1. 定义 .proto 文件:
首先我们需要编写一个 proto 文件,定义我们程序中需要处理的结构化数据,在 protobuf 的术语中,结构化数据被称为 Message。proto 文件非常类似 java 或者 C 语言的 数据定义,可以使用 C或 C++风格的注释,下面是proto文件的例子
package tutorial; option java_package = "com.example.tutorial"; option java_outer_classname = "AddressBookProtos"; message Person { required string name = 1; required int32 id = 2; // Unique ID number for this person. optional string email = 3; enum PhoneType { MOBILE = 0; HOME = 1; WORK = 2; } message PhoneNumber { required string number = 1; optional PhoneType type = 2 [default = HOME]; } repeated PhoneNumber phone = 4; } // Our address book file is just one of these. message AddressBook { repeated Person person = 1; }
一个 proto 文件主要包含 package定义、 message定义和属性定义三个部分,还有一些 可选项。
1.1 定义 package
Package在 c++中对应 namespace。 对于 Java,包声明符会变为 java 的一个包,除非在 .proto 文件中提供了一个明确有 java_package。
1.2 定义 message
Message在 C++中对应 class。Message中定义的全部属性在 class中全部为 private 的。
Message的嵌套使用可以嵌套定义,也可以采用先定义再使用的方式。
Message的定义末尾可以采用 java方式在末尾不加“ ;”,也可以采用 C++定义方式在末尾加 上“;”,这两种方式都兼容,建议采用 java定义方式。
向.proto 文件添加注释,可以使用 C/C++/java风格的双斜杠( // ) 语法格式。
1.3 定义属性
属性定义分为四部分:标注 +类型+属性名 +属性顺序号 +[默认值 ],其示意如下所示

其中属性名与 C++和 java语言类似,不再解释;下面分别对标注、类型和属性顺序号加 以详细介绍。 其中包名和消息名以及其中变量名均采用 java 的命名规则——驼峰式命名法。
1.3.1 标注
标注包括“ required”、“optional”、“repeated”三种,其中
required 表示该属性为必选属性,否则对应的 message“未初始化”,debug 模式下导致 断言, release模式下解析失败;
optional 表示该属性为可选属性,不指定,使用默认值( int 或者 char 数据类型默认为 0,string 默认为空, bool 默认为 false,嵌套 message默认为构造,枚举则为第一个)
repeated 表示该属性为重复字段,可看作是动态数组,类似于 C++中的 vector。
如果为 optional 属性,发送端没有包含该属性,则接收端在解析式采用默认值。对于默认值,如果已设置默认值,则采用默认值,如果未设置,则类型特定的默认值为使用,例如 string 的默认值为 ” ”。
1.3.2 类型
Protobuf 的属性基本包含了 c++需要的所有基本属性类型。
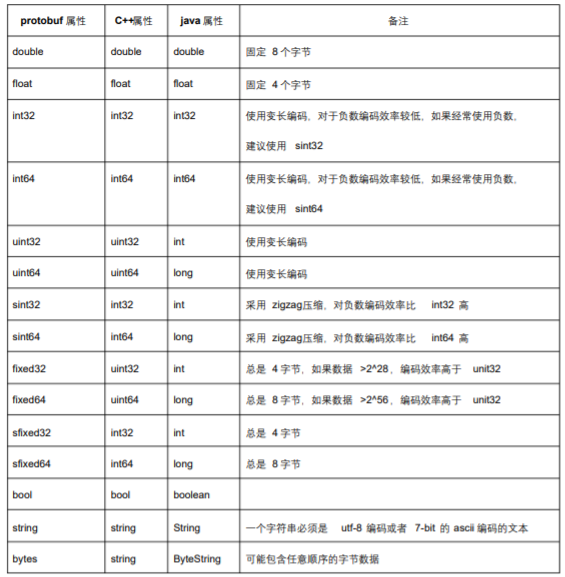
1.3.2.1 Union 类型定义
Protobuf 没有提供 union 类型,如果希望使用 union 类型,可以采用 enum 和 optional 属性定义的方式。 例如,如果已经定义了 Foo、Bar、Baz等 message,则可以采用如下定义。
message OneMessage { enum Type { FOO = 1; BAR = 2; BAZ = 3; } // Identifies which field is filled in. required Type type = 1; // One of the following will be filled in. optional Foo foo = 2; optional Bar bar = 3; optional Baz baz = 4; }
1.3.3 属性顺序号
属性顺序号是 protobuf 为了提高数据的压缩和可选性等功能定义的, 需要按照顺序进行 定义,且不允许有重复。
1.4. 其他
1.4.1 import 可选项
