项目地址:
https://github.com/HttpRunner/HttpRunner
中文手册:
http://cn.httprunner.org/
首先是环境搭建:
pip install httprunner
或者
pip3 install httprunner
安装完成后cmd执行以下命令,有返回则成功:
hrun -V
>>>0.9.7
har2case -V
>>>0.1.4
测试准备
抓包分析
在开始测试之前,我们需要先了解接口的请求和响应细节,而最佳的方式就是采用 Charles Proxy 或者 Fiddler 这类网络抓包工具进行抓包分析(我个人强推Charles)。
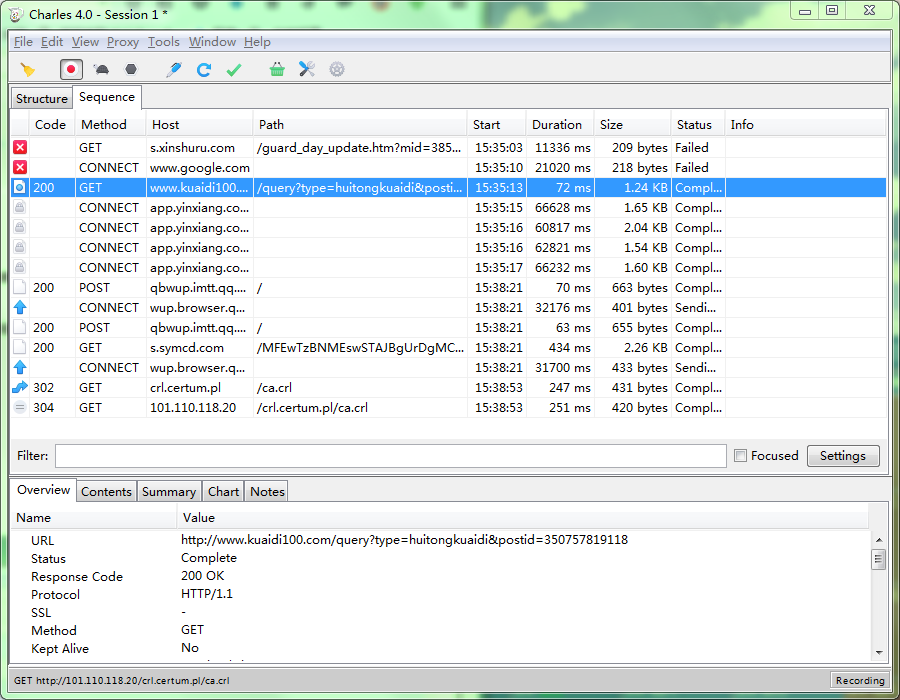
我们以某快递查询接口为例,在本案例中,我们先进行权限校验,然后成功创建一个用户,对应的网络抓包内容如下图所示:
接口和参数:
http://www.kuaidi100.com/query?type=huitongkuaidi&postid=350757819118
响应参数如下:
{"message":"ok","nu":"350757819118","ischeck":"1","condition":"F00","com":"huitongkuaidi","status":"200","state":"3","data":[{"time":"2017-12-21 15:42:29","ftime":"2017-12-21 15:42:29","context":"广州市|广州市【广州新永和站】,周祥代 已签收","location":""},{"time":"2017-12-21 14:28:59","ftime":"2017-12-21 14:28:59","context":"广州市|广州市【广州新永和站】,【周海祥/18925068779】正在派件","location":""},{"time":"2017-12-21 14:27:59","ftime":"2017-12-21 14:27:59","context":"广州市|到广州市【广州新永和站】","location":""},{"time":"2017-12-20 23:43:30","ftime":"2017-12-20 23:43:30","context":"广州市|广州市【广州黄埔转运中心】,正发往【广州新永和站】","location":""},{"time":"2017-12-20 20:40:15","ftime":"2017-12-20 20:40:15","context":"广州市|到广州市【广州黄埔转运中心】","location":""},{"time":"2017-12-20 16:18:35","ftime":"2017-12-20 16:18:35","context":"广州市|广州市【广州转运中心】,正发往【广州黄埔转运中心】","location":""},{"time":"2017-12-20 08:27:05","ftime":"2017-12-20 08:27:05","context":"广州市|到广州市【广州转运中心】","location":""},{"time":"2017-12-19 03:21:02","ftime":"2017-12-19 03:21:02","context":"西安市|西安市【西安转运中心】,正发往【广州转运中心】","location":""},{"time":"2017-12-18 22:52:37","ftime":"2017-12-18 22:52:37","context":"西安市|到西安市【西安转运中心】","location":""},{"time":"2017-12-18 22:43:29","ftime":"2017-12-18 22:43:29","context":"西安市|到西安市【西安南郊二站集货点】","location":""},{"time":"2017-12-17 21:29:25","ftime":"2017-12-17 21:29:25","context":"西安市|西安市【西安西郊五站】,【赵永刚/02962255063】已揽收","location":""}]}
然后右键导出,选择har格式。
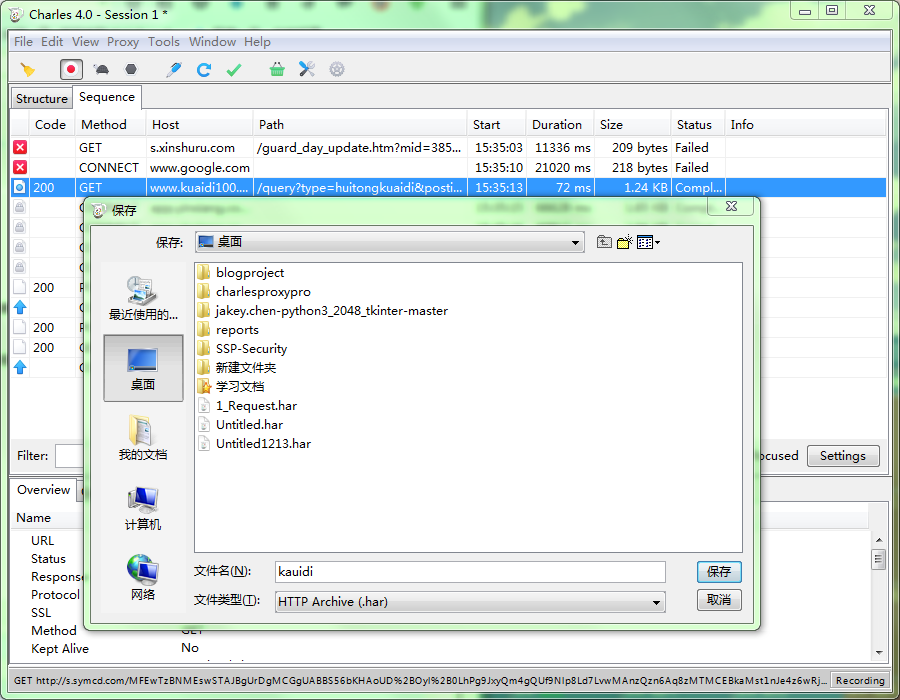
将har文件进行转换,cmd命令:
>>> har2case kauidi.har kuaidi.json
这样就可以把har格式的转换为json格式的用例
分割线---------------------------------------------------------------------------------------------------
接下来重点是讲用例,也就是json的组成部分。
生成的.json文件内容如下:
[
{
"config": {
"name": "testset description",
"variables": [],
"headers": {
"User-Agent": "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/61.0.3163.100
Safari/537.36"
}
}
},
{
"test": {
"name": "/query",
"request": {
"params": {
"type": "huitongkuaidi",
"postid": "350757819118"
},
"url": "http://www.kuaidi100.com/query",
"method": "GET"
},
"validate": [
{
"eq": [
"status_code",
200
]
},
{
"eq": [
"headers.Content-Type",
"text/html;charset=UTF-8"
]
},
{
]
}
]
}
}
]
测试用例的格式如下:

