写在前面
在产品初期快速迭代的过程中,往往为了快速上线而占据市场,在后端开发的过程中往往不会过多的考虑分布式和微服务,往往会将后端服务做成一个单体应用,而数据库也是一样,最初会把所有的业务数据都放到一个数据库中,即所谓的单实例数据库。随着业务的迅速发展,将所有数据都放在一个数据库中已经不足以支撑业务发展的需要。此时,就会对系统进行分布式改造,而数据库业务进行分库分表的拆分。那么,问题来了,如何更好的访问和管理拆分后的数据库呢?业界已经有很多成熟的解决方案,其中,一个非常优秀的解决方案就是:Apache ShardingSphere。今天,我们就从源码级别来共同探讨下sharding-jdbc的核心源码。
sharding-jdbc经典用法
Sharding-Jdbc 是一个轻量级的分库分表框架,使用时最关键的是配置分库分表策略,其余的和使用普通的 MySQL 驱动一样,几乎不用改代码。例如下面的代码片段。
try(DataSource dataSource = ShardingDataSourceFactory.createDataSource(
createDataSourceMap(), shardingRuleConfig, new Properties()) {
Connection connection = dataSource.getConnection();
...
}
我们在程序中拿到Connection对象后,就可以像使用普通的JDBC一样来使用sharding-jdbc操作数据库了。
sharding-jdbc包结构
sharding-jdbc
├── sharding-jdbc-core 重写DataSource/Connection/Statement/ResultSet四大对象
└── sharding-jdbc-orchestration 配置中心
sharding-core
├── sharding-core-api 接口和配置类
├── sharding-core-common 通用分片策略实现...
├── sharding-core-entry SQL解析、路由、改写,核心类BaseShardingEngine
├── sharding-core-route SQL路由,核心类StatementRoutingEngine
├── sharding-core-rewrite SQL改写,核心类ShardingSQLRewriteEngine
├── sharding-core-execute SQL执行,核心类ShardingExecuteEngine
└── sharding-core-merge 结果合并,核心类MergeEngine
shardingsphere-sql-parser
├── shardingsphere-sql-parser-spi SQLParserEntry,用于初始化SQLParser
├── shardingsphere-sql-parser-engine SQL解析,核心类SQLParseEngine
├── shardingsphere-sql-parser-relation
└── shardingsphere-sql-parser-mysql MySQL解析器,核心类MySQLParserEntry和MySQLParser
shardingsphere-underlying 基础接口和api
├── shardingsphere-rewrite SQLRewriteEngine接口
├── shardingsphere-execute QueryResult查询结果
└── shardingsphere-merge MergeEngine接口
shardingsphere-spi SPI加载工具类
sharding-transaction
├── sharding-transaction-core 接口ShardingTransactionManager,SPI加载
├── sharding-transaction-2pc 实现类XAShardingTransactionManager
