0.展示PTA总分

1.本周学习总结
1.1 总结栈和队列内容
1.栈的存储结构及操作
-
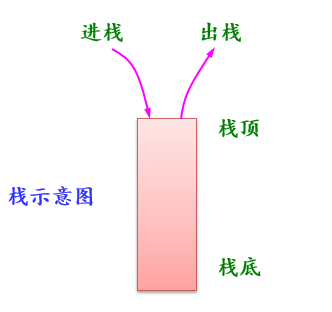
栈的概念和特点:
- 允许进行插入、删除操作的一端称为栈顶。
- 表的另一端称为栈底。
- 当栈中没有数据元素时,成为空栈。
- 栈的插入操作通常称为进栈或入栈。
- 栈的删除操作通常称为退栈或出栈。
- 栈的主要特点是后进先出,即后进栈的元素先出栈,也被称为后进先出表。
-
栈的存储结构
- 栈中元素逻辑关系与线性表的相同,栈可以采用与线性表相同的存储结构。

- 栈中元素逻辑关系与线性表的相同,栈可以采用与线性表相同的存储结构。
-
栈的顺序存储结构
假设栈的元素个数最大不超过正整数MaxSize,所有的元素都具有统一数据类型ElemType,则可以用一下方式来定义顺序栈的类型SqStack。
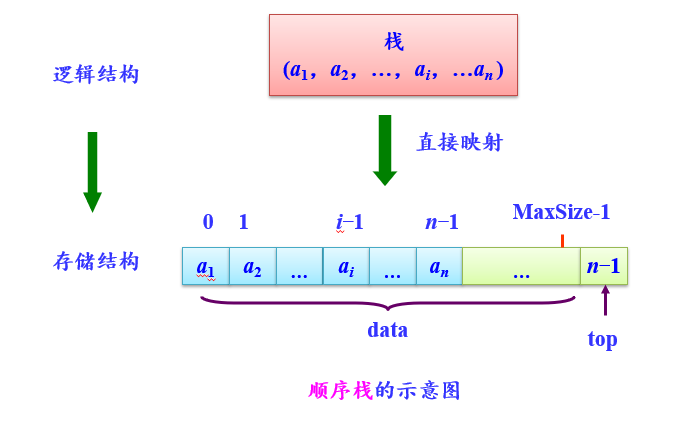
顺序栈四要素- 栈空条件:top=-1
- 进栈e操作:top++; 将e放在top处
- 进栈时top增1,出栈时top减1
- 退栈操作:从top处取出元素e; top--;
-
初始化栈InitStack(&s)
建立一个新的空栈s,实际上是将栈顶指针指向-1即可。
void InitStack(SqStack *&s)
{
s=(SqStack*)malloc(sizeof(SqStack));
s->top=- -1;
}
- 销毁栈
void DestroyStack(SqStack *&s)
{
free(s);
}
- 判断栈是否为空StackEmpty(s)
栈S为空的条件是s->top==-1。
bool StackEmpty(SqStack *s)
{
return(s->top==-1);
}
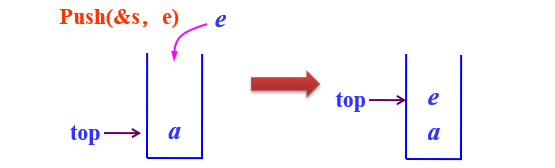
- 进栈Push(&s,e)
在栈不满的条件下,先将栈指针增1,然后在该位置上插入元素e。
bool Push(SqStack *&s,ElemType e)
{ if (s->top==MaxSize-1) //栈满的情况,即栈上溢出
return false;
