我这是刚入门Python现学现卖,有问题可以留言指出谢谢
首先安装Python之后安装Python编一软件Pycharm
安装步骤可以自行百度这里就不多介绍了,下面进入正题
打开Pycharm 新建一个project File-New Project
选择存放的路径
在项目中新建了五个 new Python file
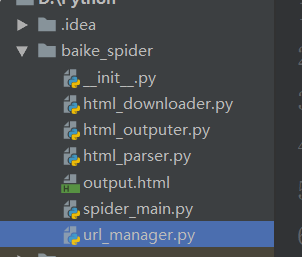
__init__是创建包的时候默认的(可以不创建)
spider_main.py 是主方法文件运行这个文件
html_manager.py 是url管理文件
html_downloader.py html网页下载器文件
html_parser.py网页解析器
html_outputer.py网页输出
首先找到网页要进行进行爬取的过程的解析我这里是找了百度百科的页面爬取的是所有词条的信息
打开https://baike.baidu.com/item/Python/407313?fr=aladdin
右击或者F12检查网页的源代码
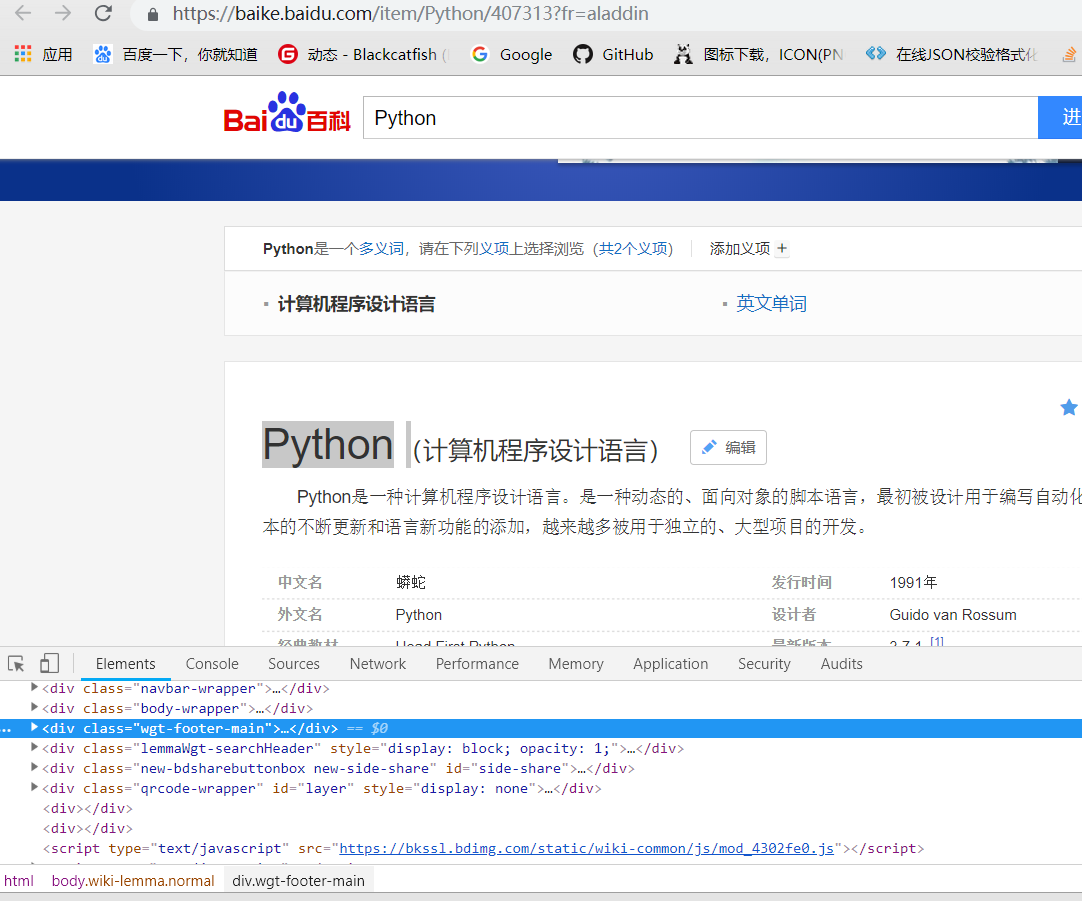

可以看到词条的a标签的href属性都是/item/xxxxxx/一串数字(网页会更新所以每次要对爬取信息的网站进行一大堆的分析)
分析之后我们就可开始开发了
首先我们看一下spider_main文件
# -*- coding: utf-8 -*- from baike_spider import url_manager, html_downloader, html_parser, html_outputer class SpiderMain(object): def __init__(self): self.urls=url_manager.UrlManager() #url管理器 self.downloader=html_downloader.HtmlDownloader()#url下载器 self.parser=html_parser.HtmlParser()#url解析器 self.outputer=html_outputer.HtmlOutper()#网页输出器 def craw(self, root_url): count=1 self.urls.add_new_url(root_url)#把带爬取的url放到url管理器中 #当url管理器中有带爬取的url的时候获取的一个url while self.urls.has_new_url(): try: new_url=self.urls.get_new_url() print('craw %d:%s '% (count,new_url)) #下载url html_cont=self.downloader.download(new_url) #解析数据 new_urls,new_data=self.parser.parser(new_url,html_cont) self.urls.add_new_urls(new_urls) self.outputer.collect_data(new_data) if count==10: break count=count+1 except: print("pa'qu爬取失败") self.outputer.outpter_html() if __name__=="__main__":
#这里是引入的待爬取的url(Python的百度百科) root_url="https://baike.baidu.com/item/Python/407313?fr=aladdin" obj_spider=SpiderMain() obj_spider.craw(root_url)
接着manager
class UrlManager(object): #定义一个新的url集合和一个爬取过的url set集合 def __init__(self): self.new_urls=set() self.old_urls=set() #如果这个url不是空的 def add_new_url(self,url): if url is None: return if url not in self.new_urls and url not in self.old_urls: self.new_urls.add(url) def get_new_url(self): #使用之后放到已爬取的set中 new_url=self.new_urls.pop() self.old_urls.add(new_url) return new_url def has_new_url(self): return len(self.new_urls)!=0 def add_new_urls(self, new_urls): if new_urls is None or len(new_urls)==0: return for url in new_urls: self.add_new_url(url)
