一、什么是elasticsearch
前言
观今宜鉴古,无古不成今。
在学习elasticsearch之前,我们要知道,elasticsearch是什么?为什么要学习elasticsearch?以及用它能干什么?
关于elasticsearch
现在,你还离得开搜索吗?无论是Google还是百度提供的搜索入口,还是项目自己的搜索,比如QQ提供的搜索入口等等,都大大的方便了我们的工作、生活。但是你有没有想过——搭建属于自己的搜索服务,应用于你的博客项目、公司项目……
无论你想不想,都要学习!因为随着公司业务的增长,数据也爆炸性增长。对于数据的处理、日志分析,如果还采用传统的方法,这恐怕是灾难性的。所以,我们是时候学习一个先进的搜索引擎了。
Elasticsearch是一个基于Apache Lucene(TM)的开源搜索引擎。无论在开源还是专有领域,Lucene可以被认为是迄今为止最先进、性能最好的、功能最全的搜索引擎库。
但是,Lucene只是一个库。想要使用它,你必须使用Java来作为开发语言并将其直接集成到你的应用中,更糟糕的是,Lucene非常复杂,你需要深入了解检索的相关知识来理解它是如何工作的。
Elasticsearch也使用Java开发并使用Lucene作为其核心来实现所有索引和搜索的功能,但是它的目的是通过简单的RESTful API来隐藏Lucene的复杂性,从而让全文搜索变得简单。
你以为这些就完了?elasticsearch除了Lucene和全文搜索,我们还可以描述它:
- 分布式的实时文件存储,每个字段都被索引并可被搜索
- 分布式的实时分析搜索引擎
- 可以扩展到上百台服务器,处理PB级结构化或非结构化数据。
并且,这些功能都被集成到一个服务里面,elasticsearch也提供的与其它语言的接口,其中包括:
- Java
- JavaScript
- Groovy
- .NET
- PHP
- Perl
- Python
- Ruby
- 以及社区贡献的更多接口
使用我们喜欢的语言通过RESTful API接口,访问9200端口,就可以与elasticsearch玩耍了。
上手elasticsearch非常容易,它提供了许多合理的缺省值,并对初学者隐藏了复杂的搜索引擎理论。它开箱即用(安装即可使用),只需很少的学习既可在生产环境中使用。
随着越学越深入,还可以利用Elasticsearch更多高级的功能,整个引擎可以很灵活地进行配置。可以根据自身需求来定制属于自己的Elasticsearch。
elasticsearch的模糊历史
多年前,一个叫做Shay Banon的刚结婚不久的失业开发者,由于妻子要去伦敦学习厨师,他便跟着也去了。在他找工作的过程中,为了给妻子构建一个食谱的搜索引擎,他开始构建一个早期版本的Lucene。
直接基于Lucene工作会比较困难,所以Shay开始抽象Lucene代码以便Java程序员可以在应用中添加搜索功能。他发布了他的第一个开源项目,叫做“Compass”。
后来Shay找到一份工作,这份工作处在高性能和内存数据网格的分布式环境中,因此高性能的、实时的、分布式的搜索引擎也是理所当然需要的。然后他决定重写Compass库使其成为一个独立的服务叫做Elasticsearch。
第一个公开版本出现在2010年2月,在那之后Elasticsearch已经成为Github上最受欢迎的项目之一,代码贡献者超过300人。一家主营Elasticsearch的公司就此成立,他们一边提供商业支持一边开发新功能,不过Elasticsearch将永远开源且对所有人可用。
Shay的妻子依旧等待着她的食谱搜索……
elasticsearch:面向文档
我们知道,关系型数据库以记录和行的形式存储数据,但是在elasticsearch中,是以文档的形式存储数据。
但区别在于,文档要比数据表的行更加灵活。因为文档可以是多层次的,它(文档)鼓励你将属于一个逻辑实体的数据保存在同一个文档中,而不是散落在各个表的不同行中。这样查询效率很高,因为我们无需连接其他的表,我们学习关系型数据库时,一定知道连表查询(尤其是连接多张表)是多么的费时吧!
我们将在后续文章做更多的讲解。
没有成熟的案例?
