分治法在每一层递归上都有三个步骤:
1)分解:将原问题分解为若干个规模较小,相互独立,与原问题形式相同的子问题
2)解决:若子问题规模较小而容易被解决则直接解,否则递归地解各个子问题
3)合并:将各个子问题的解合并为原问题的解。
适用场景
适用于我们的问题是一个大问题的时候,且这个大问题能被分解成多个小问题。
二分算法面对中间分叉,不能确定是往左走,还是往右走的时候,我们就可以使用分治算法,递归,给他左右都走一遍。
分治四步走
由于分治法一般采用递归方法实现,所以大家可以结合【算法】递归三步走来进行理解。
1. 明确分解策略
1.明确分解策略:明确大问题通过怎样的分解策略一步步分解为最终的小问题,之后我们需要根据分解策略明确函数的功能。
如果我们的分解策略如果是折半分解,那么我们的函数就需要有范围域(left, right)来确定分解范围;
注意:如果有多个分解域,我们就需要判断一下是不是每个域都要进行分解,每需要分解一次,就需要一个范围域
(left, right)。
如果是递减分解,那么我们的函数需要有计数(num),来记录递减分解结果。
最简单的例子:树的先序遍历,分解策略:根左右(根节点、左子树、右子树)
比如说,快速排序的大的问题可以分解为就是将n个元素摆到正确位置,汉诺塔的大的问题就是将n个圆盘由下而上摆到正确位置。
2. 寻找最小问题
2.寻找最小问题:最小问题也就是大问题的最简化版本,问题的起始状态,最小子问题即是出口。
最简单的例子:树的先序遍历,最小问题:根节点为空,返回return
比如说,快速排序没有元素或者只有一个元素(
left >= right)的时候。
3. 划分子类问题
子类问题:子类问题与原问题有相同的结构,是一样的,只不过规模小一些。(原问题 ∽ 子类问题),如 ((原树 ∽ 左右子树))
例子:比如树的中序遍历序列,按根节点划分之后,左右还是中序遍历序列。类比:类似于数学里面的相似三角形。
3.划分子类问题:使用分解策略将大问题分解为 当前问题 + 子类问题(即 原问题 = 当前问题 + 子类问题,我们只能解决当前问题,子类问题只起到划分的作用)。子类问题也就是介于最小问题与大问题之间的问题,与大问题有相同的结构,比大问题稍稍小那么一点,这使得子类问题具有解决大问题的通用性,即 可以通过子类问题找到大问题的通解。由子类问题得到解决方法。
特别注意:分治算法只去操作解决当前的问题,即 当前元素(如 根节点),对其他划分出来的子类问题(如 左右子树)均不操作解决,只起到划分的作用。
子类问题划分技巧:(找相似法)
由于原问题与子类问题相似,所以我们可以按照原问题提供的已知条件来寻找相似的子类问题所需要提供的条件。
例子:
问题:已知树的先序遍历、中序遍历,求出后序遍历。
- 原问题:提供大树的先序遍历序列,大树的中序遍历序列
- 子类问题:提供左右子树的中序遍历序列,根据左右子树数量来找出左右子树的先序遍历序列
你看看,上面的原问题与子类问题是不是一样的结构,相似!
