MapReduce
分布式需要解决的问题:
将运算转移到数据上?运算变成分布式,结果为局部的结果了
如何分发代码?
1.拷贝、启动代码。启动最后一台的时候可能第一台运行结束了
2.代码分发到了哪些机器上运行?
3.有一台机器宕机了,局部结果没了,那汇总的结果就没意义了。因此需要时刻监控节点情况,看哪个正常,哪个不正常
4.汇总到某一台机器(负载高)还是汇总到几台机器上(逻辑复杂)?
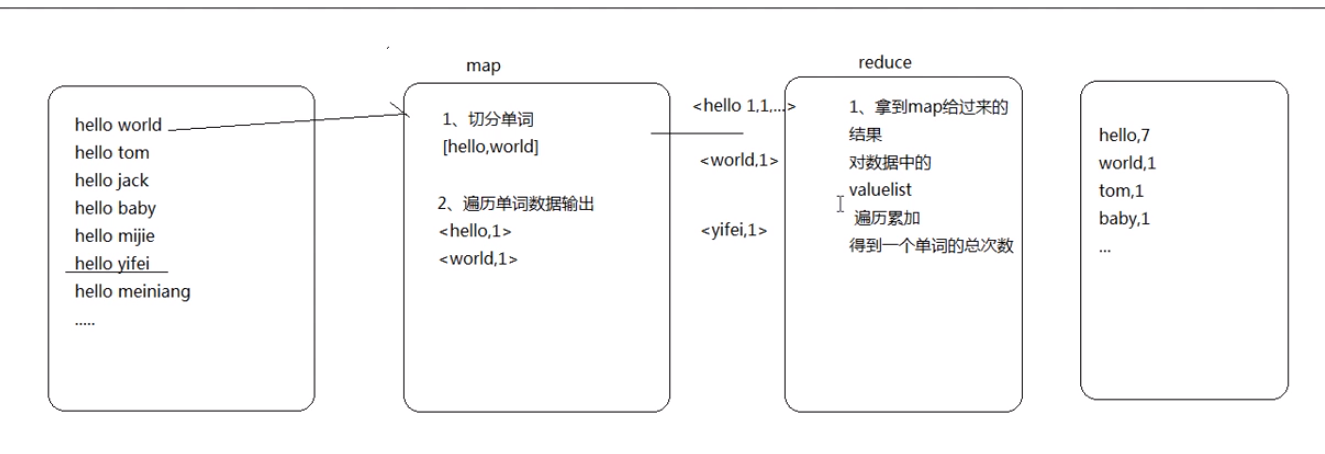
例子:统计单词出现的次数
//4个泛型中,前两个是指定mapper输入数据的类型,KEYIN是输入的key的类型,VALUEIN是输入的value的类型 //map 和 reduce 的数据输入输出都是以 key-value对的形式封装的 //默认情况下,框架传递给我们的mapper的输入数据中,key是要处理的文本中一行的起始偏移量,这一行的内容作为value public class WCMapper extends Mapper<LongWritable, Text, Text, LongWritable>{ //mapreduce框架每读一行数据就调用一次该方法 @Override protected void map(LongWritable key, Text value,Context context) throws IOException, InterruptedException { //具体业务逻辑就写在这个方法体中,而且我们业务要处理的数据已经被框架传递进来,在方法的参数中 key-value //key 是这一行数据的起始偏移量 value 是这一行的文本内容 //将这一行的内容转换成string类型 String line = value.toString(); //对这一行的文本按特定分隔符切分 String[] words = StringUtils.split(line, " "); //遍历这个单词数组输出为kv形式 k:单词 v : 1 for(String word : words){ context.write(new Text(word), new LongWritable(1)); } } }
public class WCReducer extends Reducer<Text, LongWritable, Text, LongWritable>{ //框架在map处理完成之后,将所有kv对缓存起来,进行分组,然后传递一个组<key,valus{}>,调用一次reduce方法 //<hello,{1,1,1,1,1,1.....}> @Override protected void reduce(Text key, Iterable<LongWritable> values,Context context) throws IOException, InterruptedException { long count = 0; //遍历value的list,进行累加求和 for(LongWritable value:values){ count += value.get(); } //输出这一个单词的统计结果 context.write(key, new LongWritable(count)); } }