之前有人说,elasticsearch的缺点之一是没有成熟的案例加持,那我们就来看看elasticsearch都有哪些成熟的案例:
- 维基百科使用Elasticsearch来进行全文搜做并高亮显示关键词,以及提供search-as-you-type、did-you-mean等搜索建议功能。
- 英国卫报使用Elasticsearch来处理访客日志,以便能将公众对不同文章的反应实时地反馈给各位编辑。
- StackOverflow将全文搜索与地理位置和相关信息进行结合,以提供more-like-this相关问题的展现。
- GitHub使用Elasticsearch来检索超过1300亿行代码,可以参考A Whole New Code Search
- 每天,Goldman Sachs使用它来处理5TB数据的索引,还有很多投行使用它来分析股票市场的变动。
- 苏宁在大数据平台使用es存储600TB数据,集群规模包括:搭建超过500+物理机,30万shards,80000index。参考
- 腾讯在日志实时分析中采用es,处理高并发100W/S,PE级数据。
- 更多参考
所以,elasticsearch可以灵活的应用于我们的项目中。
如何学好elasticsearch
除了万能的百度和Google 之外,我们还有一些其他的学习途径:
- elasticsearch官方文档:这个比较好点,可以多多参考
- elasticsearch博客:这个吧,看看就行
- elasticsearch社区:社区还是很好的
- elasticsearch视频:包括入门视频什么的
- elasticsearch实战:该书籍的质量还是不错的。
- elasticsearch权威指南:同样的,这个也不错。
最后,你一定很好奇,elasticsearch索引能处理多大的数据
一个很好地问题,不幸的是,单一索引的极限取决于存储索引的硬件、索引的设计、如何处理数据以及你为索引备份了多少副本。
通常来说,一个Lucene索引(也就是一个elasticsearch分片)不能处理多于21亿篇文档,或者多于2740亿的唯一词条。但达到这个极限之前,我们可能就没有足够的磁盘空间了!
当然,一个分片如何很大的话,读写性能将会变得非常差。
二、elasticsearch之Apache Lucene
前言
在介绍Lucene之前,我们来了解相关的历史。
有必要了解的Apache
Apache软件基金会(也就是Apache Software Foundation,简称为ASF)是专门为运作一个开源软件项目的Apache 的团体提供支持的非盈利性组织,这个开源软件的项目就是 Apache 项目。
最初,Apache基金会的开发爱好者开发并维护一个叫Apache的HTTP服务器。
后来,Apache服务器越来越火,就启动了更多的项目,比如PHP、Java Apache以及更多的子项目。比如Jakarta。
Jakarta
Jakarta是为了发展Java容器而启动的Java Apache的项目。后来随着Java的火爆而成为了囊括了众多基于Java语言开源软件子项目的项目。比如从这里孵化出了Tomcat、ant、Struts、Lucene。
Lucene
Lucene是Apache软件基金会4 jakarta项目的子项目。它是一个开源的全文检索引擎工具包。但它并不是一个完整的全文检索引擎,而是一个全文检索引擎的架构,提供了完整的查询引擎和索引引擎,部分文本分析引擎(英文与德文两种西方语言)。Lucene的目的是为软件开发人员提供一个简单易用的工具包,以方便的在目标系统中实现全文检索的功能,或者是以此为基础建立起完整的全文检索引擎。Lucene是一套用于全文检索和搜寻的开源程式库,由Apache软件基金会支持和提供。Lucene提供了一个简单却强大的应用程式接口,能够做全文索引和搜寻。在Java开发环境里Lucene是一个成熟的免费开源工具。
最后,引用来自《Elasticsearch权威指南》书中关于Lucene的描述作为总结:
Lucene可以被认为是迄今为止最先进、性能最好的、功能最全的搜索引擎库。
但是,Lucene只是一个库。想要使用它,你必须使用Java来作为开发语言并将其直接集成到你的应用中,更糟糕的是,Lucene非常复杂,你需要深入了解检索的相关知识来理解它是如何工作的。
常见的开源搜索引擎
基于Lucene的搜索引擎,Java开发,包括:
- Lucene
- Solr
- elasticsearch
