1 字符编码简介
ASCII码:美国人发明并使用,用1个字节(8位二进制)代表一个字符,ASCII码是其他任意编码表的子集(utf-16除外).
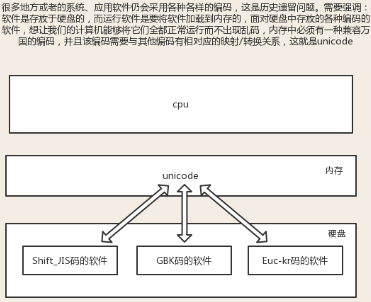
Unicode:包含和兼容全世界的语言,与全世界的语言都有映射关系,常用2个字节表示一个字符,1个生僻字用4个字节表示.
utf-8:可变长编码,英文用1个字节表示,汉字通常是3个字节,生僻字常用4-6个字节表示,uft-8比Unicode编码节省空间和I/O开销.
关于Unicode和utf-x格式之间的关系,可以认为utf-x是Unicode的一种特殊类型,在存取数据时,内部会自动在Unicode和utf-x之间转换.
在内存中,统一使用的都是Unicode编码(固定,集成在操作系统中),所以可以转换为任意其他国家自定义的编码(这样就不会乱码);在将数据存入硬盘时,需要将Unicode转换为一种更精准的格式,即utf-8,将数据控制在最精准和节省空间;而磁盘数据读入缓存到内存中时,则需要将utf-8转换为Unicode.
在python2.x中,默认使用ASCII编码作为字符编码;而在python3.x中,默认使用Unicode作为默认字符编码.
import sys print(sys.getdefaultencoding()) 'ascii' #python2.x默认字符编码 --------------------------------- import sys print(sys.getdefaultencoding()) 'utf-8' #python3.x默认字符编码 --------------------------------- U=u'阿凡达' #3*3=9字节,8*9=72bytes U1=bytes(U,'utf-8') print(U1) # 构造Unicode字符,结果是 b'xe9x98xbfxe5x87xa1xe8xbexbe',x代表16进制存储,1个字符代表4byte,18*4=72bytes
1.1 字符编码和解码
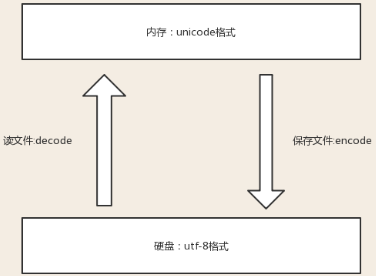
两张图读懂字符编码与解码之间的关系,编码和解码对应,就不会出现乱码了,参考资料及图片来源:
https://www.cnblogs.com/f-ck-need-u/p/10185965.html
https://www.cnblogs.com/linhaifeng/articles/5950339.html
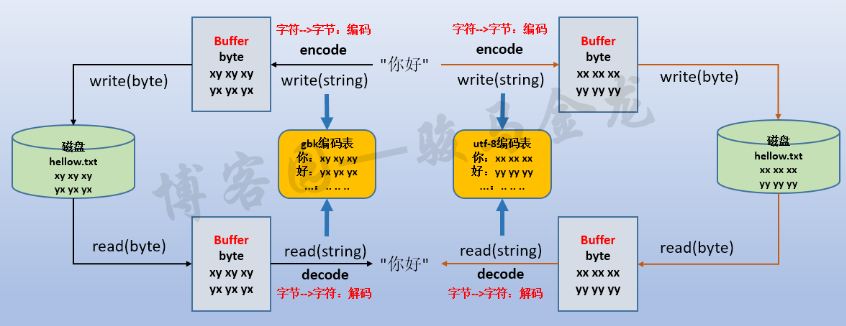
编码: str ---> bytes (encode) 解码: bytes ---> str (decode) 二进制格式的数据也常称为裸数据(raw data),str数据经过编码后得到raw data,raw data解码后得到的str. 内存中是unicode-------->encode编码保存-------->utf-8保存到磁盘(二进制) utf-8磁盘里保存-------->decode解码缓存到内存中---------->unicode内存中
注意: 编码和解码的过程中,与软件指定的编码(字符集)也有关系,必须对应. ###################### print((set(dir(str)))-set(dir(bytes))) #字符串类型只有编码encode()方法,没有解码decode() print((set(dir(bytes)))-set(dir(str))) #字节串类型只有解码decode()方法,没有编码encode() -------------------- {'format', 'isdecimal', 'casefold', 'format_map', 'isidentifier', 'isnumeric', 'isprintable', 'encode'} {'hex', 'decode', 'fromhex'}
1.2 str,bytes,bytearray类型
str:字符串类型,有序有索引,序列数据,可以迭代取值,但属于不可变类型,底层存储由一个个二进制组成,也就是bytes.python3.x中str默认是Unicode(uft-8)格式编码.
bytes:字节串类型,二进制字节数据,有序有索引,序列数据,可以迭代取值,也属于不可变类型;将字符串数据存到硬盘的的过程,实质上就是将Unicode转换为utf-8下的二进制字节这样就可以往硬盘存数据(二进制转换为十六进制存),或通过网络方式传输到其他地方.
bytearray:可变的字节串类型,属于可变的二进制数据(bytes),属于可变类型.
import sys #python3.x下查看默认字符编码为 utf-8 print(sys.getdefaultencoding()) #结果是 utf-8 ---------------------------- B=b'aaa' print(type(B),B) #构造bytes类型,需在字符串前加 b ,结果是<class 'bytes'> b'aaa' ---------------------------- B=b'aaa' # 构造bytearray类型及改值 By=bytearray(B) print(type(By),By) print(list(i for i in By)) By[0]=98 #改值 print(By) #By=b'baa',a子串值已改变 -------构造bytearray结果 <class 'bytearray'> bytearray(b'aaa') [97, 97, 97] bytearray(b'baa')
1.3 乱码的原因及解决办法
文件从内存写到硬盘的操作简称存文件,文件从硬盘读到内存的操作简称读文件.
乱码的原因:
1)存文件时就已经乱码(编辑的字符和编辑器设定保存的字符编码不一致)
2)存文件时不乱码而读文件时乱码(存时的文件字符编码和读时编辑器设定的字符编码不对应)
解决乱码的办法: 字符按照什么标准而编码的,就要按照什么标准解码,即编码和解码对应.
1.4 python文件头指定字符编码
为了避免乱码,在python文件中指定解释器和文件头也是一种方法,文件头指定的编码必须跟python文件存储时用的编码一致.
#!/usr/bin/env python <===指定解释器(限linux) # -*- coding: utf-8 -*- <===指定字符编码(等同于#coding:utf-8)来将数据读入内存,由python解释器解释执行用的字符编码