简介
Hadoop 是 Apache 旗下的一个用 java 语言实现开源软件框架,是一个开发和运行处理大规模数据的软件平台。允许使用简单的编程模型在大量计算机集群上对大型数据集进行分布式处理。它的核心组件有HDFS(分布式文件系统)解决海量数据存储、YARN(作业调度和集群资源管理框架)解决资源任务调度和MapReduce(分布式运算编程框架)解决海量数据计算。另外Hadoop如今拥有一个庞大的体系,成长为Hadoop生态圈,新出现的项目越来越多,比如zk、hive、flume等。
Hadoop的特性优点
- 高可靠性。Hadoop按位存储和处理数据的能力值得人们信赖。
- 高扩展性。Hadoop是在可用的计算机集簇间分配数据并完成计算任务的,这些集簇可以方便地扩展到数以千计的节点中。
- 高效性。Hadoop能够在节点之间动态地移动数据,并保证各个节点的动态平衡,因此处理速度非常快。
- 高容错性。Hadoop能够自动保存数据的多个副本,并且能够自动将失败的任务重新分配。
- 低成本。与一体机、商用数据仓库以及QlikView、Yonghong Z-Suite等数据集市相比,hadoop是开源的,项目的软件成本因此会大大降低。
Hadoop集群搭建
集群简介
HADOOP 集群具体来说包含两个集群:HDFS 集群和 YARN 集群,两者逻辑上分离,但物理上常在一起。
HDFS 集群负责海量数据的存储,集群中的角色主要有:NameNode、DataNode、SecondaryNameNode。YARN 集群负责海量数据运算时的资源调度,集群中的角色主要有:ResourceManager、NodeManager。
我们以三节点为例进行搭建,角色分配如下:
bigdata-01: NameNode DataNode | ResourceManager NodeManager
bigdata-02: DataNode SecondaryNameNode| NodeManager
bigdata-03: DataNode | NodeManager
服务器准备
三台linux虚拟机,同步时间,设置主机名和域名映射,关闭防火墙,安装jdk1.8,配置ssh免密登录。
搭建步骤
1 新建文件夹,分别用来存放压缩包、解压后的文件及运行的数据
mkdir -p /export/software
mkdir -p /export/servers
mkdir -p /export/data
2 把安装文件(最好是根据linux系统版本编译好的)放到服务器上的software文件夹内 然后解压到servers文件夹内
cd /export/software
tar -zxvf hadoop-2.7.4.tar -C /export/servers/
3 修改配置文件
#转到配置文件目录
cd /export/servers/hadoop-2.7.4/etc/hadoop
修改hadoop-env.sh
#修改JAVA_HOME路径为自己jdk安装了路径
export JAVA_HOME=/export/servers/jdk1.8.0_141
修改core-site.xml(在configuration标签里面添加)
<!--指定默认文件系统是谁 以及文件系统访问方式 并指定了hdfs的namenode在哪--> <property> <name>fs.defaultFS</name> <value>hdfs://bigdata-01:9000</value> </property> <!--指定hadoop运行时数据保存的目录--> <property> <name>hadoop.tmp.dir</name> <value>/export/data/hddata</value> <!--该目录不需要自己提前创建--> </property>
