1 python操作文件介绍
文件是操作系统提供给应用程序操作硬盘的一个对象,一个虚拟单位,用于应用程序将数据永久保存在硬盘中.
在python中,操作文件主要有以下几个步骤:
# 1. 打开文件,得到文件句柄并赋值给一个变量,其完整的格式如下:
f=open('file', mode='r', buffering=-1, encoding=None, errors=None, newline=None, closefd=True, opener=None)
# 2. 通过句柄对文件进行操作(读/写/追加等)
data=f.read()
# 3. 关闭文件,回收操作系统的资源(关闭后,文件已不可打开,因为操作系统方面的资源已被关闭)
f.close()
# 4. 删除文件del f ,此步骤可以忽略不写(应用程序级别),因为python解释器有自动的垃圾回收机制,但删除步骤del f,必须放在f.close之后.
open()函数中接收的参数解释(常用的是file,mode,encoding):
file: 必需,文件路径(相对或者绝对路径),注意windows系统下通常需要在前面加 r ,防止转义 mode: 可选,文件打开模式,默认是rt,即以只读方式打开文本文件 buffering: 设置缓冲 encoding: 可选,操作文件使用的字符编码,一般使用utf8,如果不指定,就以操作系统的字符编码打开文件(编码不对会乱码) errors: 报错级别 newline: 区分换行符 closefd: 传入的file参数类型 opener:
1.1 f=open()过程分析及mode参数说明
过程:
1)由应用程序向操作系统发起系统调用open(...).
2)操作系统打开该文件,并返回一个文件句柄给应用程序.
3)应用程序将文件句柄赋值给变量f.
注意:open()打开的是本机上文件,并且,open()函数内无论是读/写/追加内容,统一使用 作为换行符.
mode参数说明:
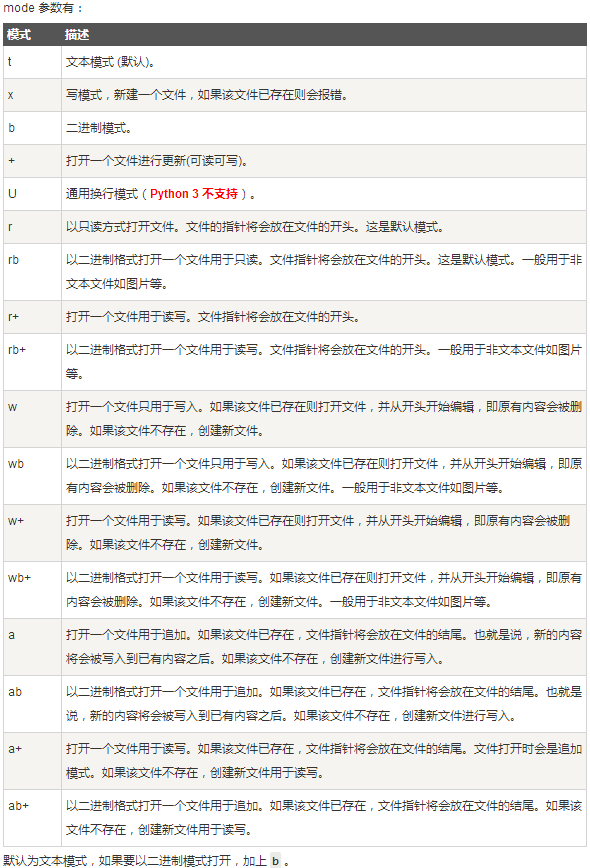
其中,重要的如下:
# 对于文本文件(默认rt),读写都是以字符串为单位,需要指定字符编码 r :只读模式【默认模式,文件必须存在,不存在则抛出异常】 w :只写模式【不可读;不存在则创建;存在则清空内容】 a :追加写模式【不可读;不存在则创建;存在则只追加内容】,应用场景:日志文件 # 对于非文本文件(如图片,视频等),只能以b模式处理,且无需考虑字符编码 rb :读取时,解码decode='utf-8',可以看到原本的内容 wb :写入时,指定encode='utf-8'写入,就是bytes类型 ab 注意:以b方式打开时,读取到的内容是字节类型,写入时也需要提供字节类型,不能指定编码
实例:
f=open('b.txt',encoding='utf-8') #这样写,默认省略了mode='rt',不能只写t,不写r,会报错,可以只写r,不写t
f=open('b.txt',encoding='utf-8') #mode='w',文件中内容会被覆盖,无此文件会新创建
data=f.write('asdasd') #只读模式下不可写,not writable
f=open('b.txt',mode='w',encoding='utf-8') #mode='w',文件中内容会被覆盖,无此文件会新创建
f.write('aaaaaaaa
bbbbbbbb
')
data=f.read() #只写模式下不可读,not readable
f=open('b.txt',mode='rt',encoding='utf-8')
print(f.readline(),end='') #print自带换行,readline以行为单位读取,不加end=''会多一行空行
