/* 前言: DBA的日常任务并不仅仅是创建需要的索引在对应的列上,实际上,DBA还要保持索引创建的高标准。 周而复始,DBA必须盯着一些非常重要的信息: 1、 索引的碎片级别 2、 丢失索引 3、 无效索引 查找索引碎片: 如果索引没有正确维护,那么碎片往往会成为性能瓶颈。微软建议当碎片百分比在~30之间的时候,使用重组索引来代替更加耗资源的重建索引。如果碎片超过%,可以使用重建索引。但是这仅仅是建议而不是绝对的事情。而且从开始,这个建议就没有改变过,但是从到,索引已经改变了许多。 现在先来检查一下环境,以便评估百分比的级别是否达到重建的地步。因为在进行这步耗资源的操作前,会有很多因素需要考虑,其中主要有: 1、 备份策略 2、 服务器工作负载 3、 可用磁盘空间 4、 恢复模式 虽然碎片对查询性能有很大的影响,但是它依然是基于表的,并且基于你如何使用表。大部分情况下,如果你仅仅从一个表中通过查询聚集索引上的主键来返回一条数据,那么碎片将不在考虑范围。 准备工作: 了解碎片之后,接着就要知道如何确定索引的碎片?此时只需要使用sys.dm_db_index_physical_stats系统函数和系统目录sys.Indexes联合查询即可。 步骤: 收集你的索引的碎片是第一个重要任务,可以使用以下脚本实现: */ --1)收集特定表上所有索引、堆的信息 SELECT sysIn.name AS IndexName , sysIn.index_id , func.avg_fragmentation_in_percent , --逻辑碎片(索引中的无序页)的百分比 func.index_type_desc AS IndexType , func.page_count FROM sys.dm_db_index_physical_stats(DB_ID(), OBJECT_ID(N'u_store_c'), NULL,NULL, NULL) AS func INNER JOIN sys.indexes AS sysIn ON func.object_id = sysIn.object_id AND func.index_id = sysIn.index_id 执行报错:

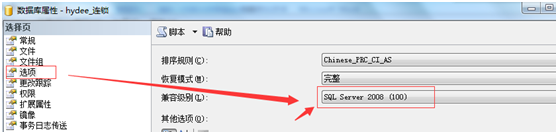
处理:选择数据库---属性,修改为100的即可,向下兼容是80
-------------------------------------------------- --如果你的数据的兼容个模式设置为SQL 2000就不能这么是用 --不支持参数里直接用DB_ID(),可以换成下面的写法 DECLARE @database_id INT = DB_ID(), @object_id INT = OBJECT_ID(N'dbo.u_store_c'); --SELECT * --FROM sys.dm_db_index_physical_stats (@database_id ,@object_id , NULL, NULL, NULL) AS a SELECT sysIn.name AS IndexName , sysIn.index_id , func.avg_fragmentation_in_percent , --逻辑碎片(索引中的无序页)的百分比 func.index_type_desc AS IndexType , func.page_count FROM sys.dm_db_index_physical_stats (@database_id ,@object_id , NULL, NULL, NULL) AS func INNER JOIN sys.indexes AS sysIn ON func.object_id = sysIn.object_id AND func.index_id = sysIn.index_id --聚集索引的Index_id为,非聚集索引的Index_id总是大于,如果不想看堆表的信息,可以使用 --where sysIn.index_id>0; --2)收集在数据库中所有可用的索引信息,下面查询可能会运行时间比较久: SELECT sysIn.name AS IndexName , sysIn.index_id , func.avg_fragmentation_in_percent , --逻辑碎片(索引中的无序页)的百分比 func.index_type_desc AS IndexType , func.page_count FROM sys.dm_db_index_physical_stats(DB_ID(), NULL, NULL, NULL, NULL) AS func INNER JOIN sys.indexes AS sysIn ON func.object_id = sysIn.object_id AND func.index_id = sysIn.index_id WHERE sysIn.index_id > 0 ; /* 分析: 在函数sys.dm_db_index_physical_stats中传入DB_ID()可以限制只返回当前数据库的信息,而object_ID(N’ordDemo’)是返回这个数据库中这个表的索引信息。这个系统函数:sys.dm_db_index_physical_stats可以提供非常详细的信息,为了知道索引名称,需要关联sys.indexes系统目录来获得名称。 扩展信息: 当在索引叶子节点中的数据逻辑顺序和物理顺序不一致的时候,就会出现碎片。当你创建一个索引时,会对所有东西排序,但是当数据通过DML语句操作是,并不能保证新数据能适应数据页的顺序。当你删除数据时,不仅只从实际数据页上删除数据,也会释放数据也的空间来用于其他数据的使用,这就会产生碎片。 记住,当索引第一次创建是,只有少量甚至没有碎片,但是在增删改操作后,就开始出现碎片。 */ ----------------------------------- --avg_fragmentation_in_percent 值 修复语句 > 5% 且 < = 30% ALTER INDEX REORGANIZE > 30% ALTER INDEX REBUILD WITH (ONLINE = ON)*