Import 可选项用于包含其它 proto 文件中定义的 message或 enum等。标准格式如 下
import “phonetype.proto ”;
使用时,import 的文件必须与当前文件处于同一个文件夹下, protoc 无法完成不处于同 一个文件夹下的 import 选项。
1.4.2 packed
packed (field option): 如果该选项在一个整型基本类型上被设置为真, 则采用更紧凑的编 码方式。当然使用该值并不会对数值造成任何损失。在 2.3.0 版本之前,解析器将会忽略那些非期望的包装值。因此,它不可能在不破坏现有框架的兼容性上而改变压缩格式。 在 2.3.0 之后,这种改变将是安全的,解析器能够接受上述两种格式,但是在 处理 protobuf 老版本 程序时,还是要多留意一下。
repeated int32 samples = 4 [packed=true];
1.4.3 default
[default = default_value]: optional 类型的字段,如果在序列化时没有被设置,或者是老版 本的消息中根本不存在该字段,那么在反序列化该类型的消息是, optional 的字段将被赋予类型相关的缺省值,如 bool 被设置为 false,int32 被设置为 0。Protocol Buffer 也支持自定义 的缺省值,如:
optional int32 result_per_page = 3 [default = 10];
1.5 大数据量使用建议
在使用过程中发现,对于大数据量的协议报文(循环超过10000 条),如果 repeated 修饰的属性为对象类型 (诸如 message 、Bytes、string 等称为“对象类型”,其余的诸如 int32、 int64、float 等等称为“原始类型” )时,效率非常低,而且占用的进程内存也非常大,建议 采用如下方式优化。
1.5.1 repeated message类型
在 message 中对 repeated 标识的 message类型的字段需要做大量 ADD操作时,可以考 虑尽量避免嵌套 message或者减少嵌套的 message个数。 实例如下所示:
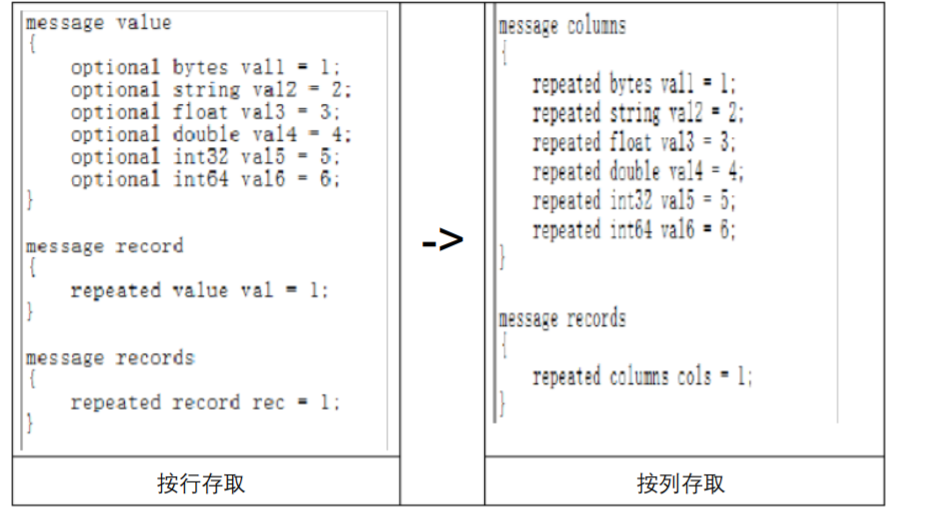
1.5.2 repeated raw 类型
在 message中对 repeated 标识的原始数据类型的字段需要做大量 ADD操作(例如超过3千)时,可以考虑预分配数据空间,避免重复大量地分配空间。 实例如下所示:

1.5.3 repeated Bytes类型
在 protobuf 中,Bytes基于 C++ STL中的 string 实现,因为 string 内存管理的原因,程序 空间往往较大。所以应用如果有很多 repeated Bytes类型的字段的话,进程显示耗用大量内存,这与 vector的情况基本一致。
1.6 Protocol Buffer 消息升级原则
在实际的开发中会存在这样一种应用场景, 即消息格式因为某些需求的变化而不得不进行必要的升级, 但是有些使用原有消息格式的应用程序暂时又不能被立刻升级, 这便要求我们在升级消息格式时要遵守一定的规则, 从而可以保证基于新老消息格式的新老程序同时运行。规则如下:
1. 不要修改已经存在字段的标签号。
2. 任何新添加的字段必须是 optional 和 repeated 限定符,否则无法保证新老程序在 互相传递消息时的消息兼容性。
3. 在原有的消息中, 不能移除已经存在的 required 字段,optional 和 repeated 类型的 字段可以被移除,但是他们之前使用的标签号必须被保留,不能被新的字段重用。
4. int32、uint32、int64、uint64 和 bool 等类型之间是兼容的, sint32 和 sint64 是兼容 的,string 和 bytes 是兼容的, fixed32 和 sfixed32,以及 fixed64 和 sfixed64之间是兼容的, 这意味着如果想修改原有字段的类型时, 为了保证兼容性, 只能将其修改为与其原有类型兼 容的类型,否则就将打破新老消息格式的兼容性。
5. optional 和 repeated 限定符也是相互兼容的。
第2章 编译 .proto文件
可以通过定义好的 .proto 文件来生成 Java、Python、C++代码,需要基于 .proto 文件运行 protocol buffer 编译器 protoc。运行的命令如下所示:
protoc --proto_path=IMPORT_PATH --cpp_out=DST_DIR --java_out=DST_DIR --python_out=DST_DIR path/to/file.proto
MPORT_PATH声明了一个 .proto 文件所在的具体目录。 如果忽略该值, 则使用当前目录。
如果有多个目录则可以 对 --proto_path 写多次,它们将会顺序的被访问并执行导入。 -I=IMPORT_PATH是它的简化形式。