with open('b.txt',mode='w',encoding='utf-8') as f:
f.write('aaaaa
bbbbb
') #每写完一行,光标移到最后
f.write('ccccc
ddddd
') #只写模式下需要自己加换行符
with open('b.txt',mode='w',encoding='utf-8') as f:
f.writelines(['111111
','222222
','3333333
']) #相当于for循环列表内元素后放到文件中,对应readlines()
with open('b.txt',mode='w',encoding='utf-8') as f:
f.write('111111
22222
333333') #此种模式下写入,只可以接收字符串,不像writelines()列表,可以是所有数据类型
# a 模式,追加写模式,通常用于日志文件,文件存在时,追加内容,光标移到末尾,文件不存在则创建空文件并追加内容
with open('b.txt',mode='a',encoding='utf-8') as f:
f.write('111111
') #追加写模式,每次追加写光标都在末尾,需要手工添加换行符
,确定是否换行
1.2 file对象对应的方法说明
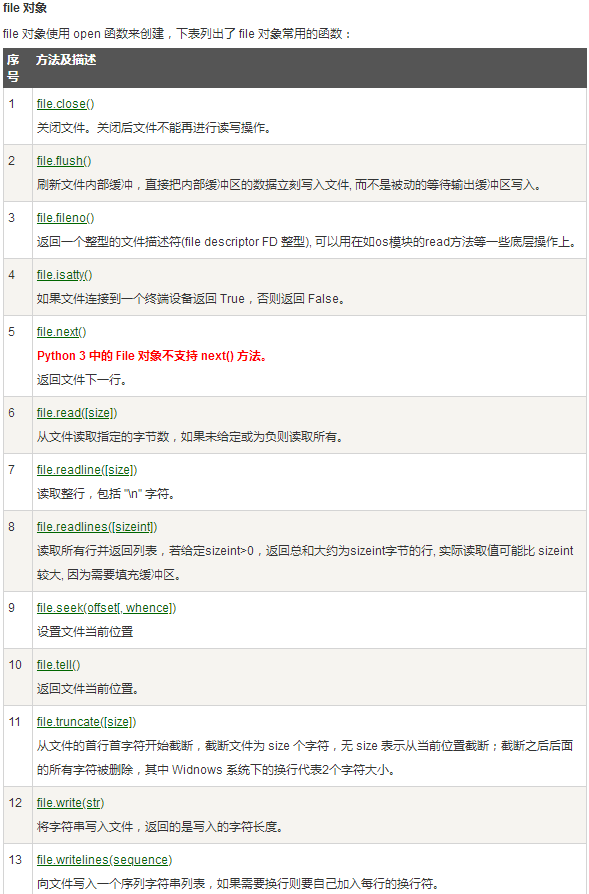
重要的方法:
#以下在没有执行f.close()的情况下,资源还未关闭,有文件光标的概念
f.read() #刚打开时,光标停在内容开头,当读取完所有内容,光标移动到文件末尾
f.readline() #以行为单位读取文件内容,读取完一行内容后,光标会移动到第二行首部(文件过大,读取可能会卡死)
f.readlines() #读取所有内容,以行分隔每一行内容,并存放于列表中,读完后,光标移到最后(文件过大,可能会卡死)
------------------------------------
f=open('b.txt',mode='rt',encoding='utf-8')
print(f.readlines()) #['aaaaaaaa
', 'bbbbbbbb
']以行为单位切分为一个列表,对应writelines([list])
------------------------------------
f.write('1111
222
') #针对文本模式的写,需要自己写换行符
f.write('1111
222
'.encode('utf-8')) #针对b模式的写,需要自己写换行符
f.writelines(['333
','444
']) #文件模式,对应读的readlines
f.writelines([bytes('333
',encoding='utf-8'),'444
'.encode('utf-8')]) #b模式
------------------------------------
f.readable() #判断文件是否可读,可读返回True,否则返回False
f.writable() #文件是否可写,可写返回True,否则返回False
f.closed #判断文件是否关闭,是返回True,否则返回False
f.encoding #如果文件打开模式为b,则没有该属性
f.flush() #立刻将文件内容从内存刷到硬盘
f.name
1.3 小结
每打开一个文件,操作系统都要分配一个文件描述符(文件描述符有限),并维护此文件的打开状态,返回一个值给应用程序.
关于对文件操作的方法,如open(),f.read(),f.close(),都涉及到系统调用,因为应用程序无法直接对硬件进行操作.任何对于硬件的操作,都需要通过操作系统来发起系统调用systemcall,来转换为底层的硬件操作.