config作为整个测试用例集的全局配置项
test:对应单个测试用例。
我从以下4个方面介绍Httprunner的优势:
第一,断言。
断言参数存放在上述代码的这个部分,因为这是自动生成的,因此我们需要根据参数的返回值自己加进去一些数据。

根据响应参数,我们加进去返回结果

执行一下,发现通过

修改断言为其他,则执行失败。
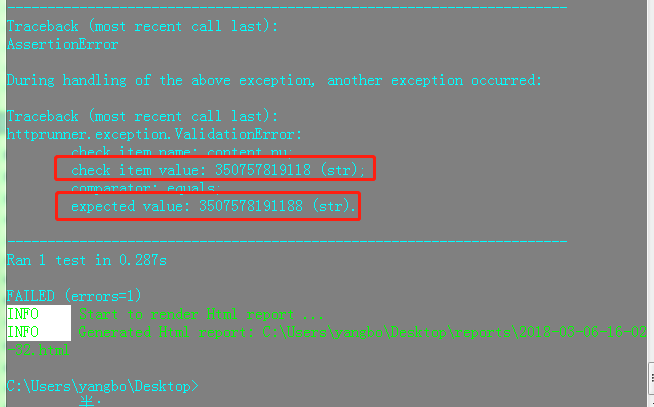
断言可靠,易于维护。
第二,缓存参数。
我们想获取,第一个参数的postid缓存,通过下面的方法:

当需要引用的时候,直接使用
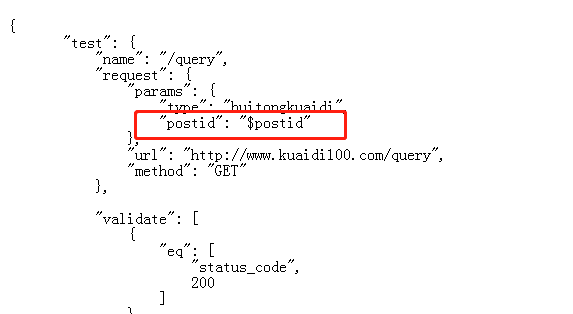
这样就在test2中使用了,test1中的缓存参数。
执行两条用例都成功:

第三个:数据驱动
同样,以快递号,postid为例,假设我们要测试,从350757819118~~350757819200区间的所有快递号码。我们只需要讲数据写入csv文件,并创建参数和.csv文件的关联。
例如:
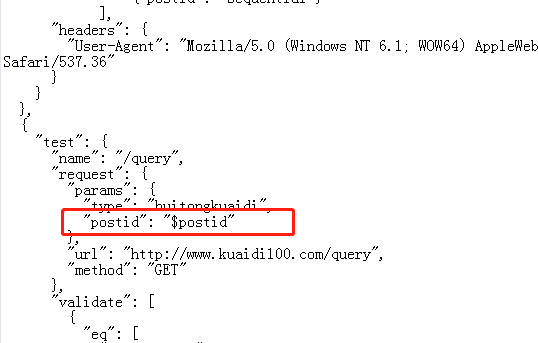
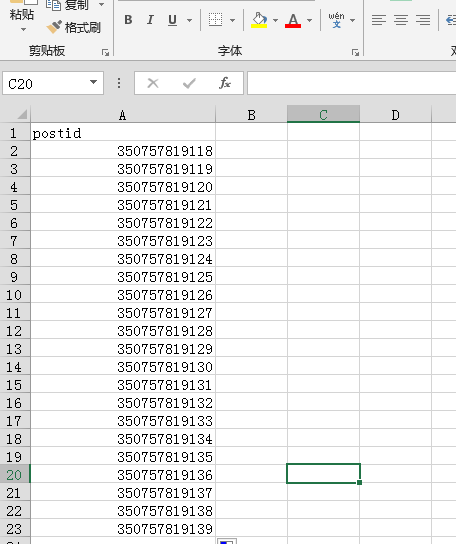
执行用例:
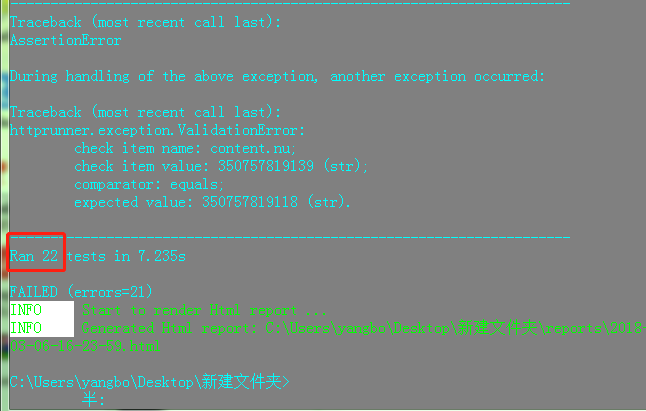
总共执行了22条,通过一条用例(是因为预期结果的原因,同理我们也可以将所有预期结果放入csv文件,进行关联。从而减少代码量)。设置的数据均被执行。
