这块比较乱待整理。。。
http://www.regexlab.com/zh/encoding.htm
字符编码
将各种文字、图形、标点、数字整合在一个集合叫做字符集。
把这些字符集按照不用规则进行编码就形成了不同的字符编码。
为什么我们在上网或软装软件后总会看到乱码?
?????
如:你用显微镜把盘片放大,会看见盘片表面凹凸不平,凸起的地方被磁化,凹的地方是没有被磁化;凸起的地方代表数字1,凹的地方代表数字0。硬盘只能用0和1 来表示所有文字、图片等信息。假设小张和小王使用了不同的编码表,小张计算机存储字母”A”转成二进制是1100001,而小王存储字母”A”转成二进制是11000010。这时小张把1100001发送给小王,小王并不认为1100001是字母”A”,可能认为这是字 母”X”,于是小王在用记事本访问存储在硬盘上的1100001时,在屏幕上显示的就是字母”X”。
字符编码分类
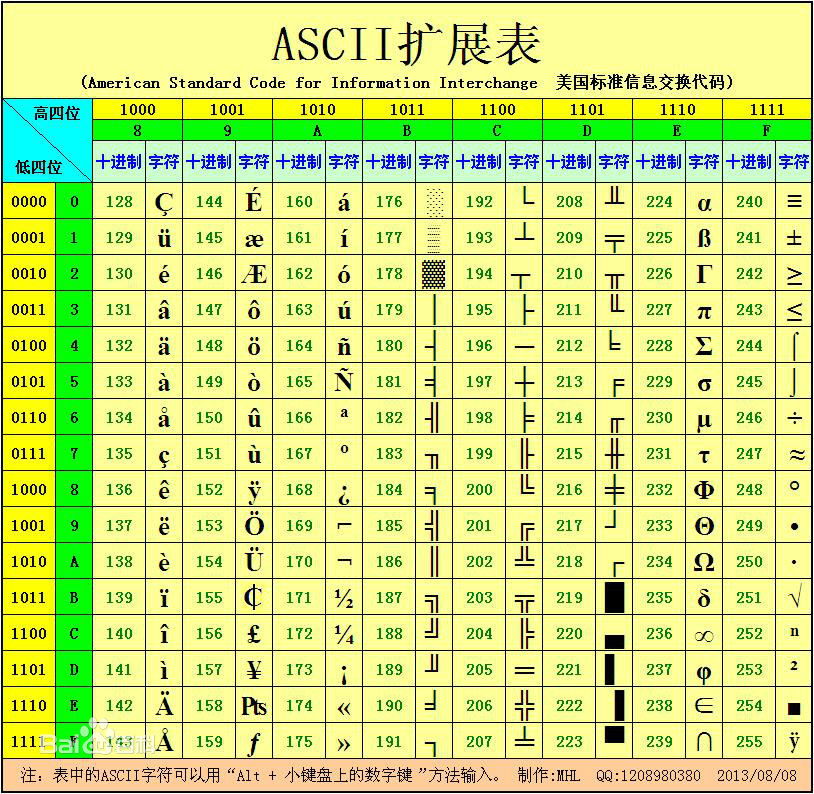
1、ASCII
ASCII全称是 American Standard Code for Information Interchange(美国信息互换标准代码)。
读作‘啊思客’,一直以为II是罗马数字,原来是Information Interchange的缩写。
标准ASCII 码也叫基础ASCII码,使用7 位二进制数来表示所有的大写和小写字母,数字0 到9、标点符号, 以及在美式英语中使用的特殊控制字符,而第8位用来控制奇偶校验
奇偶校验:是一种校验代码传输正确性的方法。根据被传输的一组二进制代码的数位中“1”的个数是奇数或偶数来进行校验。采用奇数的称为奇校验,反之,称为偶校验。采用何种校验是事先规定好的。
通常专门设置一个奇偶校验位,用它使这组代码中“1”的个数为奇数或偶数。若用奇校验,则当接收端收到这组代码时,校验“1”的个数是否为奇数,从而确定传输代码的正确性。

ASCII只能满足美国的应用,其他国家为了满足对本国文字的需要,对ASCII码进行了扩展。取消奇偶校验位,改成了256字符。
2、ANSI
ansi这种字符码 在windows操作系统不同的言语环境中表示不同的字符编码
在简体中文系统下,ANSI 编码代表 GB2312 编码,在日文操作系统下,ANSI 编码代表 JIS 编码
3、GB2312、GBK和GB18030的区别
(1)GB2312
当 中国人们得到计算机时,已经没有可以利用的字节状态来表示汉字,况且有6000多个常用汉字需要保存,于是想到把那些ASCII码中127号 之后的奇异符号们直接取消掉, 规定:一个小于127的字符的意义与原来相同,但两个大于127的字符连在一起时,就表示一个汉字,前面的一个字节(称之为高字节)从0xA1用到 0xF7,后面一个字节(低字节)从0xA1到0xFE,这样我们就可以组合出大约7000多个简体汉字了。在这些编码里,我们还把数学符号、罗马希腊的 字母、日文的假名们都编进去了,连在 ASCII 里本来就有的数字、标点、字母都统统重新编了两个字节长的编码,这就是常说的"全角"字符,而原来在127号以下的那些就叫"半角"字符了。这种汉字方案 叫做 "GB2312"。GB2312 是对 ASCII 的中文扩展。兼容ASCII。
(2)GBK
但 是中国的汉字太多了,我们很快就就发现有许多人的人名没有办法在这里打出来,不得不继续把 GB2312 没有用到的码位找出来用上。后来还是不够用,于是干脆不再要求低字节一定是127号之后的内码,只要第一个字节是大于127就固定表示这是一个汉字的开 始,不管后面跟的是不是扩展字符集里的内容。结果扩展之后的编码方案被称为 “GBK” 标准,GBK 包括了 GB2312 的所有内容,同时又增加了近20000个新的汉字(包括繁体字)和符号。
