From:https://my.oschina.net/simpleton/blog/525675
一、什么是ETL
ETL,是英文 Extract-Transform-Load 的缩写,用来描述将数据从来源端经过抽取(extract)、转换(transform)、加载(load)至目的端的过程。ETL一词较常用在数据仓库,但其对象并不限于数据仓库。
二、Kettle简单说明
Kettle是一款国外开源的ETL工具,纯java编写,可以在Window、Linux、Unix上运行,数据抽取高效稳定。
三、需求
1、 Mysql 5.X数据迁移到 DB2 8.X
2、 主键自增改成32位UUID
三、准备工作
1、 源数据库:Mysql 5.6
2、 目标数据库:DB2 8.X
3、 数据迁移工具:Kettle6.0.0.0-353
四、实战开始
1、说明一下省略掉的步骤
在开始使用Kettle前,我使用了PowerDesigner18.6建立数据模型,然后导出对应数据库的建表脚本,这里我导出了DB2 8.X的建表脚本,然后首先在DB2中将目标表建立好。其实在Kettle中也可以在执行过程中来建立表,我也是初学Kettle,所以选择了一种相对简单的方式来操作,毕竟关注重点在于数据迁移这方面上。
2、安装JDK
因为Kettle是纯JAVA写的,所以依赖JDK,至于JDK的安装不是本文的重点,请读者自行百度完成。
3、 安装Kettle
下载pdi-ce-6.0.0.0-353.zip,我已经上传至百度云,下载地址:http://pan.baidu.com/s/1jGjMoXw
Kettle是绿色免安装的,将下载的压缩文件解压,找到程序启动文件Spoon.bat(Linux的Spoon.sh),双击则可以启动。不过在这一步操作之前,还有重要的一步需要做,就是拷贝我们的数据库驱动JAR包到指定目录。我是windows 7 x64,所以我将mysql和DB2对应的驱动包拷贝到了data-integrationlibswtwin64目录下,因为拷贝进去之后,需要重启程序才能生效,所以建议解压后,首先拷贝驱动JAR包到指定目录。

然后点击Spoon.bat,启动应用程序。

程序启动完成后,进入到欢迎页面,在页面左边有一棵树,在“主对象数”下分别是“转换”和“作业”两个功能节点,另外还有“核心对象”菜单,这个是用得比较多的,稍后会谈到。
至此,Kettle的安装已经完成,下面就进入到实战的重要环节了。
3、开始使用Kettle做数据迁移
这里我不讲太多理论知识,毕竟我对Kettle也是初探,所以本文重点还是放在如何操作Kettle完成一次数据迁移。
第一步:建立转换(Transformation)
双击Spoon.bat启动Kettle,点击界面左上角的“文件” – “新建” – “转换”,并保存为demo.ktr。

第二步:添加“表输入”
在左侧的“核心对象”下面找到“输入 – 表输入”,将其拖入到右侧编辑区域中。

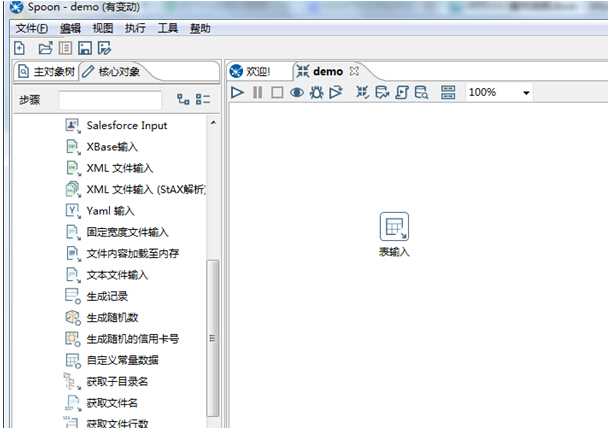
第三步:编辑“表输入”
双击编辑区域的“表输入”,进入编辑界面。
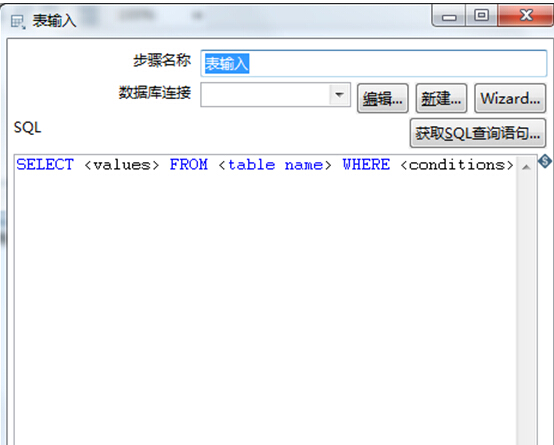
在弹出窗口中,可以编辑信息,点击“新建”

