联邦学习(Federated Learning)
联邦学习简介
联邦学习(Federated Learning)是一种新兴的人工智能基础技术,在 2016 年由谷歌最先提出,原本用于解决安卓手机终端用户在本地更新模型的问题,其设计目标是在保障大数据交换时的信息安全、保护终端数据和个人数据隐私、保证合法合规的前提下,在多参与方或多计算结点之间开展高效率的机器学习。其中,联邦学习可使用的机器学习算法不局限于神经网络,还包括随机森林等重要算法。联邦学习有望成为下一代人工智能协同算法和协作网络的基础。
联邦学习的系统构架
以包含两个数据拥有方(即企业 A 和 B)的场景为例介绍联邦学习的系统构架。该构架可扩展至包含多个数据拥有方的场景。假设企业 A 和 B 想联合训练一个机器学习模型,它们的业务系统分别拥有各自用户的相关数据。此外,企业 B 还拥有模型需要预测的标签数据。出于数据隐私保护和安全考虑,A 和 B 无法直接进行数据交换,可使用联邦学习系统建立模型。联邦学习系统构架由三部分构成,如图所示。
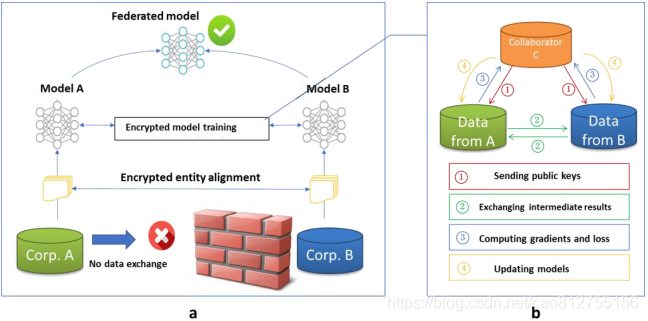
第一部分:加密样本对齐。由于两家企业的用户群体并非完全重合,系统利用基于加密的用户样本对齐技术,在 A 和 B 不公开各自数据的前提下确认双方的共有用户,并且不暴露不互相重叠的用户,以便联合这些用户的特征进行建模。第二部分:加密模型训练。在确定共有用户群体后,就可以利用这些数据训练机器学习模型。为了保证训练过程中数据的保密性,需要借助第三方协作者 C 进行加密训练。以线性回归模型为例,训练过程可分为以下 4 步(如图 所示):
第①步:协作者 C 把公钥分发给 A 和 B,用以对训练过程中需要交换的数据进行加密。
第②步:A 和 B 之间以加密形式交互用于计算梯度的中间结果。
第③步:A 和 B 分别基于加密的梯度值进行计算,同时 B 根据其标签数据计算损失,并把结果汇总给 C。C 通过汇总结果计算总梯度值并将其解密。
第④步:C 将解密后的梯度分别回传给 A 和 B,A 和 B 根据梯度更新各自模型的参数。
迭代上述步骤直至损失函数收敛,这样就完成了整个训练过程。在样本对齐及模型训练过程中,A 和 B 各自的数据均保留在本地,且训练中的数据交互也不会导致数据隐私泄露。因此,双方在联邦学习的帮助下得以实现合作训练模型。
第三部分:效果激励。联邦学习的一大特点就是它解决了为什么不同机构要加入联邦共同建模的问题,即建立模型以后模型的效果会在实际应用中表现出来,并记录在永久数据记录机制(如区块链)上。提供数据多的机构所获得的模型效果会更好,模型效果取决于数据提供方对自己和他人的贡献。这些模型的效果在联邦机制上会分发给各个机构反馈,并继续激励更多机构加入这一数据联邦。以上三部分的实施,既考虑了在多个机构间共同建模的隐私保护和效果,又考虑了以一个共识机制奖励贡献数据多的机构。所以,联邦学习是一个「闭环」的学习机制。
联邦学习优势
(1)数据隔离,数据不会泄露到外部,满足用户隐私保护和数据安全的需求;
(2)能够保证模型质量无损,不会出现负迁移,保证联邦模型比割裂的独立模型效果好;
(3)参与者地位对等,能够实现公平合作;
(4)能够保证参与各方在保持独立性的情况下,进行信息与模型参数的加密交换,并同时获得成长。
联邦学习分类
针对不同数据集,联邦学习分为横向联邦学习(horizontal federated learning)、纵向联邦学习(vertical federated learning)与联邦迁移学习(Federated Transfer Learning,FmL)。

横向联邦学习在两个数据集的用户特征重叠较多,而用户重叠较少的情况下,我们把数据集按照横向(即用户维度)切分,并取出双方用户特征相同而用户不完全相同的那部分数据进行训练。这种方法叫做横向联邦学习。比如有两家不同地区的银行,它们的用户群体分别来自各自所在的地区,相互的交集很小。但是,它们的业务很相似,因此,记录的用户特征是相同的。此时,我们就可以使用横向联邦学习来构建联合模型。谷歌在2016年提出了一个针对安卓手机模型更新的数据联合建模方案:在单个用户使用安卓手机时,不断在本地更新模型参数并将参数上传到安卓云上,从而使特征维度相同的各数据拥有方建立联合模型。
纵向联邦学习在两个数据集的用户重叠较多而用户特征重叠较少的情况下,我们把数据集按照纵向(即特征维度)切分,并取出双方用户相同而用户特征不完全相同的那部分数据进行训练。这种方法叫做纵向联邦学习。比如有两个不同的机构,家是某地的银行,另一家是同一个地方的电商。它们的用户群体很有可能包含该地的大部分居民因此用户的交集较大。但是,由于银行记录的都是用户的收支行为与信用评级,而电商则保有用户的浏览与购买历史,因此它们的用户特征交集较小。纵向联邦学习就是将这些不同特征在加密的状态下加以聚合,以增强模型能力。目前,逻辑回归模型、树形结构模型和神经网络模型等众多机器学习模型已经逐渐被证实能够建立在此联邦体系上。
联邦迁移学习在两个数据集的用户与用户特征重叠都较少的情况下,我们不对数据进行切分,而利用迁移学习国来克服数据或标签不足的情况。这种方法叫做联邦迁移学习。比如有两个不同机构,一家是位于中国的银行,另一家是位于美国的电商。由于受地域限制,这两家机构的用户群体交集很小。同时,由于机构类型的不同,二者的数据特征也只有小部分重合。在这种情况下,要想进行有效的联邦学习,就必须引入迁移学习,来解决单边数据规模小和标签样本少的问题,从而提升模型的效果。
联邦学习源码
1.https://www.tensorflow.org/federated/
2.https://github.com/WeBankFinTech/FATE