总览
- 搜索引擎的六个核心组件:爬虫、解析、索引、链接关系分析、查询处理、排名

- 信息检索中的代表性排序模型:
1)传统的排序模型:两类
1. 相关性排序模型:
a) Boolean model: 基于查询term在文档里出现的情况,但不能预测相关性的程度
b)Vectos Space Model: 在欧式空间中将文档与查询词用向量表示,两向量的内积可作为二者相关性。该方法假设term之间彼此独立。此向量的计算可借助于TF-IDF,其中TF为term在文档中的频率,IDF表示term被文档包含的程度(N为总文档数,n(t)为包含termt的文档数目),即TF-IDF=TF*IDF。
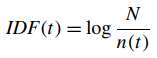
c)Latent Semantic Indexing: 避免使用term独立性假设,利用奇异值分解将原始的特征空间线性变换到隐士语义空间,在该新的空间中进行相关性度量。
d) BM25模型: 利用文档相关性的log-odds进行排序,该模型包含多种类型。下式为一种代表性实现,query包含term (t1,t2,...,tM),TF(t,d)为查询词t在文档d中的词频,LEN(d)为文档d的长度,avdl是包含文档d的文本的平均文档长度,k1,b为参数,IDF(t)为查询词的IDF权值。
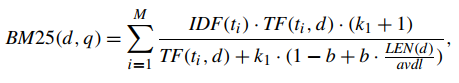
e) Language MOdel for Information Retrieval(LMIR): 使用统计语言模型,每个文档都携带一个语言模型,以query q作为模型输入,文档的相关性由语言模型生成q携带的查询词的概率给出,
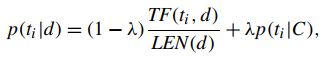
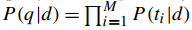
d)其他模型:从内容相似性、超链接结构、网站结构和话题多样性入手;
2.重要性排序模型: 基于文档自身重要性排序
a)PageRank: 基于用户随机点击链接抵达某网页的概率进行排序。网页du的PR值依赖于链接到du的网页dv的PR值,除以dv的出链接数。