修改hdfs-site.xml(在configuration标签里面添加)
<!--指定文件副本数 默认3--> <property> <name>dfs.replication</name> <value>3</value> </property> <!--指定secondarynamenode所在机器--> <property> <name>dfs.namenode.secondary.http-address</name> <value>bigdata-02:50090</value> </property>
修改mapred-site.xml(在configuration标签里面添加)
<!-- 指定mr运行模式 使用yarn进行资源管理--> <property> <name>mapreduce.framework.name</name> <value>yarn</value> </property>
修改yarn-site.xml(在configuration标签里面添加)
<!--指定yarn老大ResourceManager所在的机器--> <property> <name>yarn.resourcemanager.hostname</name> <value>bigdata-01</value> </property> <property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property>
修改slaves文件 指定集群从角色所在机器
bigdata-01
bigdata-02
bigdata-03
4 修改并重新source环境变量
vi /etc/profile
export JAVA_HOME=/export/servers/jdk1.8.0_141
export HADOOP_HOME=/export/servers/hadoop-2.7.4
export PATH=$PATH:$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
source /etc/profile
5 格式化(初始化)集群
1、格式化准备来说是hdfs系统的初始化 创建一些自己运行所需要目录和文件
2、格式件在集群首次启动之前进行
3、只能格式化一次(本质在于格式件的时候会创建集群ID 如果多次格式化 使得主从之间集群ID标识不一致)
#以下两种格式化方式选一即可,不要两个都运行
hdfs namenode -format
hadoop namenode -format
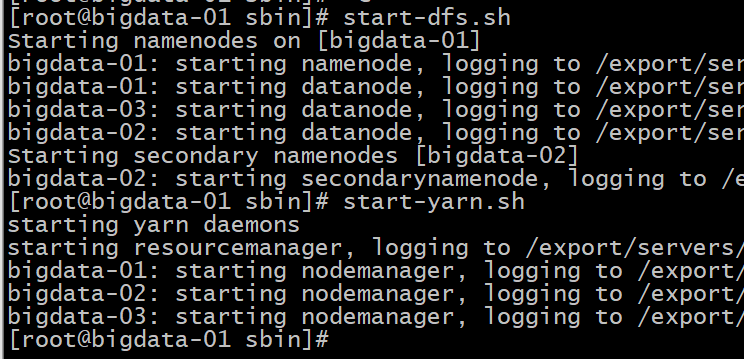
6 启动/停止集群
cd /export/servers/hadoop-2.7.4/sbin
#启动/停止HDFS集群
start-dfs.sh stop.dfs.sh
#启动/停止YARN集群
start-yarn.sh stop.yarn.sh
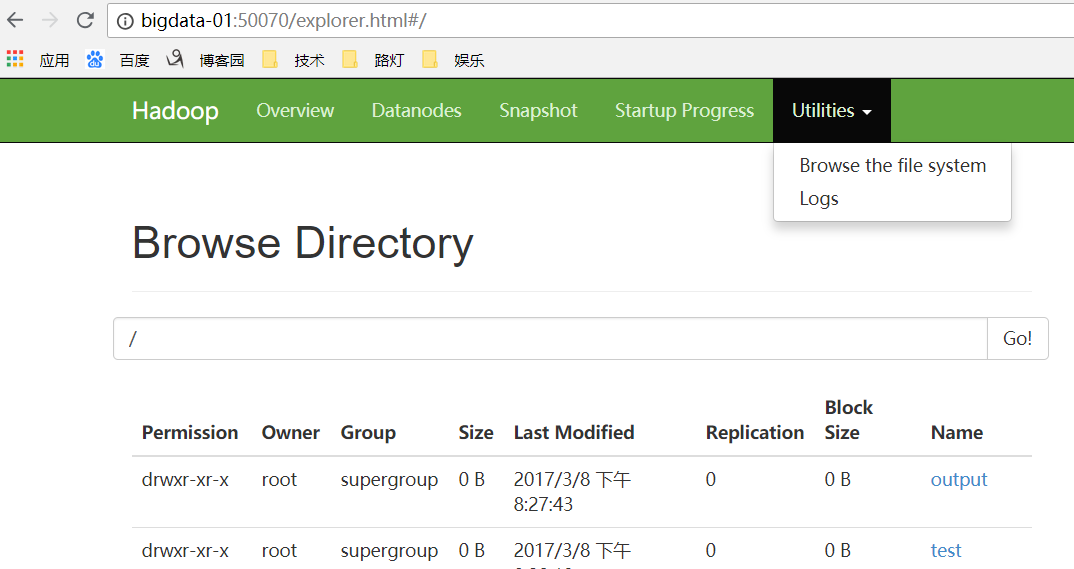
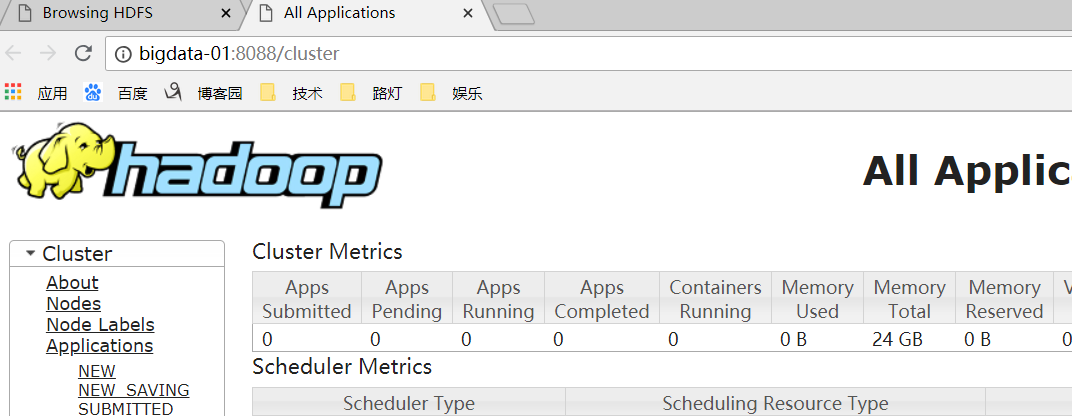
访问bigdata-01:50070 (namenode) 及 bigdata-01:8088 (resourcemanager)(windows电脑上没有配置host 就输ip+port):