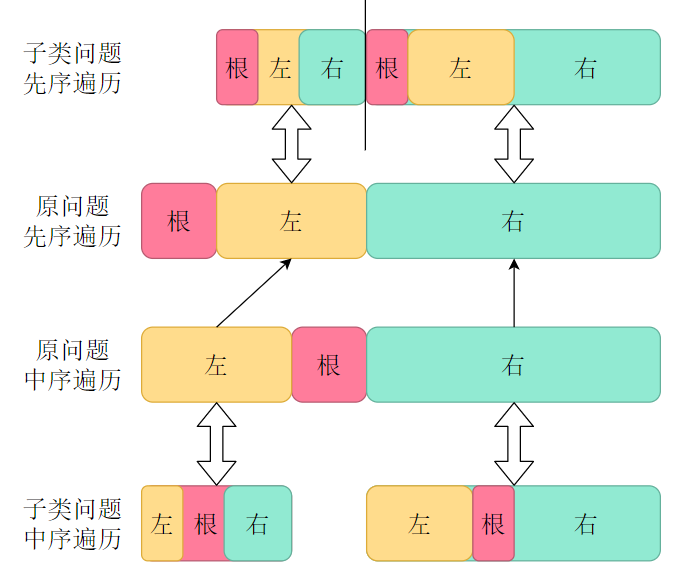
最简单的例子:树的先序遍历,
- 当前问题:根,
- 子类问题:根左右(根节点、左子树、右子树),
- 访问根节点(因为只有当前节点根节点能够给我们操作,其他的左右子树都是起到划分的作用)
比如说,快速排序的当前问题就是将一个元素摆到正确位置,汉诺塔的当前问题就是将一个最下面的圆盘摆到正确位置。
4. 解决当前问题
4.解决当前问题:这个按照问题的逻辑进行添加,分治算法只去操作解决当前的问题,即 当前元素(如 根节点),对其他划分出来的子类问题(如 左右子树)均不操作解决,只起到划分的作用。
注意:在我们上一步划分子类问题之后,我们应该解决当前问题,但是这个当前问题的解决应该位于子类问题划分的之前、中间还是之后,这个就要具体题目具体分析了。
例如:
- 先序遍历:当前问题(根)、子类问题(左子树)、子类问题(右子树)
- 中序遍历:子类问题(左子树)、当前问题(根)、子类问题(右子树)
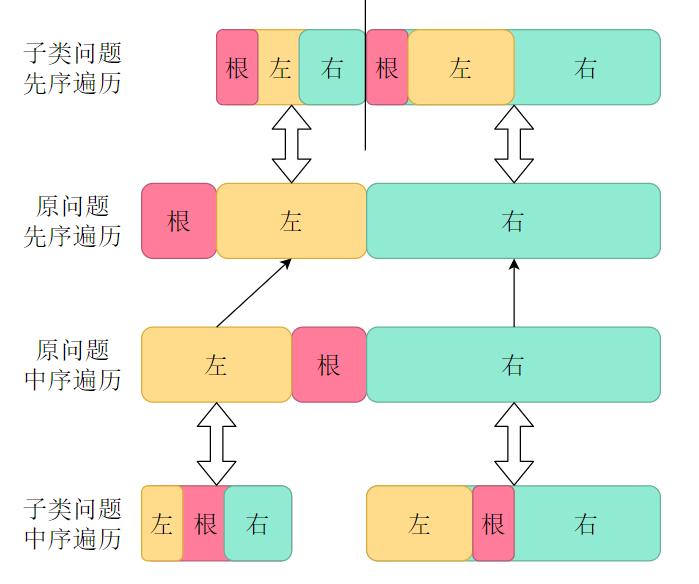
- 后序遍历:子类问题(左子树)、子类问题(右子树)、当前问题(根)
在解决当前问题的时候,我们可能会需要结合之前划分子类问题的结果返回值(不一定),也可能不需要,作为单机问题去解决。
例如,我们在上一步中划分出了左右子树,这一步中我们可以将根节点与左右子树的根节点相连,形成一个完整的树。
折半分解
分治算法其实是二分算法的递归形式,他代表了并行执行,也就是说,如果我们的二分算法面对中间分叉,并不能确定是往左走,还是往右走,我们就可以使用分治算法,递归,左右都给他走一遍。
相当于二分算法是串行的一种迭代算法,而分治算法是一种并行的递归算法。
折半分解是我们在分治法中最常用的,所以这里提出来特别介绍。
此算法常用于递归操作树,划分树的左右子树。
明确分解策略:折半分解,左右边界
(left, right),分解线mid = left + (right - left) / 2寻找最小问题:
left > right或者left >= right划分子类问题:
f(left, mid - 1)和f(mid + 1, right)解决当前问题:
root.left = f(left, mid - 1)和root.right = f(mid + 1, right)
大家可以看看面试题 08.03. 魔术索引这道题,有序,如果使用二分算法,我们不能确定面对分叉是应该往左走,还是往右走,所以我们得使用分治算法,左右都走一遍。
四步走实例
1. 明确分解策略
第一步,明确怎么把大的问题一步步分解为最终的小问题;并明确这个函数的功能是什么,它要完成什么样的一件事。
分解策略:大问题 = n * 小问题。如果大问题是一个数组,那么小问题就是数组中的一个元素。
如果我们的分解策略如果是折半分解,那么我们的函数就需要有范围域(left, right)来确定分解范围;
如果是递减分解,那么我们的函数需要有计数(num),来记录递减分解结果。比如说,快速排序的大的问题可以分解为就是将n个元素摆到正确位置,汉诺塔的大的问题就是将n个圆盘由下而上摆到正确位置。
比如说,快速排序算法的大问题就是将数组中的n个元素进行排序摆放到正确的位置,那么分解而成的小问题就是将数组中的一个元素摆放到正确的位置。
而汉诺塔的大问题就是将A柱子上的n个盘子借用B柱子由大到小放在C柱子上,那么分解而成的小问题就是将A柱子上的最底下的最大盘子借用B放在C柱子上。
而这个功能,是完全由你自己来定义的。也就是说,我们先不管函数里面的代码是什么、怎么写,而首先要明白,你这个函数是要用来干什么的。
例如:面试题 04.02. 最小高度树
给定一个有序整数数组,元素各不相同且按升序排列,编写一个算法,创建一棵高度最小的二叉搜索树。
示例:
给定有序数组: [-10,-3,0,5,9],
一个可能的答案是:[0,-3,9,-10,null,5],它可以表示下面这个高度平衡二叉搜索树:
0
/
-3 9
/ /
-10 5 要做出这个题,
第一步,要明确我们的分解策略,这里因为是二叉树,所以采用的方法一般是通过根节点划分左右子树,我的分解策略是折半分解;