在弹出窗口中录入源数据库(mysql)的服务器信息,点击测试按钮,测试连接是否成功。


注意:如果前面没有将数据库的JAR包拷贝到指定文件目录下,这里会抛出异常说找不到驱动程序。只需要拷贝JAR包到指定文件(根据系统不同而有所不同,请看Kettle的安装部分),然后重启程序,就可以解决该问题。
测试连接成功,点击“确定”,然后在“数据库链接”处选择我们新建的连接。

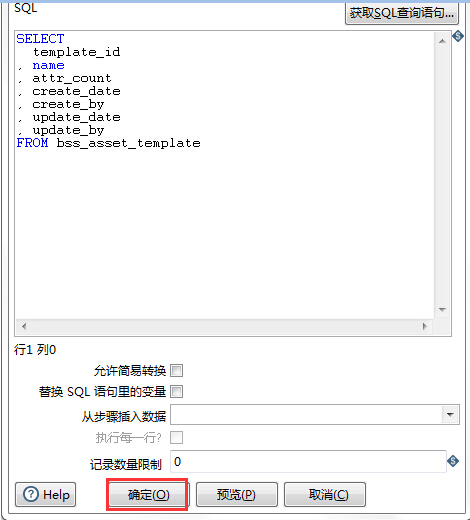
点击“获取SQL查询语句”

在弹出窗口中选择要迁移的数据表,每次只能操作一个表
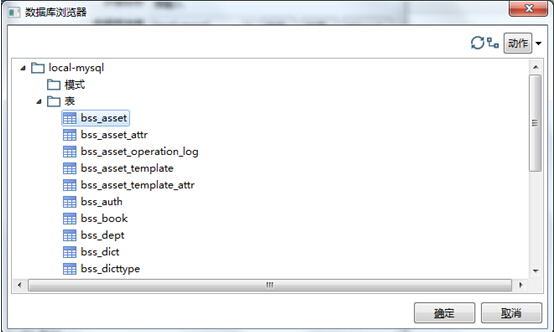
选择“是”

点击“确定”,源数据则配置好了。
第四步:添加和编辑 “字段选择”(可选)
如果你的数据类型在迁移过程中会发生变化,那么需要添加“字段选择”步骤。比如我在迁移过程中,需要将自增的整形字段改成32位的UUID,至于为什么会出现这样的需求,是因为我在迁移过程中发现如果在目标数据库中设置主键自增,那么数据迁移的过程中,无法插入主键,只能由数据库去操作自增,这样的话,会导致我原来的关联数据无法完成迁移。从这次的教训中得到经验,以后数据库主键设计时,会发生主外键关联的,尽量设计成UUID。
在“核心对象 – 转换”下找到“字段选择”,将其拖入到右侧编辑区域。

按住“shift”,然后从“表输入”到“字段选择”,拖一条线
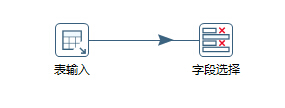
双击“字段选择”,进入编辑界面
选择“元数据”

点击“获取改变的字段”

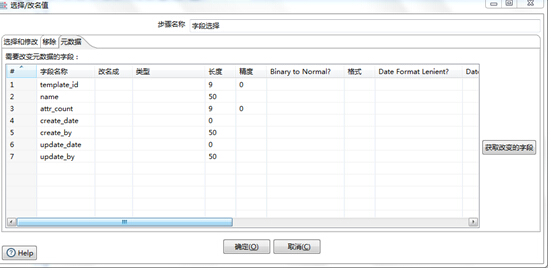
在这个地方,你可以修改源数据表字段,用以匹配目标数据表。我在这里需要将原来的主外键都改成32位的UUID,因为我已经事先在目标数据表(DB2)定义了主外键为VARCHAR(32),所以这里我需要修改源数据表的主外键为String,长度不用管。
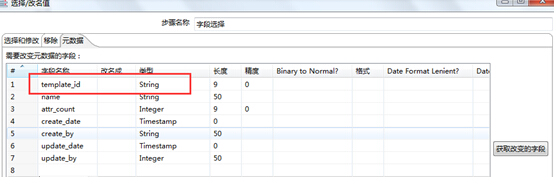
点击确定
第五步:添加“表输出”
在“核心对象 – 输出”下面选择“表输出”,拖到右侧编辑区域


