1.Github项目地址##
2.PSP表格##
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) | |||||||||
| Planning | 计划 | 30 | 30 | |||||||||
| ·Estimate | ·估计这个任务需要多少时间 | 30 | 30 | |||||||||
| Development | 开发 | 420 | 450 | |||||||||
| ·Analysis | ·需求分析 (包括学习新技术) | 50 | 60 | |||||||||
| ·Design Spec | ·生成设计文档 | 50 | 60 | |||||||||
| ·Design Review | ·设计复审 | 0 | 0 | |||||||||
| ·Coding Standard | ·代码规范 (为目前的开发制定合适的规范) | 80 | 60 | |||||||||
| ·Design | ·具体设计 | 100 | 90 | |||||||||
| ·Coding | ·具体编码 | 100 | 100 | |||||||||
| ·Code Review | ·代码复审 | 20 | 40 | |||||||||
| ·Test | ·测试(自我测试,修改代码,提交修改 | 20 | 40 | |||||||||
| Reporting | 报告 | 150 | 180 | |||||||||
| ·Test Repor | ·测试报告 | 50 | 70 | |||||||||
| ·Size Measurement | ·计算工作量 | 50 | 60 | |||||||||
| ·Postmortem & Process Improvement Plan | ·事后总结, 并提出过程改进计划 | 50 | 50 | |||||||||
| 合计 | 600 | 630 |
3.解题思路描述(模块接口设计如下)##
1.由题目所要求,可将需求分类:
宏观方面来说:
(1)统计字符数。使用fgetc函数读取每一个字符,即遍历一遍文件,判断Ascii值是否在32~126之间,若是,则计数,由此统计字符数。
(2)统计有效行数。统计行数,实则统计换行符的个数。若最后一个字符表示换行符,则额外再加一。
(3)统计文件的单词总数。
1.首先设置一个数组,用于存储寻找到的有效单词,以字符串形式存入。
2.设置一个flag标志用于判断,由文件的第一个字符或某个分隔符为始,若检测到单词,则flag加一,直至flag=4时即可知寻到一个单词,继续遍历文件,直至遇到分隔符停止,将寻到单词存入数组。
3.若是还未遇到连续的四个单词,就遇到数字,则该字符串不可为单词,记为mark=1,继续遍历文件直至遇见分隔符,即可开始下一个单词寻找。
4.若是还未遇到连续的四个单词,若遇到的是分隔符,则mark=0,可直接进下一个单词寻找。
5.对于存储字符串的新数组,若字符串无效,则清空该数组,直到他为一个合法的单词。
(4)统计文件中各单词的出现次数,最终只输出频率最高的10个。可使用堆排序,设置一个新数组,将按序包含所有单词在哈希表中的下标存入数组。按单词在哈希表的下标进行排序,直至排完十个即可停止。
微观方面来说:
(1)遍历文件夹及其子文件。可以用递归方式遍历文件夹,从而获取当前文件夹里所有文件的路径。
(2)查询覆盖率。将有效单词插入哈希表,通过单词首字母确定52个元素,按顺序1~52构造哈希地址,用常数52定址解决冲突,若遇到等价的单词则判断字典顺序决定是否覆盖,若没有则新占一个槽。此处有参考百度。
4.设计实现过程##
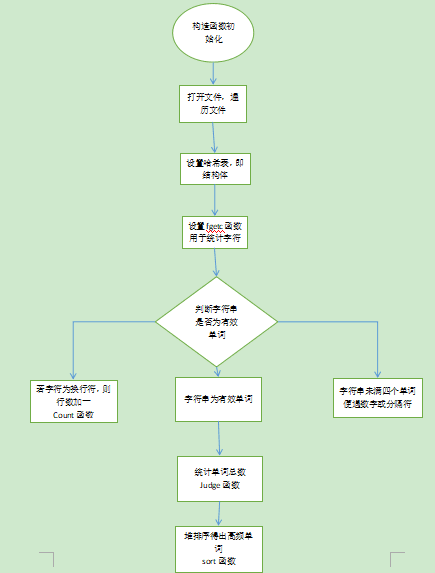
一.函数介绍及流程图
(1)设置哈希表,即一个结构体。
(2)首先设置一个fgetc函数用于统计字符数。
(3)然后,设计一个count函数用于统计换行符个数。
(4)设计一个judge函数,用于统计单词总数。
(5)最后设置一个sort函数利用堆排序进行统计高频单词。
二.单元测试设计
可分为以下几类:
1.测试空文件
2.测试只有一个单词的文件
3.测试只有一行的文件
4.测试多行文件(有多个不同的文件,用于测试。)
代码说明##
1.结构体(哈希表)
struct Word
{
char s[301];
int n;
}word[16777216];
struct Column
{
char s1[301];
char s2[301];
};
2.函数介绍
void readDataFunction() //读文件
int JudgeOrder(char a[], char b[]); //判断字典顺序
void DictOrder(void); //字典排序
void Count_Characters_Lines(void); //统计字符数和行数
void CountWords(void); //统计单词总数
int Judge_Words Equal(char a[], char b[]); //判断两个单词是否等价
void Count_Words Fre(void); //统计各单词频率及排序
3.读取文件
void readDataFunction()
{
ifstream readData;
readData.open("data.txt");
readData>>PartitionNum;
for (int i=0;i<PartitionNum;i++)
{
readData>>FreePartition[i];
}
readData>>ProcessNum;
for (int i=0;i<ProcessNum;i++)
{
readData>>ProcessName[i];
}
for (int i=0;i<ProcessNum;i++)
{ readData>>ProcessNeed[i];