└── sharding-transaction-base 实现类SeataATShardingTransactionManager
sharding-jdbc中的四大对象
所有的一切都从 ShardingDataSourceFactory 开始的,创建了一个 ShardingDataSource 的分片数据源。除了 ShardingDataSource(分片数据源),在 Sharding-Sphere 中还有 MasterSlaveDataSourceFactory(主从数据源)、EncryptDataSourceFactory(脱敏数据源)。
public static DataSource createDataSource(
final Map<String, DataSource> dataSourceMap,
final ShardingRuleConfiguration shardingRuleConfig,
final Properties props) throws SQLException {
return new ShardingDataSource(dataSourceMap,
new ShardingRule(shardingRuleConfig, dataSourceMap.keySet()), props);
}
说明: 本文主要以 ShardingDataSource 为切入点分析 Sharding-Sphere 是如何对 JDBC 四大对象 DataSource、Connection、Statement、ResultSet 进行封装的。
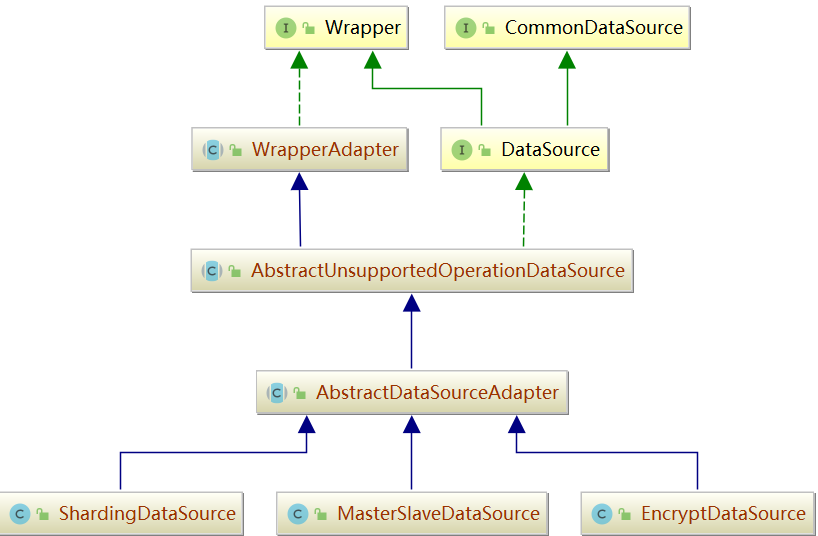
DataSource
这里,涉及到两个比较重要的接口,一个是DataSource,一个是Connection。我们首先来看下它们的类图。
-
DataSource
-
Connection
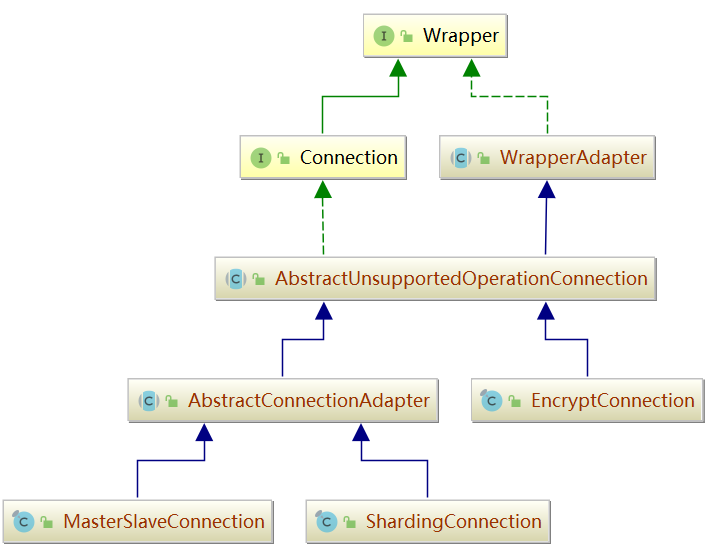
DataSource 和 Connection 都比较简单,没有处理过多的逻辑,只是 dataSourceMap, shardingRule 进行简单的封装。
ShardingDataSource 持有对数据源和分片规则,可以通过 getConnection 方法获取 ShardingConnection 连接。
private final ShardingRuntimeContext runtimeContext = new ShardingRuntimeContext(
dataSourceMap, shardingRule, props, getDatabaseType());
@Override
public final ShardingConnection getConnection() {
return new ShardingConnection(getDataSourceMap(), runtimeContext,
TransactionTypeHolder.get());
}
Connection
ShardingConnection 可以创建 Statement 和 PrepareStatement 两种运行方式,如下代码所示。
@Override
public Statement createStatement(final int resultSetType,
final int resultSetConcurrency, final int resultSetHoldability) {
return new ShardingStatement(this, resultSetType,
resultSetConcurrency, resultSetHoldability);
}
@Override
public PreparedStatement prepareStatement(final String sql, final int resultSetType,
final int resultSetConcurrency, final int resultSetHoldability)
throws SQLException {