既然分解策略是折半分解,那么我们即将要写出的这个函数必须指明分解范围,不然没有办法进行折半分解。
明确分解策略:大问题=创建一棵高度最小的二叉搜索树,折半分解,小问题=通过根节点划分左右子树,创建一个根左右3个节点的二叉树。
/**
* Definition for a binary tree node.
* public class TreeNode {
* int val;
* TreeNode left;
* TreeNode right;
* TreeNode(int x) { val = x; }
* }
*/
class Solution {
public TreeNode sortedArrayToBST(int[] nums) {
return f(nums, 0, nums.length - 1);
}
// 分治法递归需要重新构造函数
// 按(left, right)区域进行划分子树
// 明确分解策略:大问题=创建一棵高度最小的二叉搜索树,折半分解,小问题=通过根节点划分左右子树,创建一个根左右3个节点的二叉树。
public TreeNode f(int[] nums, int left, int right) {
}
}2. 寻找最小问题(初始条件)
分治就是在函数实现的内部代码中,将大问题不断的分解为子类问题,再将小问题进一步分解为更小的问题。所以,我们必须要找出分治的结束条件,即 给定一个分解的阈值,不然的话,它会一直分解自己,无穷无尽。
- 必须有一个明确的结束条件。因为分治就是有“分”有“并”,所以必须又有一个明确的点,到了这个点,就不用“分解下去”,而是开始“合并”。
第二步,我们需要找出当参数为何值、分解到何种程度时,分治结束,之后直接把结果返回。
(一般为初始条件,然后从初始条件一步一步扩充到最终结果)注意:这个时候我们必须能根据这个参数的值,能够直接知道函数的结果是什么。
让我们继续完善上面那个创建树。
第二步,寻找最小问题:
当left>right时,即 分解为空了,没有根节点,返回null;
那么递归出口就是left>right时函数返回null。
当left=right时,即 分解到只剩一个元素了,我们能够直接知道这最后一个元素就是根节点,返回最后一个元素;
left=right时函数返回new TreeNode(nums[left])(这种情况我们折半分解获取mid创建根节点的时候包含了,所以不写了)
并且这个不是最小的问题。
如下:
// 分治法递归需要重新构造函数
// 按(left, right)区域进行划分子树
// 明确分解策略:大问题=创建一棵高度最小的二叉搜索树,折半分解,小问题=通过根节点划分左右子树,创建一个根左右3个节点的二叉树。
public TreeNode f(int[] nums, int left, int right) {
if (left > right) {
return null;
}
}当然,当l=r时,我们也是知道f(r)等于多少的,f(r)也可以作为递归出口。分治出口可能并不唯一的。
3. 划分子类问题
特别注意:分治算法只去操作解决当前的问题,即 当前元素(如 根节点),对其他划分出来的子类问题(如 左右子树)均不操作解决,只起到划分的作用。
第三步,之前我们明确了分解策略,现在正是使用的时候了,我们需要使用这个分解策略,将大问题分解为子类问题。这样就能一步步分解到最小问题,然后作为函数出口。
- 最小问题:分解至空时,l>r,f(l)即为null
- 分解策略:折半分解,f(nums, l, r) → f(nums, l, (l+r)/2 - 1) , f(nums, (l+r)/2 + 1, r)
- 当前问题:根节点,mid
- 子类问题:左右子树数组,(left, mid-1)和(mid+1, right)。
分治:
- 分:将f(nums, l, r) → f(nums, l, (l+r)/2) , f(nums, (l+r)/2+1, r)了。这样,问题就由n缩小为了n/2,我们只需要找到这n/2个元素的最大值即可。就这样慢慢从f(n),f(n/2)“分”到f(1)。
- 并:这样就可以从1,一步一步“并”到n/2,n...