/*
前言:
DBA的日常任务并不仅仅是创建需要的索引在对应的列上,实际上,DBA还要保持索引创建的高标准。
周而复始,DBA必须盯着一些非常重要的信息:
1、索引的碎片级别
2、丢失索引
3、无效索引
查找索引碎片:
如果索引没有正确维护,那么碎片往往会成为性能瓶颈。微软建议当碎片百分比在~30之间的时候,使用重组索引来代替更加耗资源的重建索引。如果碎片超过%,可以使用重建索引。但是这仅仅是建议而不是绝对的事情。而且从开始,这个建议就没有改变过,但是从到,索引已经改变了许多。
现在先来检查一下环境,以便评估百分比的级别是否达到重建的地步。因为在进行这步耗资源的操作前,会有很多因素需要考虑,其中主要有:
1、备份策略
2、服务器工作负载
3、可用磁盘空间
4、恢复模式
虽然碎片对查询性能有很大的影响,但是它依然是基于表的,并且基于你如何使用表。大部分情况下,如果你仅仅从一个表中通过查询聚集索引上的主键来返回一条数据,那么碎片将不在考虑范围。
准备工作:
了解碎片之后,接着就要知道如何确定索引的碎片?此时只需要使用sys.dm_db_index_physical_stats系统函数和系统目录sys.Indexes联合查询即可。
步骤:
收集你的索引的碎片是第一个重要任务,可以使用以下脚本实现:
*/
--1)收集特定表上所有索引、堆的信息
SELECT sysIn.name AS IndexName ,
sysIn.index_id ,
func.avg_fragmentation_in_percent , --逻辑碎片(索引中的无序页)的百分比
func.index_type_desc AS IndexType ,
func.page_count
FROM sys.dm_db_index_physical_stats(DB_ID(), OBJECT_ID(N'u_store_c'), NULL,NULL, NULL) AS func
INNER JOIN sys.indexes AS sysIn ON func.object_id = sysIn.object_id
AND func.index_id = sysIn.index_id
执行报错:
处理:选择数据库---属性,修改为100的即可,向下兼容是80
--------------------------------------------------
--如果你的数据的兼容个模式设置为SQL 2000就不能这么是用
--不支持参数里直接用DB_ID(),可以换成下面的写法
DECLARE @database_id INT = DB_ID(), @object_id INT = OBJECT_ID(N'dbo.u_store_c');
--SELECT *
--FROM sys.dm_db_index_physical_stats (@database_id ,@object_id , NULL, NULL, NULL) AS a
SELECT sysIn.name AS IndexName ,
sysIn.index_id ,
func.avg_fragmentation_in_percent , --逻辑碎片(索引中的无序页)的百分比
func.index_type_desc AS IndexType ,
func.page_count
FROM sys.dm_db_index_physical_stats(@database_id ,@object_id , NULL, NULL, NULL) AS func
INNER JOIN sys.indexes AS sysIn ON func.object_id = sysIn.object_id
AND func.index_id = sysIn.index_id
--聚集索引的Index_id为,非聚集索引的Index_id总是大于,如果不想看堆表的信息,可以使用
--where sysIn.index_id>0;
--2)收集在数据库中所有可用的索引信息,下面查询可能会运行时间比较久:
SELECT sysIn.name AS IndexName ,
sysIn.index_id ,
func.avg_fragmentation_in_percent , --逻辑碎片(索引中的无序页)的百分比
func.index_type_desc AS IndexType ,
func.page_count
FROM sys.dm_db_index_physical_stats(DB_ID(), NULL, NULL, NULL, NULL) AS func
INNER JOIN sys.indexes AS sysIn ON func.object_id = sysIn.object_id
AND func.index_id = sysIn.index_id
WHERE sysIn.index_id > 0 ;
/*
分析:
在函数sys.dm_db_index_physical_stats中传入DB_ID()可以限制只返回当前数据库的信息,而object_ID(N’ordDemo’)是返回这个数据库中这个表的索引信息。这个系统函数:sys.dm_db_index_physical_stats可以提供非常详细的信息,为了知道索引名称,需要关联sys.indexes系统目录来获得名称。
扩展信息:
当在索引叶子节点中的数据逻辑顺序和物理顺序不一致的时候,就会出现碎片。当你创建一个索引时,会对所有东西排序,但是当数据通过DML语句操作是,并不能保证新数据能适应数据页的顺序。当你删除数据时,不仅只从实际数据页上删除数据,也会释放数据也的空间来用于其他数据的使用,这就会产生碎片。
记住,当索引第一次创建是,只有少量甚至没有碎片,但是在增删改操作后,就开始出现碎片。
*/
-----------------------------------
--avg_fragmentation_in_percent 值修复语句
> 5% 且 < = 30% ALTER INDEX REORGANIZE
> 30% ALTER INDEX REBUILD WITH (ONLINE = ON)*