return new ShardingPreparedStatement(this, sql, resultSetType,
resultSetConcurrency, resultSetHoldability);
}
说明: ShardingConnection 主要是将创建 ShardingStatement 和 ShardingPreparedStatement 两个对象,主要的执行逻辑都在 Statement 对象中。另外,ShardingConnection 还有两个重要的功能,一个是获取真正的数据库连接,一个是事务提交功能。
Statement
Statement 相对来说比较复杂,因为它都是 JDBC 的真正执行器,所有逻辑都封装在 Statement 中。我们来看下Statement的类图
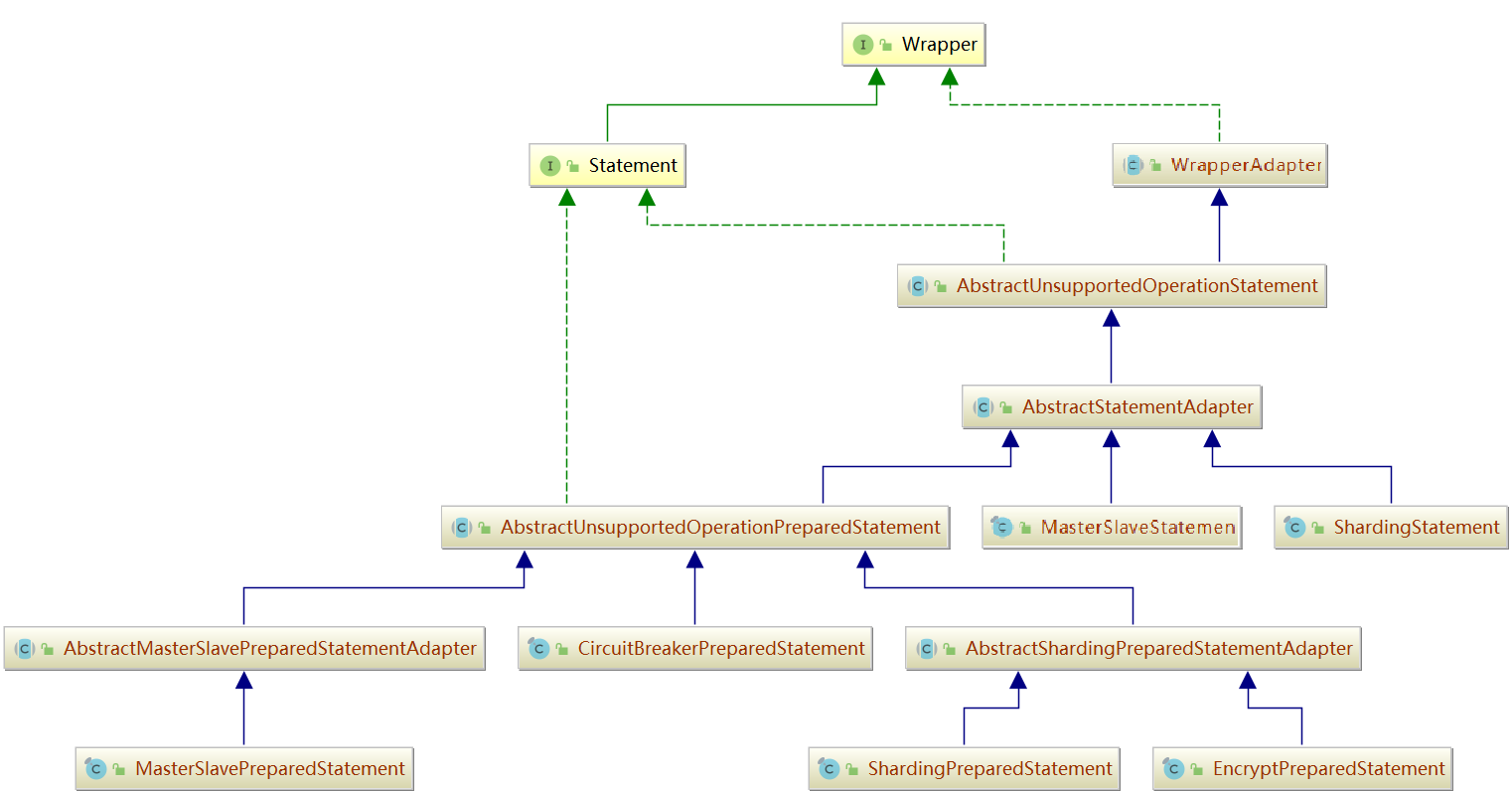
对于Statement,我就不做过多的描述了,相信使用过JDBC的小伙伴,对Statement都不陌生了。
ResultSet
ResultSet类图如下所示。
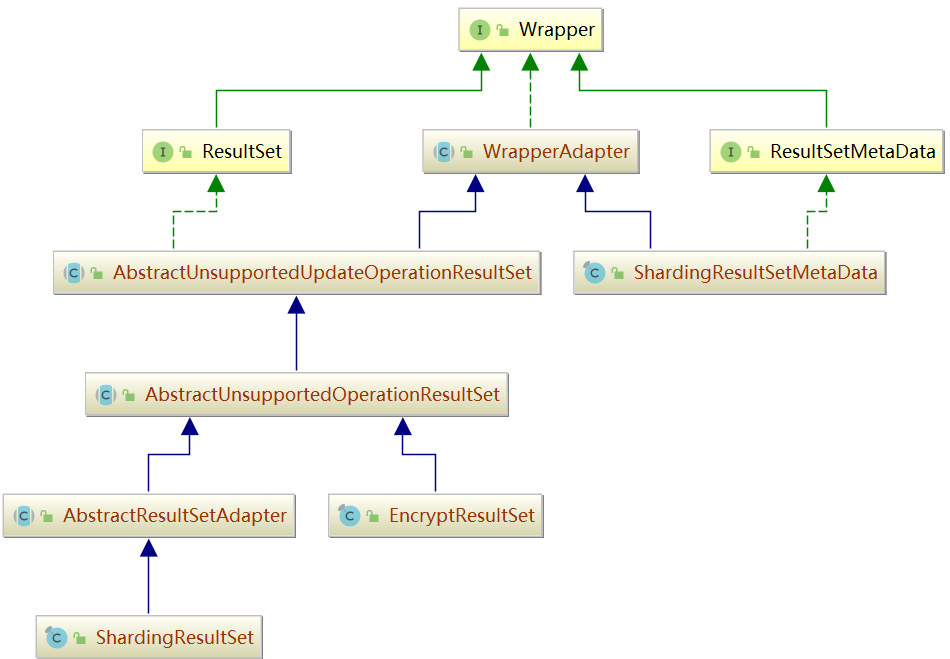
我们从源码中可以看出:ShardingResultSet 只是对 MergedResult 的简单封装。
private final MergedResult mergeResultSet;
@Override
public boolean next() throws SQLException {
return mergeResultSet.next();
}
sharding-jdbc-core核心分析
ShardingStatement 内部有三个核心的类,一是 SimpleQueryShardingEngine 完成 SQL 解析、路由、改写;一是 StatementExecutor 进行 SQL 执行;最后调用 MergeEngine 对结果进行合并处理。
ShardingStatement
初始化
private final ShardingConnection connection;
private final StatementExecutor statementExecutor;
public ShardingStatement(final ShardingConnection connection) {
this(connection, ResultSet.TYPE_FORWARD_ONLY, ResultSet.CONCUR_READ_ONLY,
ResultSet.HOLD_CURSORS_OVER_COMMIT);
}
public ShardingStatement(final ShardingConnection connection, final int resultSetType,
final int resultSetConcurrency, final int resultSetHoldability) {
super(Statement.class);
this.connection = connection;
statementExecutor = new StatementExecutor(resultSetType, resultSetConcurrency,
resultSetHoldability, connection);
}
ShardingStatement 内部执行 SQL 委托给了 statementExecutor。
执行
(1)executeQuery 执行过程
@Override
public ResultSet executeQuery(final String sql) throws SQLException {
ResultSet result;
try {
clearPrevious();
// 1. SQL 解析、路由、改写,最终生成 SQLRouteResult
shard(sql);
// 2. 生成执行计划 SQLRouteResult -> StatementExecuteUnit