当然也可以提供一个或多个输出路径: --cpp_out 在目标目录 DST_DIR 中 产 生 C++ 代 码 ,
你必须提供一个或多个 .proto 文件作为输入。多个 .proto 文件能够一次全部声明。虽然 这些文件是相对于当前目录来命名的,每个文件必须在一个 IMPORT_PATH中,只有如此编 译器才可以决定它的标准名称。
第3章 使用 message
3.1 类成员变量的访问
在生成的 .h 文件中定义了类成员的访问方法。例如,对于 Person类,定义了 name、id、 email、phone 等成员的访问方法。 获取成员变量值直接采用使用成员变量名(全部为小写) ,设置成员变量值,使用在成 员变量名前加 set_的方法。
对于普通成员变量( required 和 optional)提供 has_方法判断变量值是否被设置;提供 clear_方法清除设置的变量值。
对于 string 类型,提供多种 set_方法,其参数不同。同时,提供了一个 mutable_方法, 返回变量值的可修改指针。
对于 repeated 变量,提供了其它一些特殊的方法:
_size方法:返回 repeated field’s size
通过下脚标访问其中的数组成员组
通过 mutable_的方法返回指针
_add 方法:增加一个成员。
// name inline bool has_name() const; inline void clear_name(); inline const ::std::string& name() const; inline void set_name(const ::std::string& value); inline void set_name(const char* value); inline ::std::string* mutable_name(); // id inline bool has_id() const; inline void clear_id(); inline int32_t id() const; inline void set_id(int32_t value); // email inline bool has_email() const; inline void clear_email(); inline const ::std::string& email() const; inline void set_email(const ::std::string& value); inline void set_email(const char* value); inline ::std::string* mutable_email(); // phone inline int phone_size() const; inline void clear_phone(); inline const ::google::protobuf::RepeatedPtrField< ::tutorial::Person_PhoneNumber >& phone() const; inline ::google::protobuf::RepeatedPtrField< ::tutorial::Person_PhoneNumber >* mutable_phone(); inline const ::tutorial::Person_PhoneNumber& phone(int index) const; inline ::tutorial::Person_PhoneNumber* mutable_phone(int index); inline ::tutorial::Person_PhoneNumber* add_phone();
3.2 标准 message 方法
生成的 .h 文件中的 class都继承自 ::google::protobuf::Message 类,Message类提供了一些 方法可以检查或者操作整个 message,包括
bool IsInitialized() const; 检查是否所有 required 变量都已经初始化;
string DebugString() const; 返回 message的可阅读的表示,主要用于调试程序;
void CopyFrom(const Person& from); 使用一个 message的值覆盖本message;
void Clear(); 清空 message的所有成员变量值。
3.3 编码和解码函数
每个 message类都提供了写入和读取 message数据的方法,包括
bool SerializeToString(string* output) const; 把 message编码进 output 。
bool ParseFromString(const string& data); 从 string 解码到 message
bool SerializeToArray(char* buf,int size) const; 把 message编码进数组 buf.