同时,用户也有有可能跳转到除邻接页面外的其他网页,所以引入阻尼系数alpha,
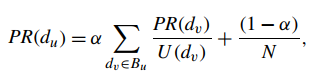
b)PR模型的优化模型:计算性能上、模型精细化,如: topic-sensitive PR
c) TrustRank: 贾三网页重要性时考虑其可靠性
2)排序模型的评估:
1.相关性判定: 三个策略,a)相关度 b)按对的偏好 c)总顺序
2.评估度量方法:a) Mean Reciprocal Rank; b) Mean Average Precision; c)Discounted Comulative Gain; d)Rank Correlation;
- Learning to Rank: LTR
1)定义:利用判别学习,学习从query-document对中获取的特征的最佳组合,典型特点:
1. 基于特征。利用特征向量来表示文档(document)。
2.判别模型训练。LTR模型有自己的输入空间、输出空间、假设空间、损失函数。
2)优点:传统的排序模型大都包含超参数,调参困难。再者, 这些模型的组合也较为困难。基于机器学习的方法在调参与模型融合上具有显著的优势。
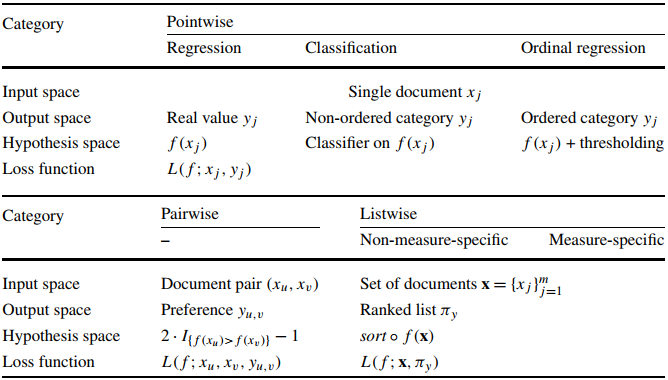
3)LTR框架:三类方法
1. Pointwise Approach:输入空间为单个文档的特征,输出为对应文档与特征的相关性。局限:没有考虑文档间的彼此依赖关系,所以最终排序结果中文档所处的位置对损失函数的不可见的。忽略了一些文档经常与相同的查询词关联的事实。
2. Pairwise Approach:输入空间为文档对的特征,输出为对文档对的偏好程度。局限:仅仅考虑了两个文档见的相对顺序,很难获得文档在最终排序中的位置。
3. Listwise Approach: 输入空间为一组文档及其查询词,输出为文档的排序列表。更适合于信息检索中的排序任务。
4)LTR方法总结:
Pointwise的方法
- 概述:由三个子类构成,1)基于回归的算法,输出相关性得分;2)基于分类的算法,输出无序类;3)顺序(ordinal)回归算法,输出有序类;
- 基于回归的算法:使用均方误差,以基于NDCG的排序误差作为上边界
- 基于分类的算法:1)二分类:SVM、logistic-regression;2)多分类:Boosting tree、Association rule mining (support&&confidence)、
- 顺序回归算法:考虑类标签的顺序关系
1)PRanking:
1. 思想:找到一个投影方向,是的文档的特征向量映射到上面后我们可以方便的利用阈值将其划分到不同的有序类中;
2.方法:迭代式的学习过程
2)借助最大间隔原则的排序:
3)有序回归中基于阈值的损失函数:
- 同相关性反馈的关系:
1)相同:Rochchio算法也会最小化某个pointwise损失函数;
2)不同:
1.Rocchio算法的输入为文档和query的标准向量,而LTR的输入特征空间为从query-document对中提取得到的特征,后者中仅有文档的特征表示,而查询词并不是与其在同一特征空间的向量;
2. 。。。
- Pointwise方法的局限性:
1)由于输入是单个文档,所以文档间的相对顺序在学习过程中无法被考虑到;
2)排序评估时的两种方法,query level、position based无法在此算法中得到反映;
3)解决:RankCosine基于余弦相似度定义了新的损失函数,
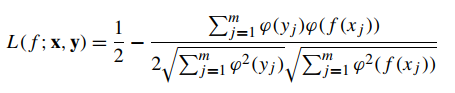
Pairwise的方法
- 概述:对任意两个文档进行分类,关注于文档间的相对顺序而非相关程度。
- 代表性算法:
1)Ordering with Preference Function:
2)SortNet:
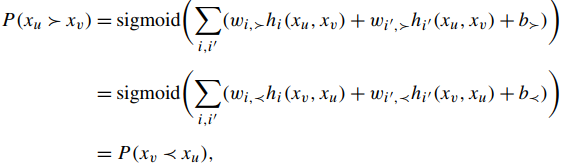

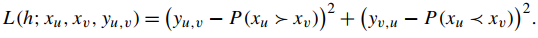
3)RankNet:
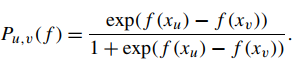

4)FRank: fidelity loss总以0为最小,但非凸
5)RankBoost: 基于AdaBoost

6)Ranking SVM:
7)GBRank:基于梯度增强树

- 优化的算法:
Listwise的方法
- 概述:以单个查询词及其对应的关联文档作为输入,预测文档的真实标签。基于模型所使用的损失函数类型的差异,可以分为两类:1)损失函数直接与评估方法相关联;2)损失函数与评估方法不直接关联;
- 最小化Measure-Specific损失函数:解决如NDCG、MAP等不连续、不可微的评估方法的优化问题
1)近似逼近评估函数
1. SoftRank:认为文档的排序不仅仅由打分函数给出,而是在排序过程中将文档得分作为随机变量,这些随机变量的均值由打分函数给出,