initStatementExecutor();
// 3. statementExecutor.executeQuery() 执行任务
MergeEngine mergeEngine = MergeEngineFactory.newInstance(
connection.getRuntimeContext().getDatabaseType(),
connection.getRuntimeContext().getRule(), sqlRouteResult,
connection.getRuntimeContext().getMetaData().getRelationMetas(),
statementExecutor.executeQuery());
// 4. 结果合并
result = getResultSet(mergeEngine);
} finally {
currentResultSet = null;
}
currentResultSet = result;
return result;
}
(2)SQL 路由(包括 SQL 解析、路由、改写)
private SQLRouteResult sqlRouteResult;
private void shard(final String sql) {
ShardingRuntimeContext runtimeContext = connection.getRuntimeContext();
SimpleQueryShardingEngine shardingEngine = new SimpleQueryShardingEngine(
runtimeContext.getRule(), runtimeContext.getProps(),
runtimeContext.getMetaData(), runtimeContext.getParseEngine());
sqlRouteResult = shardingEngine.shard(sql, Collections.emptyList());
}
SimpleQueryShardingEngine 进行 SQL 路由(包括 SQL 解析、路由、改写),生成 SQLRouteResult,当 ShardingStatement 完成 SQL 的路由,生成 SQLRouteResult 后,剩下的执行任务就全部交给 StatementExecutor 完成。
StatementExecutor
StatementExecutor 内部封装了 SQL 任务的执行过程,包括:SqlExecutePrepareTemplate 类生成执行计划 StatementExecuteUnit,以及 SQLExecuteTemplate 用于执行 StatementExecuteUnit。
类结构

重要属性
AbstractStatementExecutor 类中重要的属性:
// SQLExecutePrepareTemplate用于生成执行计划StatementExecuteUnit
private final SQLExecutePrepareTemplate sqlExecutePrepareTemplate;
// 保存生成的执行计划StatementExecuteUnit
private final Collection<ShardingExecuteGroup<StatementExecuteUnit>> executeGroups =
new LinkedList<>();
// SQLExecuteTemplate用于执行StatementExecuteUnit
private final SQLExecuteTemplate sqlExecuteTemplate;
// 保存查询结果
private final List<ResultSet> resultSets = new CopyOnWriteArrayList<>();
生成执行计划
// 执行前清理状态
private void clearPrevious() throws SQLException {
statementExecutor.clear();