// 分治法递归需要重新构造函数
// 按(left, right)区域进行划分子树
// 明确分解策略:大问题=创建一棵高度最小的二叉搜索树,折半分解,小问题=通过根节点划分左右子树,创建一个根左右3个节点的二叉树。
public TreeNode f(int[] nums, int left, int right) {
// 寻找最小问题
if (left > right) {
return null;
}
// 划分子类问题:通过根节点划分左右子树,创建一个根左右3个节点的二叉树。
int mid = left + (right - left) / 2;
TreeNode root = new TreeNode(nums[mid]);
f(nums, left, mid - 1);
f(nums, mid + 1, right);
return root;
}4. 解决当前问题
第四步:解决当前问题。
上一步我们将大问题分解为了当前问题+子类问题,那么这个当前问题怎么解决呢,解决这个当前问题,也是为我们接下来的分解提供问题的解决方案,所以不能大意。
解决当前问题的方法,就是比较两个当前问题的大小,得出最大的一个值,问题即可解决。特别注意:分治算法只去操作解决当前的当前问题(如 根节点),对其他划分出来的子类问题(如 左右子树)均不操作解决,只起到划分的作用。
这里的解决合并就是将子类问题合并为一个完整的大问题,方便我们求出大问题的答案,即 创建一个根左右3个节点的二叉树。
// 分治法递归需要重新构造函数
// 按(left, right)区域进行划分子树
// 明确分解策略:大问题=创建一棵高度最小的二叉搜索树,折半分解,小问题=通过根节点划分左右子树,创建一个根左右3个节点的二叉树。
public TreeNode f(int[] nums, int left, int right) {
// 寻找最小问题
if (left > right) {
return null;
}
// 划分子类问题:通过根节点划分左右子树,创建一个根左右3个节点的二叉树。
int mid = left + (right - left) / 2;
TreeNode root = new TreeNode(nums[mid]);
// 解决当前问题:创建一个根左右3个节点的二叉树
root.left = f(nums, left, mid - 1);
root.right = f(nums, mid + 1, right);
return root;
}到这里,分治五步走就完成了,那么这个分治函数的功能我们也就实现了。
可能初学的读者会感觉很奇妙,这就能得到最大值了?
那么,我们来一步一步推一下。
假设n为数组中元素的个数,f(n)则为函数
f(1)只有一个元素,可以得到一个确定的值
f(2)根据f(1)的值,也能确定了
f(4)根据f(2)的值,也能确定下来了
...
f(n/2)
f(n)根据f(n/2)也能确定下来了
你看看是不是解决了,n都能分治得到结果!