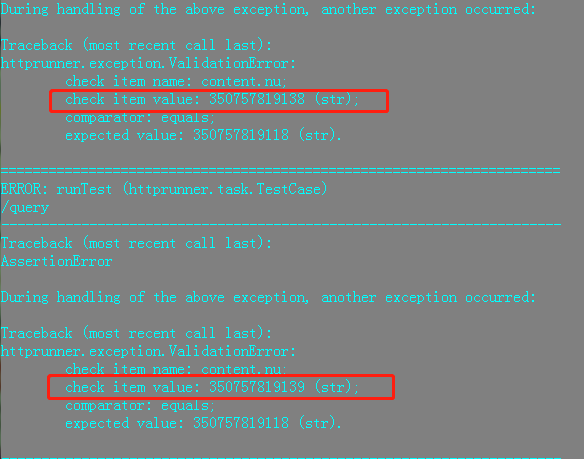
最后就是测试报告:
每次执行的测试报告以html的格式保存,
内容如下:
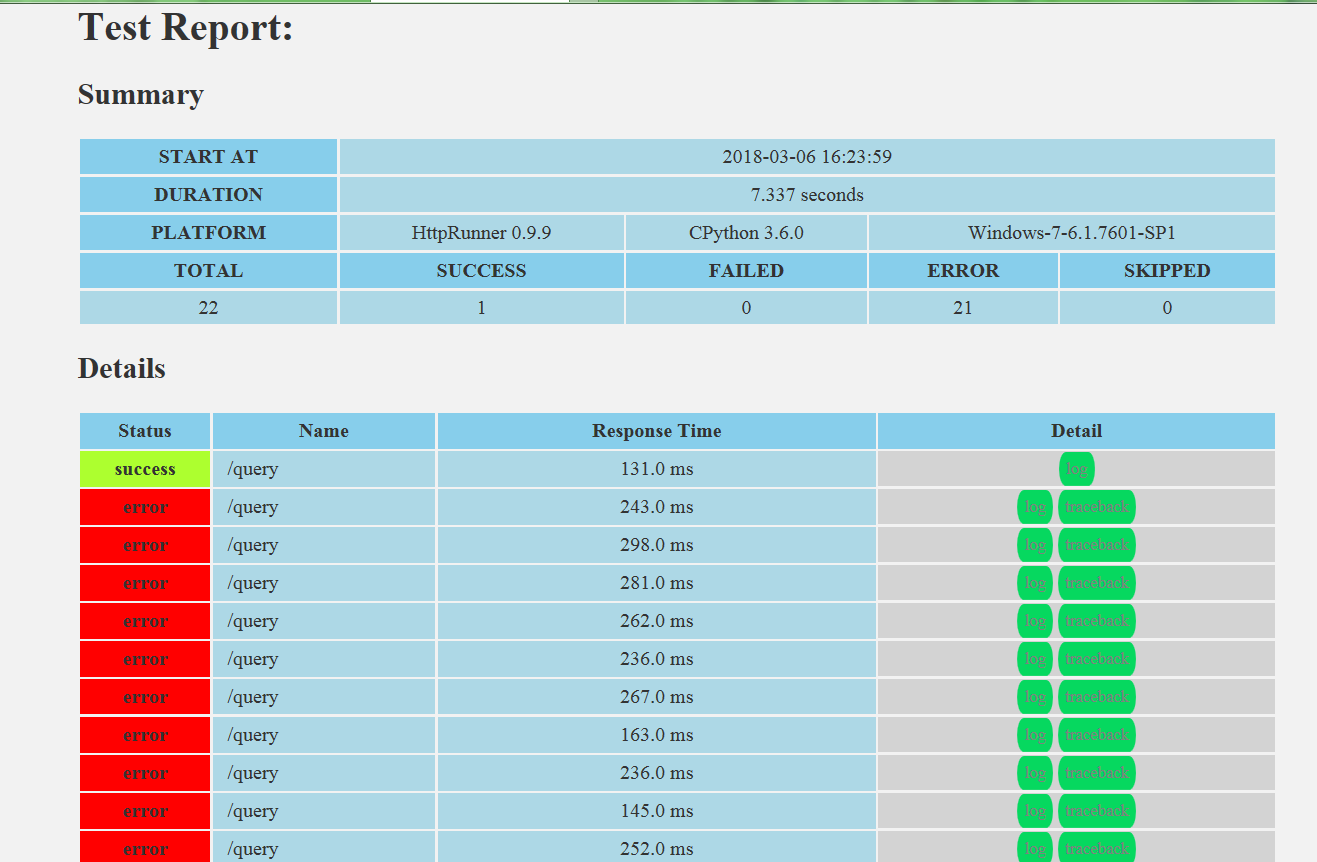
包括详细错误日志:

总结:
因为后台做了大量工作,因此我们只需要维护少量的json数据,工作量减少,效率提高。
灵活性:可根据自己需要,定义合适的方法或者数据缓存机制。
httprunner也提供了基于locust的性能测试,可根据需要直接运行json文件即可!
同时,最重要的是,测试用例和代码的分离。这样使得稍有编码功底的人迅速上手。
接口用例可通过har文件录制转换得到,也可自己定义。
顺便提一下
如果有任何问题,你可以在这里找到我 ,软件测试交流qq群,209092584