- katta
- compass
基于C++开发的:
- Sphinx
你可以想想Lucene的强大。接下来简要的介绍各搜索引擎的特点。
Lucene
Lucene的开发语言是Java,也是Java家族中最为出名的一个开源搜索引擎,在Java世界中已经是标准的全文检索程序,它提供了完整的查询引擎和索引引擎,没有中文分词引擎,需要自己去实现,因此用Lucene去做一个搜素引擎需要自己去架构,另外它不支持实时搜索。
优点:
- 成熟的解决方案,有很多的成功案例。apache 顶级项目,正在持续快速的进步。庞大而活跃的开发社区,大量的开发人员。它只是一个类库,有足够的定制和优化空间:经过简单定制,就可以满足绝大部分常见的需求;经过优化,可以支持 10亿+ 量级的搜索
缺点:
- 需要额外的开发工作。所有的扩展,分布式,可靠性等都需要自己实现;非实时,从建索引到可以搜索中间有一个时间延迟,而当前的“近实时”(Lucene Near Real Time search)搜索方案的可扩展性有待进一步完善
Solr
Solr是一个企业级的高性能、采用Java开发,基于Lucene的全文搜索服务器。
文档通过Http利用XML加到一个搜索集合中。
查询该集合也是通过 http收到一个XML/JSON响应来实现。它的主要特性包括:高效、灵活的缓存功能,垂直搜索功能,高亮显示搜索结果,通过索引复制来提高可用性,提 供一套强大Data Schema来定义字段,类型和设置文本分析,提供基于Web的管理界面等。
优点:
- Solr有一个更大、更成熟的用户、开发和贡献者社区
- 支持添加多种格式的索引,如:HTML、PDF、微软 Office 系列软件格式以及 JSON、XML、CSV 等纯文本格式
- Solr比较成熟、稳定
- 不考虑建索引的同时进行搜索,速度更快
缺点:
- 建立索引时,搜索效率下降,实时索引搜索效率不高
Sphinx
Sphinx一个基于SQL的全文检索引擎,特别为一些脚本语言(PHP,Python,Perl,Ruby)设计搜索API接口。
Sphinx是一个用C++语言写的开源搜索引擎,也是现在比较主流的搜索引擎之一,在建立索引的时间方面比Lucene快50%,但是索引文件比Lucene要大一倍,因此Sphinx在索引的建立方面是空间换取时间的策略,在检索速度上,和lucene相差不大,但检索精准度方面Lucene要优于Sphinx,另外在加入中文分词引擎难度方面,Lucene要优于Sphinx.其中Sphinx支持实时搜索,使用起来比较简单方便.
Sphinx可以非常容易的与SQL数据库和脚本语言集成。当前系统内置MySQL和PostgreSQL 数据库数据源的支持,也支持从标准输入读取特定格式 的XML数据。通过修改源代码,用户可以自行增加新的数据源(例如:其他类型的DBMS 的原生支持)
Sphinx的特点:
- 高速的建立索引(在当代CPU上,峰值性能可达到10 MB/秒)
- 高性能的搜索(在2 – 4GB 的文本数据上,平均每次检索响应时间小于0.1秒)
- 可处理海量数据(目前已知可以处理超过100 GB的文本数据, 在单一CPU的系统上可 处理100 M 文档)
- 提供了优秀的相关度算法,基于短语相似度和统计(BM25)的复合Ranking方法
- 支持分布式搜索
- 支持短语搜索
- 提供文档摘要生成
- 可作为MySQL的存储引擎提供搜索服务
- 支持布尔、短语、词语相似度等多种检索模式
- 文档支持多个全文检索字段(最大不超过32个)
- 文档支持多个额外的属性信息(例如:分组信息,时间戳等)
- 支持断词
elasticsearch
ElasticSearch是一个基于Lucene的搜索服务器。它提供了一个分布式多用户能力的全文搜索引擎,基于RESTful web接口。Elasticsearch是用Java开发的,并作为Apache许可条款下的开放源码发布,是当前流行的企业级搜索引擎。设计用于云计算中,能够达到实时搜索,稳定,可靠,快速,安装使用方便。
优点:
- 分布式:节点对外表现对等,加入节点自动均衡
- elasticsearch完全支持Apache Lucene的接近实时的搜索
- 各节点组成对等的网络结构,当某个节点出现故障时会自动分配其他节点代替期进行工作
- 横向可扩展性,如果你需要增加一台服务器,只需要做点配置,然后启动就完事了
