]中。 dictAddRaw、dictGenericDelete、dictFind、dictGetRandomKey、dictGetSomeKeys等函数都会调用该函数,从而逐步将数据迁移到新的Hash表中。
_dictRehashStep调用dictRehash函数完成扩容单步操作:
int dictRehash(dict *d, int n) {
int empty_visits = n*10;
// [1]
if (!dictIsRehashing(d)) return 0;
while(n-- && d->ht[0].used != 0) {
dictEntry *de, *nextde;
assert(d->ht[0].size > (unsigned long)d->rehashidx);
// [2]
while(d->ht[0].table[d->rehashidx] == NULL) {
d->rehashidx++;
if (--empty_visits == 0) return 1;
}
// [3]
de = d->ht[0].table[d->rehashidx];
while(de) {
uint64_t h;
nextde = de->next;
h = dictHashKey(d, de->key) & d->ht[1].sizemask;
de->next = d->ht[1].table[h];
d->ht[1].table[h] = de;
d->ht[0].used--;
d->ht[1].used++;
de = nextde;
}
d->ht[0].table[d->rehashidx] = NULL;
d->rehashidx++;
}
// [4]
if (d->ht[0].used == 0) {
zfree(d->ht[0].table);
d->ht[0] = d->ht[1];
_dictReset(&d->ht[1]);
d->rehashidx = -1;
return 0;
}
return 1;
}
参数说明:
- n:本次操作迁移的Hash数组索引的数量。
【1】如果字典当前并没有进行扩容,则直接退出函数。
【2】从rehashidx开始,找到第一个非空索引位。
如果这里查找的的空索引位的数量大于n×10,则直接返回。
【3】遍历该索引位链表上所有的元素。
计算每个元素在ht[1]的Hash表数组中的索引,将元素移动到ht[1]中。
【4】ht[0].used==0,代表ht[0]的数据已经全部移到ht[1]中。
释放ht[0].table,将ht[0]指针指向ht[1],并重置rehashidx、d->ht[1],扩容完成。
缩容
执行删除操作后,Redis会检查字典是否需要缩容,当Hash表长度大于4且负载因子小于0.1时,会执行缩容操作,以节省内存。缩容实际上也是通过dictExpand函数完成的,只是函数的第二个参数size是缩容后的大小。
dict常用的函数如表3-1所示。
| 函数 | 作用 |
|---|---|
| dictAdd | 插入键值对 |
| dictReplace | 替换或插入键值对 |
| dictDelete | 删除键值对 |
| dictFind | 查找键值对 |
| dictGetIterator | 生成不安全迭代器,可以对字典进行修改 |
| dictGetSafeIterator | 生成安全迭代器,不可对字典进行修改 |
| dictResize | 字典缩容 |
| dictExpand | 字典扩容 |
编码
散列类型有OBJ_ENCODING_HT和OBJ_ENCODING_ZIPLIST两种编码,分别使用dict、ziplist结构存储数据(redisObject.ptr指向dict、ziplist结构)。Redis会优先使用ziplist存储散列元素,使用一个ziplist节点存储键,后驱节点存放值,查找时需要遍历ziplist。使用dict存储散列元素,字典的键和值都是sds类型。散列类型使用OBJ_ENCODING_ZIPLIST编码,需满足以下条件:
(1)散列中所有键或值的长度小于或等于server.hash_max_ziplist_value,该值可通过hash-max-ziplist-value配置项调整。
(2)散列中键值对的数量小于server.hash_max_ziplist_entries,该值可通过hash-max- ziplist-entries配置项调整。
散列类型的实现代码在t_hash.c中,读者可以查看源码了解更多实现细节。
数据库
Redis是内存数据库,内部定义了数据库对象server.h/redisDb负责存储数据,redisDb也使用了字典结构管理数据。
typedef struct redisDb {
dict *dict;
dict *expires;
dict *blocking_keys;
dict *ready_keys;
dict *watched_keys;
int id;
...
} redisDb;
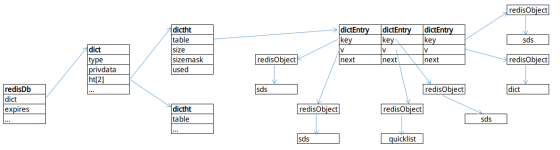
- dict:数据库字典,该redisDb所有的数据都存储在这里。
- expires:过期字典,存储了Redis中所有设置了过期时间的键及其对应的过期时间,过期时间是long long类型的UNIX时间戳。
- blocking_keys:处于阻塞状态的键和相应的客户端。
- ready_keys:准备好数据后可以解除阻塞状态的键和相应的客户端。
- watched_keys:被watch命令监控的键和相应客户端。
- id:数据库ID标识。
Redis是一个键值对数据库,全称为Remote Dictionary Server(远程字典服务),它本身就是一个字典服务。redisDb.dict字典中的键都是sds,值都是redisObject。这也是redisObject作用之一,它将所有的数据结构都封装为redisObject结构,作为redisDb字典的值。
一个简单的redisDb结构如图3-3所示。
当我们需要操作Redis数据时,都需要从redisDb中找到该数据。
db.c中定义了hashTypeLookupWriteOrCreate、lookupKeyReadOrReply等函数,可以通过键找到redisDb.dict中对应的redisObject,这些函数都是通过调用dict API实现的,这里不一一展示,感兴趣的读者可以自行阅读代码。
总结:
- Redis字典使用SipHash算法计算Hash值,并使用链表法处理Hash冲突。
- Redis字典使用渐进式扩容方式,在每次数据操作中都执行一次扩容单步操作,直到扩容完成。
- 散列类型的编码格式可以为OBJ_ENCODING_HT、OBJ_ENCODING_ZIPLIST。
本文内容摘自作者新书《Redis核心原理与实践》,这本书深入地分析了Redis常用特性的内部机制与实现方式,大部分内容源自对Redis 6.0源码的分析,并从中总结出设计思路、实现原理。通过阅读本书,读者可以快速、轻松地了解Redis的内部运行机制。
经过该书编辑同意,我会继续在个人技术公众号(binecy)发布书中部分章节内容,作为书的预览内容,欢迎大家查阅,谢谢。