WCRunner
/** * 用来描述一个特定的作业 * 比如,该作业使用哪个类作为逻辑处理中的map,哪个作为reduce * 还可以指定该作业要处理的数据所在的路径 * 还可以指定改作业输出的结果放到哪个路径 * .... * @author duanhaitao@itcast.cn * */ public class WCRunner { public static void main(String[] args) throws Exception { Configuration conf = new Configuration(); Job wcjob = Job.getInstance(conf); //设置整个job所用的那些类在哪个jar包 wcjob.setJarByClass(WCRunner.class); //本job使用的mapper和reducer的类 wcjob.setMapperClass(WCMapper.class); wcjob.setReducerClass(WCReducer.class); //指定本job使用combiner组件,组件所用的类为 wcjob.setCombinerClass(WCReducer.class); //指定reduce的输出数据kv类型 wcjob.setOutputKeyClass(Text.class); wcjob.setOutputValueClass(LongWritable.class); //指定mapper的输出数据kv类型 wcjob.setMapOutputKeyClass(Text.class); wcjob.setMapOutputValueClass(LongWritable.class); //指定要处理的输入数据存放路径 FileInputFormat.setInputPaths(wcjob, new Path("hdfs://weekend110:9000/wc/srcdata/")); //指定处理结果的输出数据存放路径 FileOutputFormat.setOutputPath(wcjob, new Path("hdfs://weekend110:9000/wc/output2/")); //将job提交给集群运行 wcjob.waitForCompletion(true); } }
[hadoop@weekend110 ~]$ hadoop jar wc.jar cn.itcast.hadoop.mr.wordcount.WCRunner
MRAppMaster(动态产生):MR的管理进程,管理yarnchild(动态产生),由MR框架实现,yarn框架帮忙启动
资源调度中起监控作用的:RESOURCEMANAGER ------管理node manager节点
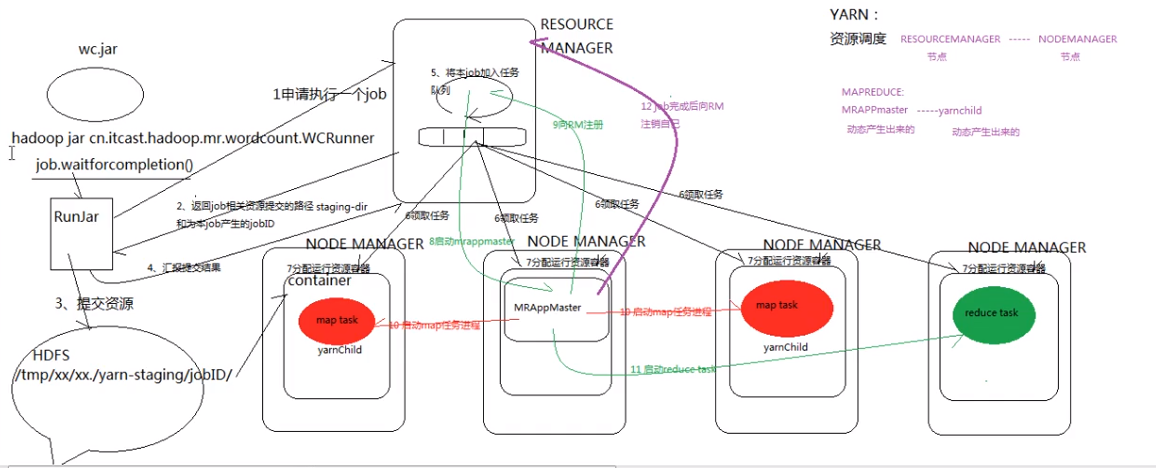
MR程序的几种提交运行模式
什么时候在本地运行,什么条件下在集群中运行?
根据配置信息来决定