s->top++; //栈顶指针增1
s->data[s->top]=e; //元素e放在栈顶指针处
return true;
}
- 出栈Pop(&s,&e)
在栈不为空的条件下,先将栈顶元素赋给e,然后将栈指针减1
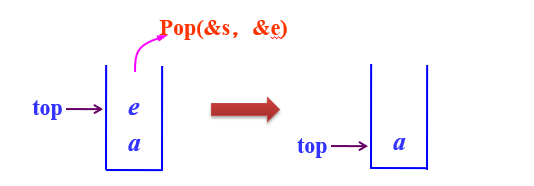
bool Pop(SqStack *&s,ElemType &e)
{ if (s->top==-1) //栈为空的情况,即栈下溢出
return false;
e=s->data[s->top]; //取栈顶指针元素的元素
s->top--; //栈顶指针减1
return true;
}
- 取栈顶元素GetTop(s,&e)
在栈不为空的条件下,将栈顶元素赋给e。
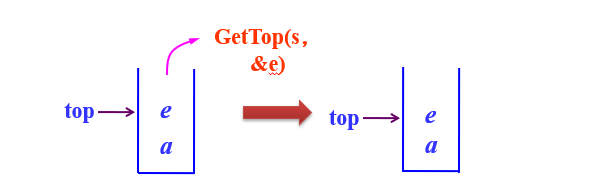
bool GetTop(SqStack *s,ElemType &e)
{
if (s->top==-1) //栈为空的情况,即栈下溢出
return false;
e=s->data[s->top]; //取栈顶指针元素的元素
return true;
}
- 栈的链式存储结构
采用链表存储的栈称为链栈,这里采用带头结点的单链表实现。
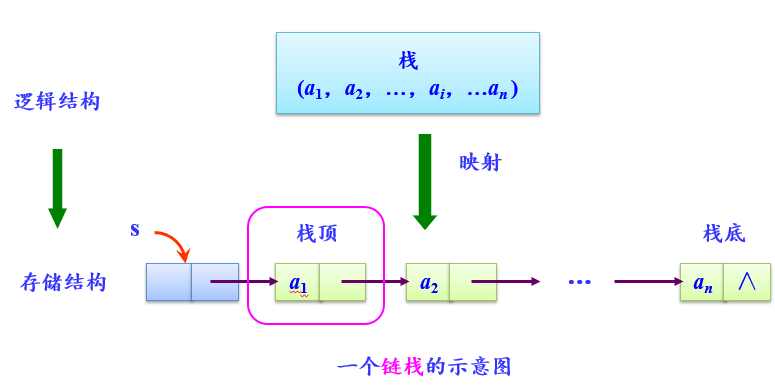
链栈四要素
1.栈空条件:s->next=NULL
2.栈满条件:不考虑
3.进栈e操作:将包含e的结点插入到头结点之后
4.退栈操作:取出头结点之后结点的元素并删除之
- 初始化栈InitStack(&s)
建立一个空栈s。实际上是创建链栈的头结点,并将其next域置为NULL。

void (LinkStNode *&s)
{ s=(LiStaInitStackck *)malloc(sizeof(LinkStNode));
s->next=NULL;
}
- 销毁栈
释放栈s占用的全部存储空间。
void DestroyStack(LinkStNode *&s)
{ LinkStNode *p=s,*q=s->next;
while (q!=NULL)
{ free(p);
p=q;
q=p->next;
}
free(p); //此时p指向尾结点,释放其空间
}