bool ParseFromArray(const char* buf,int size); 把 buf 解码到 message。此解 码方法效率较 ParseFromString高很多,所以一般用这种方法解码。
bool SerializeToOstream(ostream* output) const; 把 message编码进 ostream
bool ParseFromIstream(istream* input); 从 istream 解码到 message
备注:发送接收端所使用的加码解码方法不一定非得配对,即发送端用 SerializeToString 接收端不一定非得用 ParseFromString ,可以使用其他解码方法。
例子:
简单 message 生成的 C++代码
这里先定义一个最简单的 message,其中只是包含原始类型的字段。
option optimize_for = LITE_RUNTIME; message LogonReqMessage { required int64 acctID = 1; required string passwd = 2; }
由于我们在 MyMessage 文件中定义选项 optimize_for 的值为 LITE_RUNTIME,因此由 该 .proto 文 件 生 成 的 所 有 C++类 的 父 类 均 为 ::google::protobuf::MessageLite , 而 非::google::protobuf::Message。MessageLite类是 Message的父类,在 MessageLite中将缺少 Protocol Buffer 对反射的支持,而此类功能均在 Message类中提供了具体的实现。使用 LITE 版本的 Protocol Buffer。这样不仅可以得到更高编码效率,而且生成代码编译后所占用的资 源也会更少,至于反射所能带来的灵活性和极易扩展性。下面我们来看一下由 message LogonReqMessage生成的 C++类的部分声明,以及常用方法的说明性注释。
class LogonReqMessage : public ::google::protobuf::MessageLite { public: LogonReqMessage(); virtual ~LogonReqMessage(); // implements Message ---------------------------------------------- // 下面的成员函数均实现自 MessageLite 中的虚函数。 // 创建一个新的 LogonReqMessage对象,等同于 clone。 LogonReqMessage* New() const; // 用另外一个 LogonReqMessage对象初始化当前对象,等同于赋值操作符重载( operator=) void CopyFrom(const LogonReqMessage& from); // 清空当前对象中的所有数据,既将所有成员变量置为未初始化状态。 void Clear(); // 判断当前状态是否已经初始化。 bool IsInitialized() const; // 在给当前对象的所有变量赋值之后,获取该对象序列化后所需要的字节数。 int ByteSize() const; // 获取当前对象的类型名称。 ::std::string GetTypeName() const; // required int64 acctID = 1; // 下面的成员函数都是因 message中定义的 acctID 字段而生成。 // 这个静态成员表示 AcctID 的标签值。命名规则是 k + FieldName(驼峰规则) + FieldNumber。 static const int kAcctIDFieldNumber = 1; // 如果 acctID字段已经被设置返回 true ,否则 false。 inline bool has_acctid() const; // 执行该函数后 has_acctid 函数将返回 false,而下面的 acctid 函数则返回 acctID 的缺省值。 inline void clear_acctid(); // 返回 acctid 字段的当前值,如果没有设置则返回 int64 类型的缺省值。 inline ::google::protobuf::int64 acctid() const; // 为 acctid 字段设置新值,调用该函数后 has_acctid 函数将返回 true。 inline void set_acctid(::google::protobuf::int64 value); // required string passwd = 2; // 下面的成员函数都是因 message中定义的 passwd 字段而生成。这里生成的函数和上面 acctid // 生成的那组函数基本相似。因此这里只是列出差异部分。 static const int kPasswdFieldNumber = 2; inline bool has_passwd() const; inline void clear_passwd(); inline const ::std::string& passwd() const; inline void set_passwd(const ::std::string& value); // 对于字符串类型字段设置 const char* 类型的变量值。 inline void set_passwd(const char* value); inline void set_passwd(const char* value, size_t size); // 可以通过返回值直接给 passwd 对象赋值。在调用该函数之后 has_passwd 将返回 true。 inline ::std::string* mutable_passwd(); // 释放当前对象对 passwd 字段的所有权,同时返回 passwd 字段对象指针。调用此函数之后, passwd 字段对象 // 的所有权将移交给调用者。此后再调用 has_passwd 函数时将返回 false。 inline ::std::string* release_passwd(); private: ... ... };
下面是读写 LogonReqMessage对象的 C++测试代码和说明性注释
