这是离开公司前做的最后一个算法,之前做的一些算法,由于老大的指点,少走了很多弯路,密度峰值聚类这个是纯粹自己做的,走了很多弯路,在这里和大家分享借鉴一下,共勉!
一、简单介绍及原理
顾名思义,这是一种基于密度的聚类算法,以高密度区域作为判断依据,这种非参数的方法,和传统方法比,适用于处理任何形状的数据集,而且无需提前设置簇的数量。
这里提到一个聚类中心的概念:类簇的中心是由一些局部密度较低的点所围绕,且这些点距离其他高密度的点的距离都比较远,通过计算最近邻的距离,得到聚类中心,并依据密度大小进行排列。
我在这里借鉴了——马春来,单洪,马涛.一种基于簇中心点自动选择策略的密度峰值聚类算法.计算机科学.2016,43(7)。这个文献中提供了一种自动选择策略的方法,大家有兴趣可以看一下。
对于一个数据集D={p1,p2,……pn}的点pi,计算每个点的局部密度ρi和相邻密度点的距离di,这里提出一个概念,簇中心权值:γi= ρi * di 。
通过将簇中心权值降序排列,我们可以通过下降的趋势(斜率)找出拐点所在。
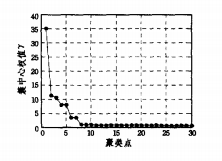

下图为选择聚类中心的方法

省略了不少东西,大家可以下载那份文献自己细细研读。
二、一些遇到的问题及我的心得
1、有现成的代码固然好,但是别人的代码解决的问题终归和你的问题不一样。不如自己从头到尾撸一遍,结合自己的情况进行修改。
2、传统的密度峰值聚类需要自己设置参数,稍微加以改进可以扔掉参数,让它自己迭代。
3、为什么要将密度和距离相乘:这样可以避免某一项的值过小,导致特征不明显
4、注意归一化的问题,具体情况具体对待。(在归一化这个问题坑了我蛮久)
5、拐点的确定问题,在算法构建的初始阶段,最好人工重复确认一下,避免盲目自信到后面找不到问题所在。
6、若某两个或多个聚类点距离较近,将其归为一个同一个聚类中心。