- 判断栈是否为空StackEmpty(s)
栈S为空的条件是s->next==NULL,即单链表中没有数据结点。
bool StackEmpty(LinkStNode *s)
{
return(s->next==NULL);
}
- 进栈Push(&s,e)
将新数据结点插入到头结点之后。

void Push(LinkStNode *&s,ElemType e)
{ LinkStNode *p;
p=(LinkStNode *)malloc(sizeof(LinkStNode));
p->data=e; //新建元素e对应的结点*p
p->next=s->next; //插入*p结点作为开始结点
s->next=p;
}
- 出栈Pop(&s,&e)
在栈不为空的条件下,将头结点后继数据结点的数据域赋给e,然后将其删除。
bool Pop(LinkStNode *&s,ElemType &e)
{ LinkStNode *p;
if (s->next==NULL) //栈空的情况
return false;
p=s->next; //p指向开始结点
e=p->data;
s->next=p->next; //删除*p结点
free(p); //释放*p结点
return true;
}
- 取栈顶元素GetTop(s,&e)
在栈不为空的条件下,将头结点后继数据结点的数据域赋给e。
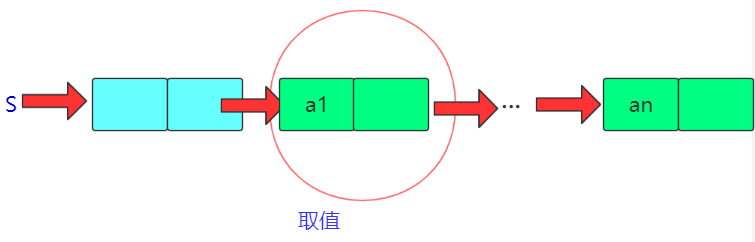
bool GetTop(LinkStNode *s,ElemType &e)
{ if (s->next==NULL) //栈空的情况
return false;
e=s->next->data;
return true;
}
2.栈的应用
- 表达式转换--选自PTA题集-2019-栈和队列
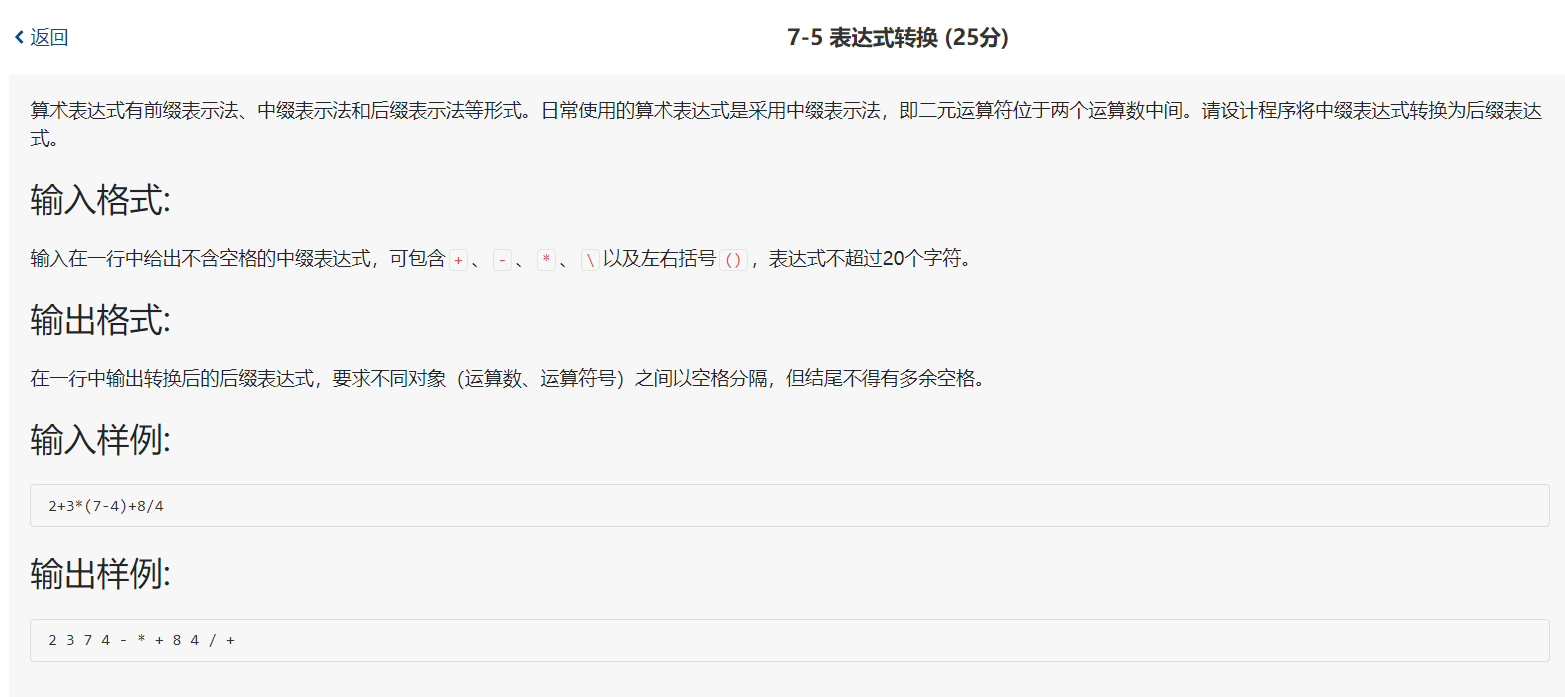
这道题是一道很典型的栈的应用。由于中缀表达式转换为后缀表达式中关于优先级的判断,我们可以很容易的想到利用栈后进先出的性质来进行解题。我们通过读取字符,运用合适的优先级判断来对遇到的符号进行入栈,出栈,输出等操作,从而达到我们的目的。
3.队列的存储结构及操作
-
队列的概念和特点:
- 把进行插入的一端称做队尾(rear)。
- 进行删除的一端称做队首或队头(front)。
- 向队列中插入新元素称为进队或入队,新元素进队后就成为新的队尾元素。
- 从队列中删除元素称为出队或离队,元素出队后,其后继元素就成为队首元素。
- 队列的主要特点是先进先出,所以队列又被成为先进先出表。

-
队列的存储结构
既然队列中元素逻辑关系与线性表的相同,队列可以采用与线性表相同的存储结构。

-
队列的顺序存储结构
顺序队类型SqQueue定义如下:
typedef struct
{ ElemType data[MaxSize];
int front,rear; //队首和队尾指针
} SqQueue
PS:因为队列的两端都在变化,所以需要两个指针来标识队列的状态。
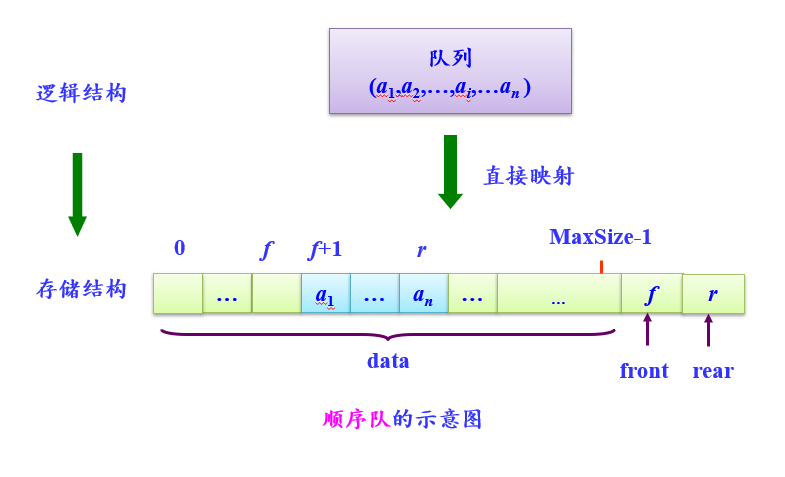
顺序队四要素
1. 队空条件:front = rear
2. 队满条件:rear = MaxSize-1
3. 元素e进队:rear++; data[rear]=e;
4. 元素e出队:front++; e=data[front];
- 初始化队列InitQueue(q)
构造一个空队列q。将front和rear指针均设置成初始状态即-1值。
void InitQueue(SqQueue *&q)
{ q=(SqQueue *)malloc (sizeof(SqQueue));
q->front=q->rear=-1;
}
- 销毁队列DestroyQueue(q)
释放队列q占用的存储空间。
void DestroyQueue(SqQueue *&q)
{
free(q);
}
- 判断队列是否为空QueueEmpty(q)
若队列q满足q->front==q->rear条件,则返回true;否则返回false。
bool QueueEmpty(SqQueue *q)
{
return(q->front==q->rear);
}
- 进队列**enQueue(q,e) **
在队列不满的条件下,先将队尾指针rear循环增1,然后将元素添加到该位置。

bool enQueue(SqQueue *&q,ElemType e)
{ if (q->rear==MaxSize-1) //队满上溢出