使用open()函数的常用形式是接收2个参数:文件名(file)和模式(mode),使用open()打开一个文件,包含了2个方面的资源:操作系统打开的文件+应用程序的变量,所以在操作完一个文件,必须把这2个方面的资源一起回收.因为python有自动垃圾回收机制,所以,应用程序的资源可以忽略,但操作系统的资源补必须手动回收,即f.close().
常用 with 关键字,来管理上下文,避免忘记 f.close.
1.4 利用关键字with管理上下文
with关键字的作用:管理上下文,即打开文件,完成操作后,自动回收资源,无需close了.
with open('a.txt','r') as f1,open('b.txt','w') as f2: #同时处理多个文件使用逗号隔开,要换行需要使用续行符
data=f1.read() #子代码块
f2.write(data) #子代码块
实例:
with open('b.txt',encoding='utf-8') as f: #此种方式不会造成内存被撑爆,读一行取一行
for line in f:
print(line,end='')
-------------------------------
for line in f.readlines(): #此种方式可能会造成系统卡顿(文件过大)甚至崩溃
print(line,end='') #因为是一次性读
结果--------------------------
aaaaaaaa
bbbbbbbb
1.5 b模式下对文件的操作
操作文本文件,默认以rt模式操作,只能对文本文件操作,不能对非文本文件进行操作.
以b模式可以操作文本文件,读写都是以bytes为单位,可以进行encode编码/decode解码操作.
b模式下操作图片,视频等其他文件,不能进行decode操作.
对所有类型的文件操作,最好使用b模式,b模式具有跨平台性,但需要对数据做转换,即encode.
实例:
# b 模式,不能单独使用,必须是rb/wb/ab
# b 模式下读写都是以bytes为单位,无需考虑字符编码的问题,不能也无需指定encoding参数
with open('1.jpg',mode='rb') as f:
data=f.read() #文件不存在会报错No such file or directory
print(data,type(data)) #图片格式底层也是用bytes字节串/二进制存储
with open('b.txt',mode='rb') as f: #b模式下,读取文本文件(文本中存在且有内容)
data=f.read()
print(data,type(data))
print(data.decode('utf-8')) #解码decode才可以看到对应文件中的内容(以什么编码就以什么解码),显示在pycharm工具中
with open('c.txt',mode='wb') as f:
msg='阿萨德'
data=f.write(msg.encode('utf-8')) #b模式下需指定编码encode写入内容至文件中,文件中内容为 阿萨德
with open('c.txt',mode='rb') as f:
data=f.read()
print(type(data)) #<class 'bytes'>字节串类型
print(data.decode('utf-8')) #读取的文件内容为阿萨德,指定编码读内容
with open('c.txt',mode='ab') as f:
f.write('撒旦'.encode('utf-8')) #指定encode追加写入
with open('1.jpg',mode='rb') as f:
for line in f:
print(line) #b模式下,读取图片格式的每行内容
2. 文件内光标的移动
原文本文件内容为:
张三 男 20 11122233344 李四 男 21 22233344455 王一 女 22 33344455566
执行with语句:
with open('c.txt','r+',encoding='utf-8') as f: #使用r+,光标在开头
f.seek(9) #指定偏移量,光标从开头往后移动3个位置(注意偏移量单位是字节)
print(f.tell()) #查看当前光标位置
print(f.read()) #上面指定了偏移量,这里读出来的结果会跳过光标之前的内容
---------读出的结果
9
男 20 11122233344
李四 男 21 22233344455
王一 女 22 33344455566
3 python修改文件的2种方式
注意:硬盘内的数据的修改都是以新的覆盖旧的.
1)将硬盘存放的该文件的内容全部加载到内存,在内存中修改,修改完毕后,再把结果由内存覆盖到硬盘(word,vim,nodpad++等编辑器).缺点:文件如果过大,可能导致机器卡死.
with open('c.txt',mode='r',encoding='utf-8') as f:
data=f.read()
data=data.replace('张三','张三三') #replace替换内容,注意这里仅仅是在内存中替换,并没有写到硬盘
with open('c.txt',mode='w',encoding='utf-8') as f:
f.write(data) #内存中已有替换的内容被写入到硬盘
2)建议使用:以读的方式打开原文件,将硬盘存放的该文件的内容一行一行地读入内存(for循环),修改完毕就写入新文件,最后用新文件覆盖源文件.(解决内存占用大的问题,但会多打开一个新文件,占用硬盘资源)
import os
with open('c.txt',mode='r',encoding='utf-8') as f_read,
open('cc.txt',mode='w',encoding='utf-8') as f_write:
for line in f_read:
if '李四' in line:
line=line.replace('李四','李四四')
f_write.write(line) #这里跟判断无关
os.remove('c.txt') #删除
os.rename('cc.txt','c.txt') #重命名