当前问题解决技巧
记录第一次满足条件的元素
增加递归出口:
// 结果集:res
if (res != null) {
return;
}当前节点操作:
// 结果集:res
if (条件 && res == null) {
res = node;
return;
}记录最后一次满足条件的元素
当前节点操作:与记录第一次满足条件的元素的区别在于没有判断res == null
// 结果集:res
if (条件) {
res = node;
}记录当前问题节点的前驱节点
遍历完当前问题节点node后,使用pre记录当前节点,然后使用node去继续前进遍历。
dfs(node.left);
visit(node);
pre = node; // 记录当前节点,下一步当前节点就会移到其他位置,所以pre会记录当前节点的前驱结点
dfs(node.right); //node的下一次递归多种分治法解法
面试题 04.06. 后继者
设计一个算法,找出二叉搜索树中指定节点的“下一个”节点(也即中序后继)。
如果指定节点没有对应的“下一个”节点,则返回null。
示例 1:
输入: root = [2,1,3], p = 1
2
/
1 3
输出: 2示例 2:
输入: root = [5,3,6,2,4,null,null,1], p = 6
5
/
3 6
/
2 4
/
1
输出: null按题意写函数功能
inorderSuccessor(root, p)方法就是在树root中找p节点的后继节点。
class Solution {
public TreeNode inorderSuccessor(TreeNode root, TreeNode p) {
if (root == null) {
return null;
}
if (p.val >= root.val) {
return inorderSuccessor(root.right, p);
} else {
TreeNode leftRet = inorderSuccessor(root.left, p);
if (leftRet == null) {
return root;
} else {
return leftRet;
}
}
}
}记录第一次满足条件的元素
如果找到p节点,那就置flag为true,中序遍历到后一个节点时设置结果res。
class Solution {
boolean flag; // 如果找到p节点,那就置为true,遍历到后一个节点时设置结果
TreeNode res;
public TreeNode inorderSuccessor(TreeNode root, TreeNode p) {
dfs(root, p);
return res;
}
public void dfs(TreeNode root, TreeNode p) {
if (root == null) {
return;
}
dfs(root.left, p);
// 要求答案只改一次,不能被覆盖,就只要第一次成功的
if (flag == true && res == null) { // 不能放在最前面作为递归出口,因为需要中序遍历的后一个节点,此处是当前问题(当前节点)
res = root;
return;
}
if (root == p) {
flag = true;
}
dfs(root.right, p);
}
}记录最后一次满足条件的元素
这个题目只要第一次满足条件,所以下面这种解法不成立,但是可以给大家一个样例看看。
class Solution {
boolean flag; // 如果找到p节点,那就置为true,遍历到后一个节点时设置结果
TreeNode res;
public TreeNode inorderSuccessor(TreeNode root, TreeNode p) {
dfs(root, p);
return res;
}
public void dfs(TreeNode root, TreeNode p) {
if (root == null) {
return;
}
dfs(root.left, p);
// 区别在这里!!!!!!!!!!!!!!!!!!!!!!
// 要求答案次次修改,能被覆盖,就只要最后一次成功的
if (flag == true) { // 不能放在最前面作为递归出口,因为需要中序遍历的后一个节点,此处是当前问题(当前节点)
res = root;
return;
}
if (root == p) {
flag = true;
}
dfs(root.right, p);
}
}记录当前问题节点的前驱节点
我们使用pre节点来记录当前问题节点的前驱结点,每次遍历都需要前进(pre = root)。
class Solution {
TreeNode res;
TreeNode pre;
public TreeNode inorderSuccessor(TreeNode root, TreeNode p) {
dfs(root, p);
return res;
}
public void dfs(TreeNode root, TreeNode p) {
if (root == null || res != null) {
return;
}
dfs(root.left, p);
// 要求答案只改一次,不能被覆盖,就只要第一次成功的
if (pre == p && res == null) {
res = root;
return;
}
pre = root; // 前进
dfs(root.right, p);
}
}疑似二分算法
面试题 08.03. 魔术索引
魔术索引。 在数组A[0...n-1]中,有所谓的魔术索引,满足条件A[i] = i。给定一个有序整数数组,编写一种方法找出魔术索引,若有的话,在数组A中找出一个魔术索引,如果没有,则返回-1。若有多个魔术索引,返回索引值最小的一个。
示例1:
输入:nums = [0, 2, 3, 4, 5]
输出:0
说明: 0下标的元素为0示例2:
输入:nums = [1, 1, 1]
输出:1答案
这题我一看,有序,二分查找!结果根本就没办法确定是往左走还是往右走,直接给我没辙了。
就试了试分治算法,递归的二分算法,问题迎刃而解。
// 很遗憾,二分查找并不行,因为无论找到了什么满足条件的元素,其左右都可能出现满足条件的元素
// 只能分治算法
class Solution {
public int findMagicIndex(int[] nums) {
return f(nums, 0, nums.length - 1);
}
public int f(int[] nums, int left, int right) {
if (left > right) {
return -1;
}
int mid = left + (right - left) / 2;
// 左边
int leftAns = f(nums, left, mid - 1);
// 中间
if (leftAns != -1) {
return leftAns;
} else if (mid == nums[mid]) {
return mid;
}
// 右边
return f(nums, mid + 1, right);
}
}面试题 10.05. 稀疏数组搜索
稀疏数组搜索。有个排好序的字符串数组,其中散布着一些空字符串,编写一种方法,找出给定字符串的位置。
示例1:
输入: words = ["at", "", "", "", "ball", "", "", "car", "", "","dad", "", ""], s = "ta"
输出:-1
说明: 不存在返回-1。示例2:
输入:words = ["at", "", "", "", "ball", "", "", "car", "", "","dad", "", ""], s = "ball"
输出:4答案
很明显,虽然有序,但是无法判断中间分叉该向左走还是向右走,所以采用分治算法。
class Solution {
public int findString(String[] words, String s) {
// 有序,二分,可是无法判断中间分叉该左走还是右走
// 分治,递归
return f(words, s, 0, words.length - 1);
}
public int f(String[] words, String s, int left, int right) {
if (left > right) {
return -1;
}
int mid = left + (right - left) / 2;
if (s.equals(words[mid])) {
return mid;
}
int leftAns = f(words, s, left, mid - 1);
if (leftAns != -1) {
return leftAns;
}
int rightAns = f(words, s, mid + 1, right);
if (rightAns != -1) {
return rightAns;
}
return -1;
}
}实例
最大数
在一个数组中找最大的数字。
分解策略:对半分
从l到r中找到最大的一个元素。
// 明确分解策略:大问题=从n个元素中找到最大的数字并返回,折半分解,小问题=从2个元素比较大小找到最大数字并返回。
int f(int[] nums, int l, int r) {
// 寻找最小问题:最小问题即是只有一个元素的时候
if (l >= r) {
return nums[l];
}
// 使用分解策略
int lMax = f(nums, l, (l+r)/2);
int rMax = f(nums, (l+r)/2+1, r);
// 解决次小问题:比较两个元素得到最大的数字
return lMax > rMax ? lMax : rMax;
}汉诺塔
汉诺塔的传说
汉诺塔:汉诺塔(又称河内塔)问题是源于印度一个古老传说的益智玩具。大梵天创造世界的时候做了三根金刚石柱子,在一根柱子上从下往上按照大小顺序摞着 64 片黄金圆盘。大梵天命令婆罗门把圆盘从下面开始按大小顺序重新摆放在另一根柱子上。并且规定,在小圆盘上不能放大圆盘,在三根柱子之间一次只能移动一个圆盘。
假如每秒钟一次,共需多长时间呢?移完这些金片需要 5845. 54 亿年以上,太阳系的预期寿命据说也就是数百亿年。真的过了 5845. 54 亿年,地球上的一切生命,连同梵塔、庙宇等,都早已经灰飞烟灭。
汉诺塔游戏的演示和思路分析:
1 ) 如果是有一个盘,A->C
如果我们有 n>= 2 情况,我们总是可以看做是两个盘 1 .最下边的盘 2. 上面的盘
2 ) 先把 最上面的盘A->B
3 ) 把最下边的盘A->C
4 ) 把B塔的所有盘 从 B->C
汉诺塔游戏的代码实现:
看老师代码演示:
package com.atguigu.dac;
public class Hanoitower {
public static void main(String[] args) {
hanoiTower(10, 'A', 'B', 'C');
}
//汉诺塔的移动的方法
//使用分治算法
// 明确分解策略:我们的问题是有n个盘子,可是如果是n个盘子的话我们不会分,不知道结果;如果盘子数量为1、2、3就好了,所以我们按盘子数依次减一分解
public static void hanoiTower(int num, char a, char b, char c) {
// 寻找最小问题:只有一个盘
//如果只有一个盘
if(num == 1) {
System.out.println("第1个盘从 " + a + "->" + c);
} else {
// 解决次小问题:由于我们是按盘子数-1来进行分解的,所以次小问题是一个盘子和n-1个盘子的汉诺塔,将一个最下面的盘子摆放到正确的位置
//如果我们有 n >= 2 情况,我们总是可以看做是两个盘 1.最下边的一个盘 2. 上面的所有盘