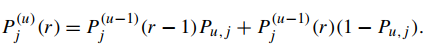
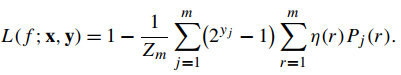
2.利用决策理论框架进行排序:使用决策理论框架类优化评估函数
3.近似排序:评估结果之所以分平滑是因为与排序得分相对应的排序位置是非平滑的。使用平滑函数对排序得分进行处理,对排序位置进行近似逼近可以使得评估结果变得可微,有利于最优化,
4.SmoothRank: 与近似排序相似,区别在于近似函数与优化的方法有所差异
2)优化评估函数的上边界:
1.SVMmap
3)非平滑优化:
1.AdaRank: 使用boosting思想

2.基于Genetic Programming的算法
- 最小化Non-Measure-Specific损失函数
1. ListNet
2. ListMLE
3.Cumulative Distribution Networks
4.BoltzRank
- 实验表明,ListWise的排序算法的效果一般要比pointwise和pairwise的排序算法效果要好
关系型排序
- 概述:不仅考虑单个文档的性质,也在排序时考虑文档间内部的关系,可用于相关性反馈、主题提取以及搜索结果多样化等场景。
- 通用的关系型排序框架:利用合适的文档间关系来定义目标函数
1)关系型排序SVM
2)连续条件随机场:
- 搜索结果多样化的排序:
1)Ranked Explore and Commit 算法
2)Ranked Bandits 算法
3)利用先验的query或者document归属的话题进行信息分类实现多样性:
4)多样化问题可被视为排序问题与聚类问题的组合,将问题转化为从一组最相关的文档中挑选novel的文档
基于查询词的排序
- 概述:考虑query多样性对排序的影响
- 基于query的损失函数
- 基于query的排序函数:
1)基于查询词分类的方法:利用搜索意图将query分类,再构建不同的排序模型
2)基于KNN的方法:
3)基于查询词聚类的方法:
4)基于双层学习的方法:docment layer + query layer
半监督式排序
-
概述: 使用未标记的数据
- Inductive Approach
- Transductive Approach
迁移排序
- 概述:将一种应用场景中LTR数据携带的信息迁移到另外一种场景
- 特征层面的迁移学习:
1.思想:假设源域与目标域之间共享地位的特征
- 实体层面的迁移学习:
1.思想:将源域的数据从概率分布的角度...
LTR中的数据预处理
- 概述:人工数据标记耗时耗力,点击日志挖掘有助于获取大规模数据。同时,选取有效的数据也十分关键。
- 日志挖掘:
1)用户点击模型:
1. 大多数搜索引擎会记录用户与其交互时的点击行为,这些日志信息携带相关性很高的重要信息
2.经典的点击模型:
a)Position Model:假设用户的点击行为同时依赖于文档relevance以及examination。此模型视各文档彼此独立,所以无法捕捉examination概率中文档之间的相关性。
b)Cascade Model: 假设用户按顺序examine各文档,并且只要找到relevant文档就马上停止点击。强假设每次搜索只有一次点击,无法解释搜索时的多次点击行为。
c)Dependent Click Model:在用户点击文档后,使用一组与位置相关的参数对用户返回搜索结果页并进行examination的概率进行建模,以克服级联模型的不足。
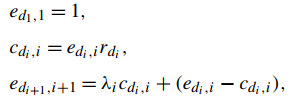
d)Bayesian Browsing Model: 从点击数据中挖掘pairwise信息。
e)Dynamic Bayesian Network Click Model
2)点击数据增强:
1. 学习用户交互的模型:利用query-text、click-through、browsing三组特征描述对搜索结果的满意程度
2.点击数据的平滑:query聚类技术
- 训练数据选择
1)用于标记的数据选择
2)用于训练的数据选择
引用:
[1] Liu T Y. Learning to rank for information retrieval[M]. Springer Science & Business Media, 2011.