}
// 执行时初始化
private void initStatementExecutor() throws SQLException {
statementExecutor.init(sqlRouteResult);
replayMethodForStatements();
}
这里,需要注意的是: StatementExecutor 是有状态的,每次执行前都要调用 statementExecutor.clear() 清理上一次执行的状态,并调用 statementExecutor.init() 重新初始化。
statementExecutor.init() 初始化主要是生成执行计划 StatementExecuteUnit。
public void init(final SQLRouteResult routeResult) throws SQLException {
setSqlStatementContext(routeResult.getSqlStatementContext());
getExecuteGroups().addAll(obtainExecuteGroups(routeResult.getRouteUnits()));
cacheStatements();
}
private Collection<ShardingExecuteGroup<StatementExecuteUnit>> obtainExecuteGroups(
final Collection<RouteUnit> routeUnits) throws SQLException {
return getSqlExecutePrepareTemplate().getExecuteUnitGroups(
routeUnits, new SQLExecutePrepareCallback() {
// 获取连接
@Override
public List<Connection> getConnections(
final ConnectionMode connectionMode,
final String dataSourceName, final int connectionSize)
throws SQLException {
return StatementExecutor.super.getConnection().getConnections(
connectionMode, dataSourceName, connectionSize);
}
// 生成执行计划RouteUnit -> StatementExecuteUnit
@Override
public StatementExecuteUnit createStatementExecuteUnit(
final Connection connection, final RouteUnit routeUnit,
final ConnectionMode connectionMode) throws SQLException {
return new StatementExecuteUnit(
routeUnit, connection.createStatement(
getResultSetType(), getResultSetConcurrency(),
getResultSetHoldability()), connectionMode);
}
});
}
SqlExecutePrepareTemplate 是 sharding-core-execute 工程中提供的一个工具类,专门用于生成执行计划,将 RouteUnit 转化为 StatementExecuteUnit。同时还提供了另一个工具类 SQLExecuteTemplate 用于执行 StatementExecuteUnit,在任务执行时我们会看到这个类。
任务执行
public List<QueryResult> executeQuery() throws SQLException {
final boolean isExceptionThrown = ExecutorExceptionHandler.isExceptionThrown();