void testSimpleMessage() { printf("==================This is simple message.================ "); // 序列化 LogonReqMessage对象到指定的内存区域。 LogonReqMessage logonReq; logonReq.set_acctid(20); logonReq.set_passwd("Hello World"); // 提前获取对象序列化所占用的空间并进行一次性分配,从而避免多次分配 // 而造成的性能开销。通过该种方式,还可以将序列化后的数据进行加密。 // 之后再进行持久化,或是发送到远端。 int length = logonReq.ByteSize(); char* buf = new char[length]; logonReq.SerializeToArray(buf,length); // 从内存中读取并反序列化 LogonReqMessage对象,同时将结果打印出来。 LogonReqMessage logonReq2; logonReq2.ParseFromArray(buf,length); printf("acctID = %I64d, password = %s ",logonReq2.acctid(),logonReq2.passwd().c_str()); delete [] buf; }
3.5 嵌套 message 生成的 C++代码
enum UserStatus { OFFLINE = 0; ONLINE = 1; } enum LoginResult { LOGON_RESULT_SUCCESS = 0; LOGON_RESULT_NOTEXIST = 1; LOGON_RESULT_ERROR_PASSWD = 2; LOGON_RESULT_ALREADY_LOGON = 3; LOGON_RESULT_SERVER_ERROR = 4; } message UserInfo { required int64 acctID = 1; required string name = 2; required UserStatus status = 3; } message LogonRespMessage { required LoginResult logonResult = 1; required UserInfo userInfo = 2; // 这里嵌套了 UserInfo 消息。 }
对于上述消息生成的 C++代码,UserInfo 因为只是包含了原始类型字段,因此和上例中 的 LogonReqMessage没有太多的差别,这里也就不在重复列出了。由于 LogonRespMessage 消息中嵌套了 UserInfo类型的字段,在这里我们将仅仅给出该消息生成的 C++代码和关键性 注释。
class LogonRespMessage : public ::google::protobuf::MessageLite { public: LogonRespMessage(); virtual ~LogonRespMessage(); // implements Message ---------------------------------------------- ... ... // 这部分函数和之前的例子一样。 // required .LoginResult logonResult = 1; // 下面的成员函数都是因 message中定义的 logonResult 字段而生成。 // 这一点和前面的例子基本相同,只是类型换做了枚举类型 LoginResult。 static const int kLogonResultFieldNumber = 1; inline bool has_logonresult() const; inline void clear_logonresult(); inline LoginResult logonresult() const; inline void set_logonresult(LoginResult value); // required .UserInfo userInfo = 2; // 下面的成员函数都是因 message中定义的 UserInfo 字段而生成。 // 这里只是列出和非消息类型字段差异的部分。 static const int kUserInfoFieldNumber = 2; inline bool has_userinfo() const; inline void clear_userinfo(); inline const ::UserInfo& userinfo() const; // 可以看到该类并没有生成用于设置和修改 userInfo 字段 set_userinfo 函数,而是将该工作 // 交给了下面的 mutable_userinfo 函数。因此每当调用函数之后, Protocol Buffer 都会认为 // 该字段的值已经被设置了,同时 has_userinfo 函数亦将返回 true。在实际编码中,我们可以 // 通过该函数返回 userInfo 字段的内部指针,并基于该指针完成 userInfo 成员变量的初始化工作。 inline ::UserInfo* mutable_userinfo(); inline ::UserInfo* release_userinfo(); private: ... ... };
下面是读写 LogonRespMessage对象的 C++测试代码和说明性注释
void testNestedMessage() { printf("==================This is nested message.================ "); LogonRespMessage logonResp; logonResp.set_logonresult(LOGON_RESULT_SUCCESS); // 如上所述,通过 mutable_userinfo 函数返回 userInfo 字段的指针,之后再初始化该对象指针。 UserInfo* userInfo = logonResp.mutable_userinfo(); userInfo->set_acctid(200); userInfo->set_name("Tester"); userInfo->set_status(OFFLINE); int length = logonResp.ByteSize(); char* buf = new char[length]; logonResp.SerializeToArray(buf,length); LogonRespMessage logonResp2; logonResp2.ParseFromArray(buf,length); printf("LogonResult = %d, UserInfo->acctID = %I64d, UserInfo->name = %s, UserInfo->status = %d " ,logonResp2.logonresult(),logonResp2.userinfo().acctid(),logonResp2.userinfo().name().c_str(),logonResp2.userinfo() .status()); delete [] buf; }
