RCNN- 将CNN引入目标检测的开山之作
前面一直在写传统机器学习。从本篇开始写一写 深度学习的内容。 可能需要一定的神经网络基础(可以参考 Neural networks and deep learning 日后可能会在专栏发布自己的中文版笔记)。
RCNN (论文:Rich feature hierarchies for accurate object detection and semantic segmentation) 是将CNN方法引入目标检测领域, 大大提高了目标检测效果,可以说改变了目标检测领域的主要研究思路, 紧随其后的系列文章:( RCNN),Fast RCNN, Faster RCNN 代表该领域当前最高水准。
【论文主要特点】(相对传统方法的改进)
- 速度: 经典的目标检测算法使用滑动窗法依次判断所有可能的区域。本文则(采用Selective Search方法)预先提取一系列较可能是物体的候选区域,之后仅在这些候选区域上(采用CNN)提取特征,进行判断。
- 训练集: 经典的目标检测算法在区域中提取人工设定的特征。本文则采用深度网络进行特征提取。使用两个数据库: 一个较大的识别库(ImageNet ILSVC 2012):标定每张图片中物体的类别。一千万图像,1000类。 一个较小的检测库(PASCAL VOC 2007):标定每张图片中,物体的类别和位置,一万图像,20类。 本文使用识别库进行预训练得到CNN(有监督预训练),而后用检测库调优参数,最后在检测库上评测。
看到这里也许你已经对很多名词很困惑,下面会解释。先来看看它的基本流程:
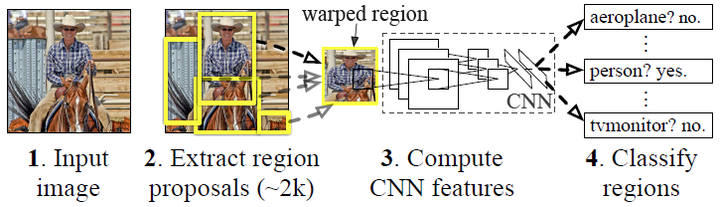
【基本流程 ===================================】
RCNN算法分为4个步骤
- 候选区域生成: 一张图像生成1K~2K个候选区域 (采用Selective Search 方法)
- 特征提取: 对每个候选区域,使用深度卷积网络提取特征 (CNN)
- 类别判断: 特征送入每一类的SVM 分类器,判别是否属于该类
- 位置精修: 使用回归器精细修正候选框位置
【基础知识 ===================================】
Selective Search 主要思想:
- 使用一种过分割手段,将图像分割成小区域 (1k~2k 个)
- 查看现有小区域,按照合并规则合并可能性最高的相邻两个区域。重复直到整张图像合并成一个区域位置
- 输出所有曾经存在过的区域,所谓候选区域
其中合并规则如下: 优先合并以下四种区域:
- 颜色(颜色直方图)相近的
- 纹理(梯度直方图)相近的
- 合并后总面积小的: 保证合并操作的尺度较为均匀,避免一个大区域陆续“吃掉”其他小区域 (例:设有区域a-b-c-d-e-f-g-h。较好的合并方式是:ab-cd-ef-gh -> abcd-efgh -> abcdefgh。 不好的合并方法是:ab-c-d-e-f-g-h ->abcd-e-f-g-h ->abcdef-gh -> abcdefgh)
- 合并后,总面积在其BBOX中所占比例大的: 保证合并后形状规则。

上述四条规则只涉及区域的颜色直方图、梯度直方图、面积和位置。合并后的区域特征可以直接由子区域特征计算而来,速度较快。
有监督预训练与无监督预训练:
(1)无监督预训练(Unsupervised pre-training)
预训练阶段的样本不需要人工标注数据,所以就叫做无监督预训练。
(2)有监督预训练(Supervised pre-training)
所谓的有监督预训练也可以把它称之为迁移学习。比如你已经有一大堆标注好的人脸年龄分类的图片数据,训练了一个CNN,用于人脸的年龄识别。然后当你遇到新的项目任务时:人脸性别识别,那么这个时候你可以利用已经训练好的年龄识别CNN模型,去掉最后一层,然后其它的网络层参数就直接复制过来,继续进行训练,让它输出性别。这就是所谓的迁移学习,说的简单一点就是把一个任务训练好的参数,拿到另外一个任务,作为神经网络的初始参数值,这样相比于你直接采用随机初始化的方法,精度可以有很大的提高。
对于目标检测问题: 图片分类标注好的训练数据非常多,但是物体检测的标注数据却很少,如何用少量的标注数据,训练高质量的模型,这就是文献最大的特点,这篇论文采用了迁移学习的思想: 先用了ILSVRC2012这个训练数据库(这是一个图片分类训练数据库),先进行网络图片分类训练。这个数据库有大量的标注数据,共包含了1000种类别物体,因此预训练阶段CNN模型的输出是1000个神经元(当然也直接可以采用Alexnet训练好的模型参数)。