【统计PV与UV】
Redis提供了一组略有误差的统计指令,pfadd与pfcount,这两个指令配合使用,可以进行上亿数据的去重不精确统计,它的优势就是节省空间(12KB就能统计2^64个数据)。想想如果使用set进行过滤与存储会是多大的空间消耗。
另外,使用pfmerge可以将多个pf数值累加在一起。
【原理简述-参考https://www.jianshu.com/p/55defda6dcd2】
首先来了解LogLog的过程:
以抛硬币为例,正面为1反面为0,如何通过抛硬币的结果来大概猜测抛了多少次硬币呢?
比如11000110011110010101011001
那么这么一个序列,找到0连续出现最多次的片段即000,再把后续的1添上(这个有论文支持的),所以是0001,出现的概率为(1/2)^4即1/16,所以这里LogLog就预估抛了16次。
这个就是LogLog的基本思想,当然这个误差明显很大,而HyperLogLog就是在这个思想的基础上进行改进和优化,最终给出更为精确地估计。
第一步优化:分桶
LogLog对上述过程其实会有一个优化,就是先分再合:
将上述例子中的整个序列分成M个片段,而后对每个片段进行估计,最终再加和除以M,即得到一个平均值,这样一来可以把误差抵消一部分,总体上就会比整体一次估计要准确一些。
即M*每个桶的均值,而后会根据不同的场景增加一个修正常数,最终结果为
修正常数*M*每个桶均值
HyperLogLog(hll)的调和
HyperLogLog是利用输入值的hash进行计数估算的,但是hash值的前导零的数量显然是有很大的偶然性的,经常会出现一两数据前导零的数目比较多的情况。就像如果把一个很大的数字和一堆比较小的数字进行平均得到的值其实对于整体来讲是偏大的,也像比赛计分时都会有去掉一个最高分去掉一个最低分再取平均数也是基于这个考虑。HyperLogLog采用调和平均数,即每个元素的倒数进行整体求和,再将和取倒数,乘以元素的个数,最终的公式如下图: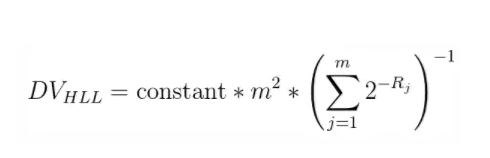
【为什么是12KB】
Redis中的HLL统一采用16384个桶,每个桶6bit,所以整个大小为16384*6/8即12KB