3.6 repeated 嵌套 message 生成的 C++代码
message BuddyInfo { required UserInfo userInfo = 1; required int32 groupID = 2; } message RetrieveBuddiesResp { required int32 buddiesCnt = 1; repeated BuddyInfo buddiesInfo = 2; }
对于上述消息生成的代码, 我们将只是针对 RetrieveBuddiesResp消息所对应的 C++代码 进 行 详 细 说 明 , 其 余 部 分 和 前 面 小 节 的 例 子 基 本 相 同 , 可 直 接 参 照 。 而 对 于 RetrieveBuddiesResp类中的代码,我们也仅仅是对 buddiesInfo 字段生成的代码进行更为详细 的解释。
class RetrieveBuddiesResp : public ::google::protobuf::MessageLite { public: RetrieveBuddiesResp(); virtual ~RetrieveBuddiesResp(); ... ... // 其余代码的功能性注释均可参照前面的例子。 // repeated .BuddyInfo buddiesInfo = 2; static const int kBuddiesInfoFieldNumber = 2; // 返回数组中成员的数量。 inline int buddiesinfo_size() const; // 清空数组中的所有已初始化成员,调用该函数后, buddiesinfo_size 函数将返回 0。 inline void clear_buddiesinfo(); // 返回数组中指定下标所包含元素的引用。 inline const ::BuddyInfo& buddiesinfo(int index) const; // 返回数组中指定下标所包含元素的指针,通过该方式可直接修改元素的值信息。 inline ::BuddyInfo* mutable_buddiesinfo(int index); // 像数组中添加一个新元素。返回值即为新增的元素,可直接对其进行初始化。 inline ::BuddyInfo* add_buddiesinfo(); // 获取 buddiesInfo 字段所表示的容器,该函数返回的容器仅用于遍历并读取,不能直接修改。 inline const ::google::protobuf::RepeatedPtrField< ::BuddyInfo >& buddiesinfo() const; // 获取 buddiesInfo 字段所表示的容器指针,该函数返回的容器指针可用于遍历和直接修改。 inline ::google::protobuf::RepeatedPtrField< ::BuddyInfo >* mutable_buddiesinfo(); private: ... ... };
下面是读写 RetrieveBuddiesResp对象的 C++测试代码和说明性注释
void testRepeatedMessage() { printf("==================This is repeated message.================ "); RetrieveBuddiesResp retrieveResp; retrieveResp.set_buddiescnt(2); BuddyInfo* buddyInfo = retrieveResp.add_buddiesinfo(); buddyInfo->set_groupid(20); UserInfo* userInfo = buddyInfo->mutable_userinfo(); userInfo->set_acctid(200); userInfo->set_name("user1"); userInfo->set_status(OFFLINE); buddyInfo = retrieveResp.add_buddiesinfo(); buddyInfo->set_groupid(21); userInfo = buddyInfo->mutable_userinfo(); userInfo->set_acctid(201); userInfo->set_name("user2"); userInfo->set_status(ONLINE); int length = retrieveResp.ByteSize(); char* buf = new char[length]; retrieveResp.SerializeToArray(buf,length); RetrieveBuddiesResp retrieveResp2; retrieveResp2.ParseFromArray(buf,length); printf("BuddiesCount = %d ",retrieveResp2.buddiescnt()); printf("Repeated Size = %d ",retrieveResp2.buddiesinfo_size()); // 这里仅提供了通过容器迭代器的方式遍历数组元素的测试代码。 // 事实上,通过 buddiesinfo_size 和 buddiesinfo 函数亦可循环遍历。 RepeatedPtrField<BuddyInfo>* buddiesInfo = retrieveResp2.mutable_buddiesinfo(); RepeatedPtrField<BuddyInfo>::iterator it = buddiesInfo->begin(); for (; it != buddiesInfo->end(); ++it) { printf("BuddyInfo->groupID = %d ", it->groupid()); printf("UserInfo->acctID = %I64d, UserInfo->name = %s, UserInfo->status = %d " , it->userinfo().acctid(), it->userinfo().name().c_str(),it->userinfo().status()); } delete [] buf; }