(3)GB18030
后来少数民族也要用电脑了,于是我们再扩展,又加了几千个新的少数民族的字,GBK 扩成了 GB18030。从此之后,中华民族的文化就可以在计算机时代中传承了。
中 国的程序员们看到这一系列汉字编码的标准是好的,于是通称他们叫做 "DBCS"(Double Byte Charecter Set 双字节字符集)。在DBCS系列标准里,最大的特点是两字节长的汉字字符和一字节长的英文字符并存于同一套编码方案里,因此他们写的程序为了支持中文处 理,必须要注意字串里的每一个字节的值,如果这个值是大于127的,那么就认为一个双字节字符集里的字符出现了。在这种情况下,"一个汉字算两个英文字 符!"。然而,在Unicode环境下却并非总是如此。
4、ISO-8859
标准
ASCII收录了空格及94个“可印刷字符”,足以给英语使用。但是,其他使用拉丁字母的语言(主要是欧洲国家的语言),都有一定数量的附加符号字母,故可以使用ASCII及控制字符以外的区域来储存及表示。
除了使用拉丁字母的语言外,使用西里尔字母的东欧语言、希腊语、泰语、现代阿拉伯语、希伯来语等,都可以使用这个形式来储存及表示。
按国家/地区分别编码。 ISO陆续语系)的扩充ASCII制定了十多个适用于不同国家和地区(均为拉丁字符集(高位为1的8位代码),称为ISO8859
又称为 扩充ASCII字符集
字符集
ISO/IEC 8859-1 (Latin-1) - 西欧语言
ISO/IEC 8859-2 (Latin-2) - 中欧语言
ISO/IEC 8859-3 (Latin-3) - 南欧语言。世界语也可用此字符集显示。
ISO/IEC 8859-4 (Latin-4) - 北欧语言
ISO/IEC 8859-5 (Cyrillic) - 斯拉夫语言
ISO/IEC 8859-6 (Arabic) - 阿拉伯语
ISO/IEC 8859-7 (Greek) - 希腊语
ISO/IEC 8859-8 (Hebrew) - 希伯来语(视觉顺序)
ISO 8859-8-I - 希伯来语(逻辑顺序)
ISO/IEC 8859-9(Latin-5 或 Turkish)- 它把Latin-1的冰岛语字母换走,加入土耳其语字母。
ISO/IEC 8859-10(Latin-6 或 Nordic)- 北日耳曼语支,用来代替Latin-4。
ISO/IEC 8859-11 (Thai) - 泰语,从泰国的 TIS620 标准字集演化而来。
ISO/IEC 8859-13(Latin-7 或 Baltic Rim)- 波罗的语族
ISO/IEC 8859-14(Latin-8 或 Celtic)- 凯尔特语族
ISO/IEC 8859-15 (Latin-9) - 西欧语言,加入Latin-1欠缺的芬兰语字母和大写法语重音字母,以及欧元(€)符号。
ISO/IEC 8859-16 (Latin-10) - 东南欧语言。主要供罗马尼亚语使用,并加入欧元符号。
由于英语没有任何重音字母(不计外来词),故可使用以上十五个字集中的任何一个来表示。
至于德语方面,因它除了 A-Z, a-z 外,只用 Ä, Ö, ü, ä, ö, ß, ü 七个字母,而所有拉丁字集(1-4, 9-10, 13-16)均有此七个字母,故德语可使用以上十个字集中的任何一个来表示。
此系列中没有-12号的原因是,此计划原本要设计成一个包含塞尔特语族字符集的“Latin-7”,但后来塞尔特语族变成了ISO 8859-14 / Latin-8。亦有一说谓-12号本来是预留给印度天城体梵文的,但后来却搁置了。
5、Unicode编码