- 高可用:提供复制(replica)机制,一个分片可以设置多个复制,使得某台服务器宕机的情况下,集群仍旧可以照常运行,并会把由于服务器宕机丢失的复制恢复到其它可用节点上;这点也类似于HDFS的复制机制(HDFS中默认是3份复制)
缺点:
- 不支持事物
- 相对吃内存
三、elasticsearch的数据组织
前言
我们从之前的一堆铺垫中,也对elasticsearch有了基本了解。
为了理解elasticsearch是如何组织数据的,我们可以从以下两个方面来观察:
- 逻辑设计,我们可以把elasticsearch与关系型数据做个客观对比:
| Relational DB | Elasticsearch |
|---|---|
| 数据库(database) | 索引(indices) |
| 表(tables) | types |
| 行(rows) | documents |
| 字段(columns) | fields |
elasticsearch(集群)中可以包含多个索引(数据库),每个索引中可以包含多个类型(表),每个类型下又包含多个文档(行),每个文档中又包含多个字段(列)。
- 物理设计,在elasticsearch后台是如何处理这些数据的呢?elasticsearch将每个索引划分为多个分片,每份分片又可以在集群中的不同服务器间迁移。
注意:当然,这里需要补充的是,从elasticsearch的第一个版本开始,每个文档都存储在一个索引中,并分配多个映射类型,映射类型用于表示被索引的文档或者实体的类型,但这也带来了一些问题(详情参见Removal of mapping types),导致后来在elasticsearch6.0.0版本中一个文档只能包含一个映射类型,而在7.0.0中,映射类型则将被弃用,到了8.0.0中则将完全被删除。
我们先从逻辑设计开始,即从程序视角开始。
逻辑设计:文档、类型、索引
一个索引类型中,包含多个文档,比如说文档1,文档2。
当我们索引一篇文档时,可以通过这样的顺序找到它:索引?类型?文档ID,通过这个组合我们就能索引到某个具体的文档。
注意:ID不必是整数,实际上它是个字符串。
文档
之前说elasticsearch是面向文档的,那么就意味着索引和搜索数据的最小单位是文档,elasticsearch中,文档有几个重要属性:
- 自我包含,一篇文档同时包含字段和对应的值,也就是同时包含
key:value - 可以是层次型的,一个文档中包含自文档,复杂的逻辑实体就是这么来的
- 灵活的结构,文档不依赖预先定义的模式,我们知道关系型数据库中,要提前定义字段才能使用,在elasticsearch中,对于字段是非常灵活的,有时候,我们可以忽略该字段,或者动态的添加一个新的字段。
- 文档是无模式的,也就是说,字段对应值的类型可以是不限类型的。
尽管我们可以随意的新增或者忽略某个字段,但是,每个字段的类型非常重要,比如一个年龄字段类型,可以是字符串也可以是整型。因为elasticsearch会保存字段和类型之间的映射及其他的设置。这种映射具体到每个映射的每种类型(因此带来的问题),这也是为什么在elasticsearch中,类型有时候也称为映射类型。
类型
类型是文档的逻辑容器,就像关系型数据库一样,表格是行的容器。
类型中对于字段的定义称为映射,比如name映射为字符串类型。
我们说文档是无模式的,它们不需要拥有映射中所定义的所有字段,比如新增一个字段,那么elasticsearch是怎么做的呢?elasticsearch会自动的将新字段加入映射,但是这个字段的不确定它是什么类型,elasticsearch就开始猜,如果这个值是18,那么elasticsearch会认为它是整型。
但是elasticsearch也可能猜不对,所以最安全的方式就是提前定义好所需要的映射,这点跟关系型数据库殊途同归了,先定义好字段,然后再使用,别整什么幺蛾子。后面在讨论更多关于映射的东西。
索引
索引是映射类型的容器,elasticsearch中的索引是一个非常大的文档集合。索引存储了映射类型的字段和其他设置。然后它们被存储到了各个分片上了。
我们来研究下分片是如何工作的。
物理设计:节点和分片
一个集群包含至少一个节点,而一个节点就是一个elasticsearch进程。节点内可以有多个索引。
默认的,如果你创建一个索引,那么这个索引将会有5个分片(primary shard,又称主分片)构成,而每个分片又有一个副本(replica shard,又称复制分片),这样,就有了10个分片。
那么这个索引是如何存储在集群中的呢?