SQLExecuteCallback<QueryResult> executeCallback =
new SQLExecuteCallback<QueryResult>(getDatabaseType(), isExceptionThrown) {
@Override
protected QueryResult executeSQL(final String sql, final Statement statement,
final ConnectionMode connectionMode) throws SQLException {
return getQueryResult(sql, statement, connectionMode);
}
};
// 执行StatementExecuteUnit
return executeCallback(executeCallback);
}
// sqlExecuteTemplate 执行 executeGroups(即StatementExecuteUnit)
protected final <T> List<T> executeCallback(
final SQLExecuteCallback<T> executeCallback) throws SQLException {
// 执行所有的任务 StatementExecuteUnit
List<T> result = sqlExecuteTemplate.executeGroup(
(Collection) executeGroups, executeCallback);
refreshMetaDataIfNeeded(connection.getRuntimeContext(), sqlStatementContext);
return result;
}
SqlExecuteTemplate 执行 StatementExecuteUnit 会回调 SQLExecuteCallback#executeSQL 方法,最终调用 getQueryResult 方法。
private QueryResult getQueryResult(final String sql, final Statement statement,
final ConnectionMode connectionMode) throws SQLException {
ResultSet resultSet = statement.executeQuery(sql);
getResultSets().add(resultSet);
return ConnectionMode.MEMORY_STRICTLY == connectionMode
? new StreamQueryResult(resultSet)
: new MemoryQueryResult(resultSet);
}
ConnectionMode 有两种模式:内存限制(MEMORY_STRICTLY)和连接限制(CONNECTION_STRICTLY),如果一个连接执行多个 StatementExecuteUnit 则为内存限制(MEMORY_STRICTLY),采用流式处理,即 StreamQueryResult ,反之则为连接限制(CONNECTION_STRICTLY),此时会将所有从 MySQL 服务器返回的数据都加载到内存中。特别是在 Sharding-Proxy 中特别有用,避免将代理服务器撑爆。
重磅福利
微信搜一搜【冰河技术】微信公众号,关注这个有深度的程序员,每天阅读超硬核技术干货,公众号内回复【PDF】有我准备的一线大厂面试资料和我原创的超硬核PDF技术文档,以及我为大家精心准备的多套简历模板(不断更新中),希望大家都能找到心仪的工作,学习是一条时而郁郁寡欢,时而开怀大笑的路,加油。如果你通过努力成功进入到了心仪的公司,一定不要懈怠放松,职场成长和新技术学习一样,不进则退。如果有幸我们江湖再见!
另外,我开源的各个PDF,后续我都会持续更新和维护,感谢大家长期以来对冰河的支持!!