//1. 先把 最上面的所有盘 A->B, 移动过程会使用到 c
hanoiTower(num - 1, a, c, b);
//2. 把最下边的盘 A->C
System.out.println("第" + num + "个盘从 " + a + "->" + c);
//3. 把B塔的所有盘 从 B->C , 移动过程使用到 a塔
hanoiTower(num - 1, b, a, c);
}
}
}面试题 08.06. 汉诺塔问题
在经典汉诺塔问题中,有 3 根柱子及 N 个不同大小的穿孔圆盘,盘子可以滑入任意一根柱子。一开始,所有盘子自上而下按升序依次套在第一根柱子上(即每一个盘子只能放在更大的盘子上面)。移动圆盘时受到以下限制:
(1) 每次只能移动一个盘子;
(2) 盘子只能从柱子顶端滑出移到下一根柱子;
(3) 盘子只能叠在比它大的盘子上。
请编写程序,用栈将所有盘子从第一根柱子移到最后一根柱子。
你需要原地修改栈。
示例1:
输入:A = [2, 1, 0], B = [], C = []
输出:C = [2, 1, 0]示例2:
输入:A = [1, 0], B = [], C = []
输出:C = [1, 0]答案
- 当前问题:把最底下的第n块移过去
- 子类问题:把n-1块移过去
class Solution {
/**
* 将 A 上的所有盘子,借助 B,移动到C 上
* @param A 原柱子
* @param B 辅助柱子
* @param C 目标柱子
*/
public void hanota(List<Integer> A, List<Integer> B, List<Integer> C) {
movePlate(A.size(), A, B, C);
}
private void movePlate(int num, List<Integer> A, List<Integer> B, List<Integer> C) {
if (num == 1) { // 只剩一个盘子时,直接移动即可
C.add(A.remove(A.size() - 1));
return;
}
movePlate(num - 1, A, C, B); // 将 size-1 个盘子,从 A 移动到 B
movePlate(1, A, B, C);
// C.add(A.remove(A.size() - 1)); // 将 第size个盘子,从 A 移动到 C
movePlate(num - 1, B, A, C); // 将 size-1 个盘子,从 B 移动到 C
}
}面试题 04.02. 最小高度树
给定一个有序整数数组,元素各不相同且按升序排列,编写一个算法,创建一棵高度最小的二叉搜索树。
示例:
给定有序数组: [-10,-3,0,5,9],
一个可能的答案是:[0,-3,9,-10,null,5],它可以表示下面这个高度平衡二叉搜索树:
0
/
-3 9
/ /
-10 5 答案
/**
* Definition for a binary tree node.
* public class TreeNode {
* int val;
* TreeNode left;
* TreeNode right;
* TreeNode(int x) { val = x; }
* }
*/
class Solution {
public TreeNode sortedArrayToBST(int[] nums) {
return f(nums, 0, nums.length - 1);
}
// 二分法需要重新构造函数
public TreeNode f(int[] nums, int left, int right) {
if (left > right) {
return null;
}
int mid = left + (right - left) / 2;
TreeNode root = new TreeNode(nums[mid]);
root.left = f(nums, left, mid - 1);
root.right = f(nums, mid + 1, right);
return root;
}
}通过先序和中序数组生成后序数组
给出一棵二叉树的先序和中序数组,通过这两个数组直接生成正确的后序数组。
示例1
输入
[1,2,3],[2,1,3]输出
[2,3,1]答案
常规做法:先序遍历划分,中序遍历划分,public void f(int[] preOrder, int left1, int right1, int[] inOrder, int left2, int right2) {
- 先序遍历的第一个元素作为根节点
- 然后拿着根节点去中序遍历寻找可以得知其左右子树分别的数量
- 拿着这个数量,我们就可以再去先序遍历里面进行划分左右子树
- 这样就能递归得到后序遍历(左右根)了
import java.util.*;
public class Solution {
/**
*
* @param preOrder int整型一维数组 the array1
* @param inOrder int整型一维数组 the array2
* @return int整型一维数组
*/
public int[] postOrder;
public int num;
public int[] findOrder (int[] preOrder, int[] inOrder) {
// write code here
// 先序:根左右
// 中序:左根右
// 后序:左右根
postOrder = new int[preOrder.length];
f(preOrder, 0, preOrder.length - 1, inOrder, 0, preOrder.length - 1);
return postOrder;
}
// 从先序里面找到第一个元素,就是根节点,
// 然后带着根节点去中序里面划分出左右子树的个数
// 再带着左右子树的个数去划分先序数组
// 函数功能:从先序找出第一个root,划分中序的左右