3.7 写入 message
#include"addressbook.pb.h" #include<iostream> #include<unistd.h> #include<sys/types.h> #include<sys/stat.h> #include<fcntl.h> #include<stdio.h> #include<string.h> #include<sys/socket.h> #include<netinet/in.h> #include<arpa/inet.h> #include<stdlib.h> #include<string> using namespace std; { // 填充消息 void PromptInput(tutorial::Person* person){ person->set_id(2008); person->set_name("Joe"); person->set_email("joepayne@163.com"); int i=0; while(i<3){ tutorial::Person::PhoneNumber* phone_number=person->add_phone(); phone_number->set_number("13051889399"); phone_number->set_type(tutorial::Person::MOBILE); i++; } } } int main(){ { // 建立 SOCKET连接 } int n=0; tutorial::AddressBook msg1; PromptInput(msg1.add_person()); string s; int uSize; { // 发送 1 个消息包 while(n<1){ // 两次发送过程 { msg1.SerializeToString(&s); // 把消息包的长度发送出去 usize=s.size(); write(sockfd,&uSize,sizeof(uSize)); // 把消息包发送出去 // 注意如果消息数据比较大的话,一次 IO写操作不能写完,那就需要自己另作处理了 write(sockfd,s.data(),s.size()); } // 输出包的大小 cout<<"Message size:"<<uSize<<endl; n++; } return 0; }
3.8 读出 message
#include"addressbook.pb.h" #include<iostream> #include<unistd.h> #include<sys/types.h> #include<sys/stat.h> #include<fcntl.h> #include<stdio.h> #include<string.h> #include<stdlib.h> #include<sys/socket.h> #include<netinet/in.h> #include<arpa/inet.h> #include<stdlib.h> using namespace std; // 列出消息中的所有数据 void List(const tutorial::AddressBook& address_book){ for(int i=0;i<address_book.person_size();i++){ const tutorial::Person& person=address_book.person(i); cout<<"Person ID:"<<person.id()<<endl; cout<<"Name:"<<person.name()<<endl; if(person.has_email()){ cout<<"E-mail address:"<<person.email()<<endl; } for(int j=0;j<person.phone_size();j++){ const tutorial::Person::PhoneNumber& phone_number=person.phone(j); switch(phone_number.type()){ case tutorial::Person::MOBILE: cout<<"Mobile phone:"; break; case tutorial::Person::HOME: cout<<"Home phone:"; break; case tutorial::Person::WORK: cout<<"WOrk Phone:"; break; } cout<<phone_number.number()<<endl; } } } int main(){ { // 建立连接 } tutorial::AddressBook msg2; int uLen; char* uData; int nRead; { // 读取数据 // 先读取消息包的长度信息 while((nRead=read(connfd,&uLen,sizeof(uLen)))>0){ cout<<"The length of the message is:"<<uLen<<endl; // 根据消息包的长度信息,分配适当大小的缓冲区来接收消息包数据 uData=(char*)malloc(uLen); // 注意此次 read 可能一次性读不完一个包,如果包比较大的话,这样的话就得自己再做进一步处 理 read(connfd,uData,uLen); // 解码操 作,从 缓冲 区中解 到 msg2 消息空间中去, 此 处用 ParseFromArray 而没有使用ParseFromString 因为前者的效率相对于后者效率要高很多。 if(!msg2.ParseFromArray(uData,uLen)){ cout<<”Parse failed!”<<endl; return -1; } free(uData); uData=NULL; // 输出消息的数据信息 List(msg2); } } return 0; }
附录:驼峰命名法
驼峰命名法就是当变量名或函式名是由一个或多个单字连结在一起, 而构成的唯一识别 字时,第一个单字以小写字母开始; 第二个单字的首字母大写或每一个单字的首字母都采用大写字母, 例如:myFirstName、 myLastName,这样的变量名看上去就像骆驼峰一样此起彼伏,故得名。