按住“shift”从“字段选择”往“表输出”拖一个箭头,并选择“主输出步骤”(拖线过程中,鼠标点击“表输出”的时候会出现该选项)。
双击“表输出”,选择“新建”

和前面类似,在弹出窗口中输入数据库的地址信息,点击测试
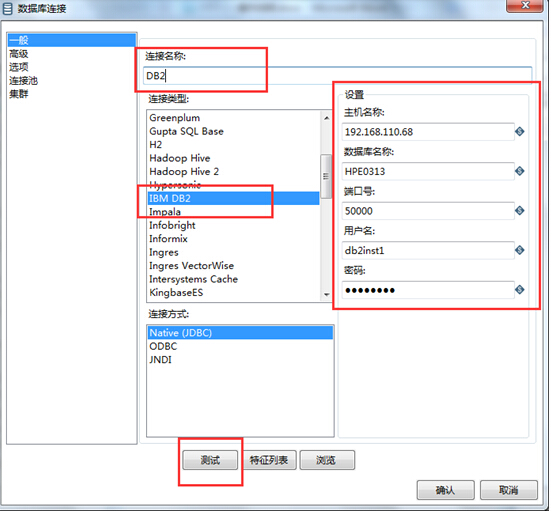

测试连接成功,点击确定,在“数据库链接”处选择新建的DB2的目标数据库连接
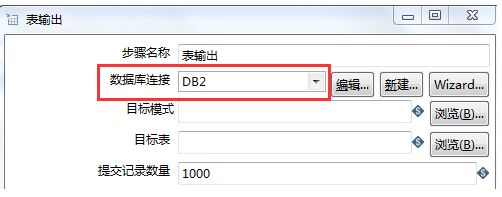
选择“目标模式”(这里我不太懂,总之DB2的话,出现的是schema),然后选择“目标表”,点击确定

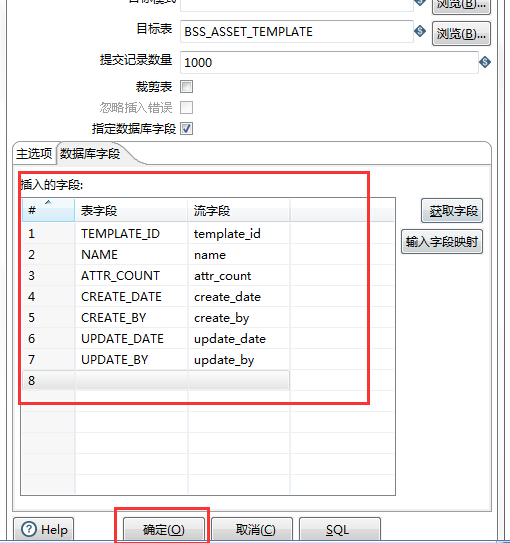
勾选“指定数据库字段”,然后点击“输入字段映射”

在弹出窗口中,选择源数据表字段和目标数据表字段的匹配方式,点击“猜一猜”可以一键分配,但是它的分配规则我不了解,可能根据名字的相似度吧,如果名字相同或者相似,可以使用,很方便。


点击确定。
第六步:“校验这个转换”
点击“校验这个转换”,可以校验刚才我们定义的这个转换是否有问题。

如果没有问题,则表示我们定义的这个转换可以执行
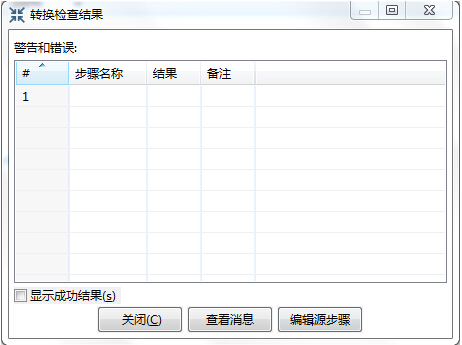
第七步:“运行这个转换”

点击“运行这个转换”,则开始执行数据迁移了,可以在窗口下面看到执行日志,如果没有错误,那么表示我们完成了一个表的数据迁移工作。
批量操作
如果还有更多的表,可以在这一个转换中定义多个上图所示的“表输入”-“字段选择”-“表输出”步骤,一次批量执行。但是这样的执行是不保证执行顺序的,如果有主外键关联的话,这样批量执行会出问题。所以可以将有主外键关联的表的数据迁移工作做成多个“转换”,然后通过作业将他们串起来,这样就能够保证执行顺序了,至于作业的建立,本文不再累述,以后有时间再开一篇文章单独写,读者也可以自己找资料看看,简单的操作的话,一看就会了。
大概的作业我用图展示一下,详细的我就不写了。