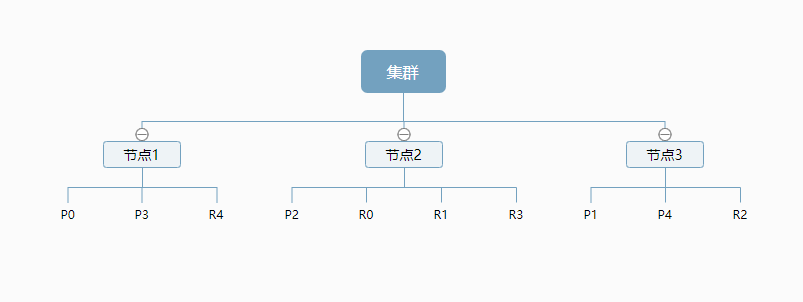
上图是一个有3个节点的集群,可以看到主分片和对应的复制分片都不会在同一个节点内,这样有利于某个节点挂掉了,数据也不至于丢失。
实际上,一个分片是一个Lucene索引,一个包含倒排索引的文件目录,倒排索引的结构使得elasticsearch在不扫描全部文档的情况下,就能告诉你哪些文档包含特定的关键字。
不过,等等,倒排索引是什么鬼?
倒排索引
elasticsearch使用的是一种称为倒排索引的结构,采用Lucene倒排索作为底层。这种结构适用于快速的全文搜索,一个索引由文档中所有不重复的列表构成,对于每一个词,都有一个包含它的文档列表。
倒排列表(Posting List)记录了词条对应的文档集合,由倒排索引项(Posting)组成。
倒排索引项主要包含如下信息:
- 文档id,用于获取原始信息。
- 词条频率(TF,Term Frequency),记录该词条在文档中出现的次数,用于后续相关性算分。
- 位置(Position),记录词条在文档中的分词位置(多个),用于做短语搜索(Phrase Query)。
- 偏移(Offset),记录词条在文档的开始和结束位置,用于做高亮显示。
以搜索引擎为例:
| 文档id | 文档内容 |
|---|---|
| 1 | elasticsearch是最流行的搜索引擎 |
| 2 | Python是世界上最好的语言 |
| 3 | 搜索引擎是如何诞生的 |
上述文档的倒排索引列表是这样的:
| DocID | TF | Position | Offset |
|---|---|---|---|
| 1 | 1 | 2 | <18,22> |
| 3 | 1 | 0 | <0,4> |
关于文档1,DocID是1无需多说,TF是1表示搜索引擎在文档内容中出现一次,Position指的是分词后的位置,首先要说文档内容会被分为elasticsearch、最流行、搜索引擎3部分,从0开始计算,搜索引擎的Position是2;Offset是搜索引擎这个字符在文档中的位置。
文档3中搜索引擎在文档中出现一次(TF:1),并且出现在文档的开始位置(Position:0),那么Offset的位置就是<0,4>无疑了。
再比如说,现在有两个文档, 每个文档包含如下内容:
Study every day, good good up to forever # 文档1包含的内容
To forever, study every day, good good up # 文档2包含的内容
为了创建倒排索引,我们首先要将每个文档拆分成独立的词(或称为词条或者tokens),然后创建一个包含所有不重复的词条的排序列表,然后列出每个词条出现在哪个文档:
| term | doc_1 | doc_2 |
|---|---|---|
| Study | √ | × |
| To | × | √ |
| every | √ | √ |
| forever | √ | √ |
| day | √ | √ |
| study | × | √ |
| good | √ | √ |
| every | √ | √ |
| to | √ | × |
| up | √ | √ |
现在,我们试图搜索to forever,只需要查看包含每个词条的文档:
| term | doc_1 | doc_2 |
|---|---|---|
| to | √ | × |
| forever | √ | √ |
| total | 2 | 1 |
两个文档都匹配,但是第一个文档比第二个匹配程度更高。如果没有别的条件,现在,这两个包含关键字的文档都将返回。
再来看一个示例,比如我们通过博客标签来搜索博客文章。那么倒排索引列表就是这样的一个结构:
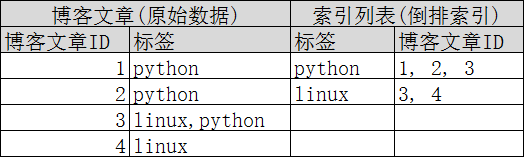
如果要搜索含有python标签的文章,那相对于查找所有原始数据而言,查找倒排索引后的数据将会快的多。只需要查看标签这一栏,然后获取相关的文章ID即可。
elasticsearch的索引和Lucene的索引对比
在elasticsearch中,索引这个词被频繁使用,这就是术语的使用。
并且elasticsearch将索引被分为多个分片,每份分片是一个Lucene的索引。所以一个elasticsearch索引是由多个Lucene索引组成的。别问为什么,谁让elasticsearch使用Lucene作为底层呢!
如无特指,说起索引都是指elasticsearch的索引。