// root仅与先序遍历中的根节点索引有关
// left和right仅与中序遍历中的左右指针划分有关
public void f(int[] preOrder, int left1, int right1, int[] inOrder, int left2, int right2) {
if (left1 > right1 || left2 > right2) {
return;
}
// 在中序中找到根节点位置i
int i = 0;
for (i = left2; i < right2 && inOrder[i] != preOrder[left1]; i++);
int leftLength = i - left2;
int rightLength = right2 - i;
// 左
f(preOrder, left1 + 1, left1 + leftLength, inOrder, left2, i - 1);
// 右
f(preOrder, right2 - rightLength + 1, right2, inOrder, i + 1, right2);
// 根
postOrder[num++] = preOrder[left1];
}
}答案二
简化做法:先序遍历找根,中序遍历划分,public void f(int[] preOrder, int root, int[] inOrder, int left, int right) {
- 在先序遍历中找出根节点
- 在中序遍历中进行左右划分
- 在中序遍历中划分后,利用划分的左右子树数量,重新在先序遍历中找到根节点。
原问题 = 当前问题 + 子类问题
- 当前问题:找到根节点进行划分,然后按后序遍历(左右根)去存储
- 子类问题:依据根节点将中序遍历划分为左右子树中序遍历,用左右子树数量去先序遍历中找到左右子树根节点。(即 组成了与原问题相同结构的子类问题,左右子树中序遍历+左右子树先序遍历根节点)
import java.util.*;
public class Solution {
/**
*
* @param preOrder int整型一维数组 the array1
* @param inOrder int整型一维数组 the array2
* @return int整型一维数组
*/
public int[] postOrder;
public int num;
public int[] findOrder (int[] preOrder, int[] inOrder) {
// write code here
// 先序:根左右
// 中序:左根右
// 后序:左右根
postOrder = new int[preOrder.length];
f(preOrder, 0, inOrder, 0, preOrder.length - 1);
return postOrder;
}
// 从先序里面找到第一个元素,就是根节点,
// 然后带着根节点去中序里面划分出左右子树的个数
// 再带着左右子树的个数去划分先序数组
// 函数功能:从先序找出第一个root,划分中序的左右
// root仅与先序遍历中的根节点索引有关
// left和right仅与中序遍历中的左右指针划分有关
public void f(int[] preOrder, int root, int[] inOrder, int left, int right) {
if (left > right) {
return;
}
// 在中序中找到根节点位置i
int i = 0;
for (i = left; i < right && inOrder[i] != preOrder[root]; i++);
// 左
f(preOrder, root + 1, inOrder, left, i - 1);
// 右
f(preOrder, root + i - left + 1, inOrder, i + 1, right);
// 根
postOrder[num++] = preOrder[root];
}
}面试题 17.12. BiNode
二叉树数据结构TreeNode可用来表示单向链表(其中left置空,right为下一个链表节点)。实现一个方法,把二叉搜索树转换为单向链表,要求依然符合二叉搜索树的性质,转换操作应是原址的,也就是在原始的二叉搜索树上直接修改。
返回转换后的单向链表的头节点。
注意:本题相对原题稍作改动
示例:
输入: [4,2,5,1,3,null,6,0]
输出: [0,null,1,null,2,null,3,null,4,null,5,null,6]只能操作当前元素
下面一定要注意了,只能操作当前元素,左右子树只起到划分的作用。
/**
* Definition for a binary tree node.
* public class TreeNode {
* int val;
* TreeNode left;
* TreeNode right;
* TreeNode(int x) { val = x; }
* }
*/
class Solution {
TreeNode pre; // 链表的上一个元素
// 二叉搜索树中序遍历有序
public TreeNode convertBiNode(TreeNode root) {
TreeNode head = new TreeNode(0); // 单链表的伪头节点
pre = head;
f(root);
return head.right;
}
// 二叉搜索树中序遍历有序
public void f(TreeNode root) {
if (root == null) {
return;
}
// 划分左子树
f(root.left);
// 只能操作当前元素
pre.right = root;
root.left = null;
pre = root;
// 划分右子树
f(root.right);
}
}因为分治算法一般都应用于操作树,所以大家可以看看:【数据结构】树