再是download
import urllib.request #(python3.0之后的urllib 引入方式,之前是import urllib2) class HtmlDownloader(object): def download(self, new_url): if new_url is None: return None response=urllib.request.urlopen(new_url) if response.getcode()!=200: return None return response.read()
parse开始爬取
# -*- coding: utf-8 -*- import re from urllib.parse import urljoin from bs4 import BeautifulSoup #(引入的beautifulSoup) class HtmlParser(object): def parser(self, new_url, html_cont): if new_url is None or html_cont is None: return soup=BeautifulSoup(html_cont,"html.parser",from_encoding="utf-8") new_urls=self._get_new_urls(new_url,soup) new_data=self._get_new_data(new_url,soup) return new_urls,new_data def _get_new_urls(self, page_url, soup): new_urls=set() links=soup.find_all('a',href=re.compile(r"/item/")) #查找所有的a标签 并且href属性是/item/ re.compile()是匹配正则表达式 #循环列出links for link in links: new_url=link['href'] new_full_url=urljoin(page_url,new_url) new_urls.add(new_full_url) return new_urls def _get_new_data(self, new_url, soup): res_data={} res_data['url']=new_url #获取 <dd class="lemmaWgt-lemmaTitle-title"><h1>Python</h1> title_node=soup.find('dd',class_='lemmaWgt-lemmaTitle-title').find('h1') res_data['title']=title_node.get_text() #<div class="lemma-summary" label-module="lemmaSummary"> summary_node=soup.find('div',class_='lemma-summary') res_data['summary']=summary_node.get_text() return res_data
写入html文件
# -*- coding: utf-8 -*- class HtmlOutper(object): def __init__(self): self.datas=[] def collect_data(self, new_data): if new_data is None: return None self.datas.append(new_data) def outpter_html(self): fout=open('output.html','w')#w是写模式的意思 fout.write("<html>") fout.write("<body>") fout.write("<table >") for data in self.datas: fout.write("<tr>") fout.write("<td>%s</td>" % data['url']) fout.write("<td>%s</td>" % data['title'].encode("utf-8")) fout.write("<td>%s</td>" % data['summary'].encode("utf-8")) print(data['summary']) fout.write("</tr>") fout.write("</table>") fout.write("</body>") fout.write("</html>")
刷新一下工程会看到多一个output.html文件
运行这个文件
最终效果
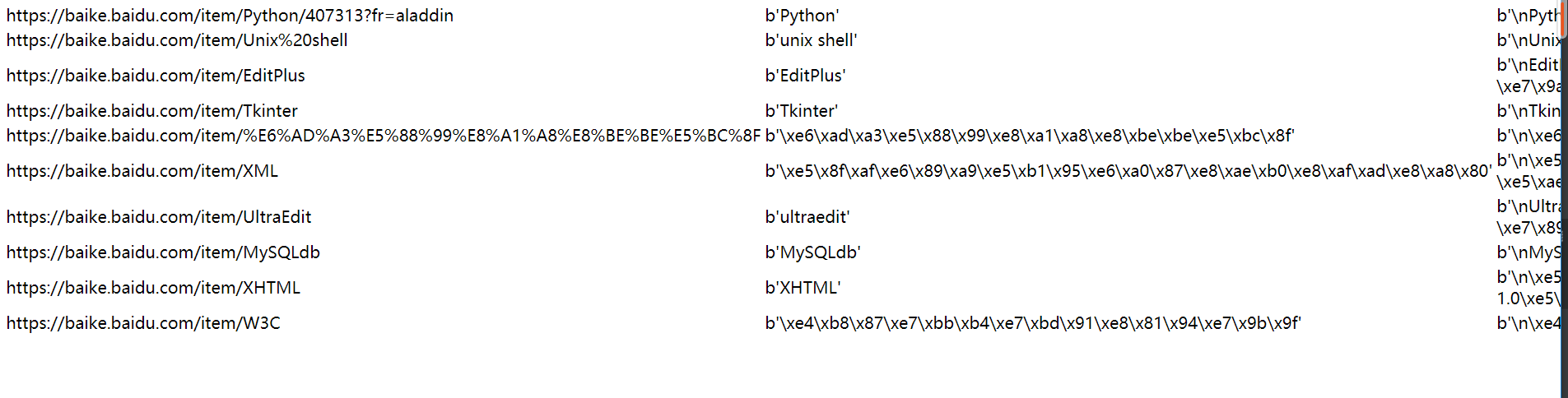
网页能看到输出端词条的url title 一些信息
如有问题多多指教感谢阅读