}
}
4.判断字典顺序
int JudgeOrder(char a[], char b[])
{
int i;
for (i = 0; a[i] && b[i]; i++)
{
if (a[i] ==b[i])
return 0;
else if ((a[i] < b[i])) return -1;
else return 1;
}
if (a[i]! = NULL && b[i] == NULL)
return 1;
else if (a[i] = =NULL && b[i]! = NULL)
return -1;
else return 0;
}
5.统计字符数和行数
void Count_Characters_Lines()
{
char cc;
while ((cc = fgetc(fin)) != EOF)
{
if (cc >= 0 && ch <= 127)
characters++;
if (cc == '
')
lines++;
}
fprintf(fout, "characters: %d
lines: %d
", characters, lines);
}
6.统计单词总数
void CountWords()
{
char cc;
int flag = 4, mark = 1;
while ((cc = fgetc(fin)) != EOF)
{
if (flag>0 && mark == 1 && ((cc >= 'A' && cc <= 'Z') || (cc >= 'a' && cc <= 'z')))
{
flag--;
continue;
}
if (flag == 0 && !(cc >= 'A' && cc <= 'Z') && !(cc >= 'a' && cc <= 'z') && !(cc >= '0' && cc <= '9'))
{
flag = 4;
mark = 1;
words++;
continue;
}
if (flag>0 && flag<4 && !(cc >= 'A' && cc <= 'Z') && !(cc >= 'a' && cc <= 'z'))
{
flag = 4;
if (cc >= '0' && cc <= '9')
mark = 0;
continue;
}
if (flag == 4 && mark == 0 && !(cc >= 'A' && cc <= 'Z') && !(cc >= 'a' && cc <= 'z') && !(cc >= '0' && cc <= '9'))
mark = 1;
}
if (flag == 0) words++;
fprintf(fout, "words: %d
", words);
}
7.统计各单词频率及排序
void CountWordsFre()
{
;
int i = 0, j = 0, flag = 4, mark = 1, m = 1;
char cc, b[200];
while ((cc = fgetc(fin)) != EOF)
{
if (flag>0 && mark == 1 && ((cc >= 'A' && cc <= 'Z') || (cc >= 'a' && cc <= 'z')))
{
b[i] = cc; i++;
flag--;
continue;
}
if (flag == 0 && !(cc >= 'A' && cc <= 'Z') && !(cc >= 'a' && cc <= 'z') && !(cc >= '0' && cc <= '9'))
{
flag = 4;
words++;
mark = 1;
b[i] = '�'; i = 0; m = 0;
for (j = 0; j < k; j++)
{
if (Judge_ordEqual(b, word[j].c) == 1) { m = 1; break; }
}
if (m) word[j].n++;
else {
word[k].n = 1; strcpy(word[k].c, b); k++;
}
continue;
}
if (flag == 0) { b[i] = cc; i++; continue; }
if (flag>0 && flag<4 && !(cc >= 'A' && cc <= 'Z') && !(cc >= 'a' && cc <= 'z'))
{
flag = 4; i = 0; memset(b, '�', sizeof(b));
if (cc >= '0' && cc <= '9')
mark = 0;
continue;
}
if (flag == 4 && mark == 0 && !(cc >= 'A' && cc <= 'Z') && !(cc >= 'a' && cc <= 'z') && !(cc >= '0' && cc <= '9'))
mark = 1;
}
if (flag == 0)
{
words++;
b[i] = '�'; m = 0;
for (j = 0; j < k; j++)
{
if (Judge_WordEqual(b, word[j].c) == 1)
{ m = 1; break; }
}
if (m) word[j].n++;
else {
word[k].n = 1; strcpy(word[k].c, b); k++;
}
}
fprintf(fout, "words: %d
", words);
}
实验心得##
反思这一次作业,我发现自己的编程基础相当不扎实,写排序算法时还特意去查了一下插入排序怎么写,对类自带的各种函数也基本靠着查手册来做,菜的真实,需要多做多练多学。
写代码要细心,因为忘记写fclose函数导致文件指针越界,导致读了一些文件之后后面的文件就无法读取。
其次是在编程算法上需要锻炼,希望通过本学期的学习能够很好地提升自己的软件编程能力。