return false;
q->rear++;
q->data[q->rear]=e;
return true;
}
-
- 出队列deQueue(q,e)
在队列q不为空的条件下,将队首指针front循环增1,并将该位置的元素值赋给e。
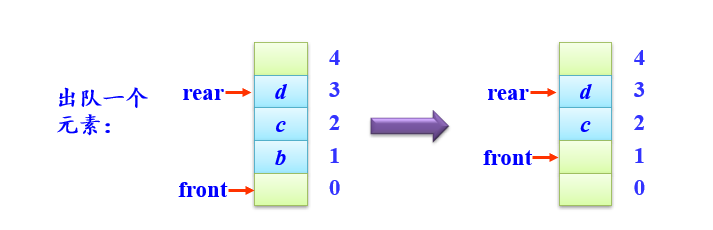
bool deQueue(SqQueue *&q,ElemType &e)
{ if (q->front==q->rear) //队空下溢出
return false;
q->front++;
e=q->data[q->front];
return true;
}
-
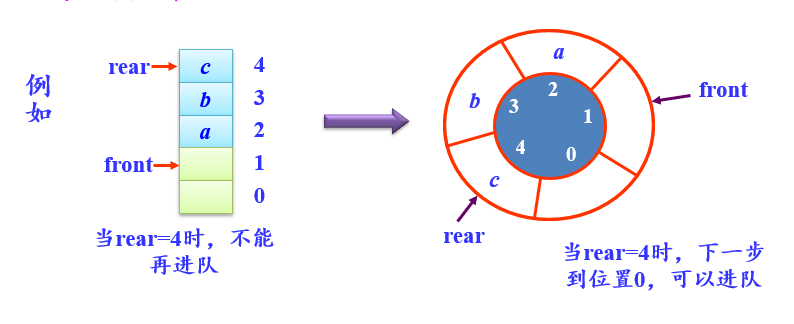
环形队列
把数组的前端和后端连接起来,形成一个环形的顺序表,即把存储队列元素的表从逻辑上看成一个环,称为环形队列或循环队列。
环形队列四要素:- 队空条件:front = rear
- 队满条件:(rear+1)%MaxSize = front
- 进队e操作:rear=(rear+1)%MaxSize; 将e放在rear处
- 出队操作:front=(front+1)%MaxSize; 取出front处元素e;
-
队列的链式存储
采用链表存储的队列称为链队。
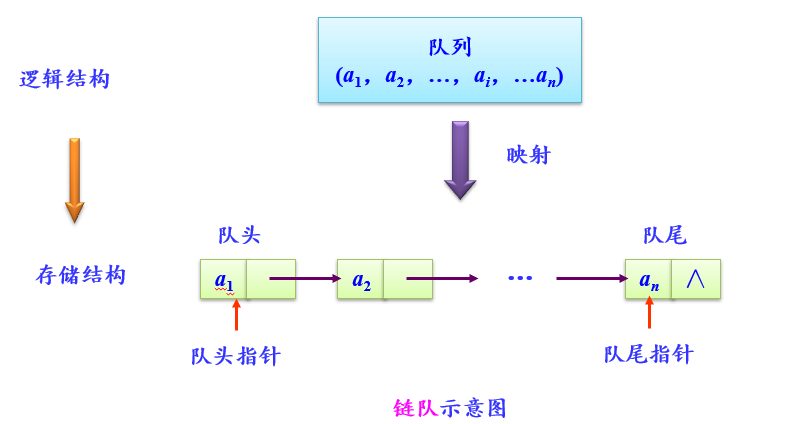
链队组成:- 存储队列元素的单链表结点
- 指向队头和队尾指针的链队头结点
链队四要素 - 队空条件:front=rear=NULL
- 队满条件:不考虑
- 进队e操作:将包含e的结点插入到单链表表尾
- 出队操作:删除单链表首数据结点
-
初始化队列InitQueue(q)
构造一个空队列,即只创建一个链队头结点,其front和rear域均置为NULL,不创建数据元素结点。
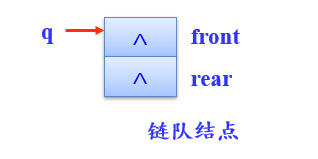
void InitQueue(LinkQuNode *&q)
{ q=(LinkQuNode *)malloc(sizeof(LinkQuNode));
q->front=q->rear=NULL;
}
- 销毁队列DestroyQueue(q)
释放队列占用的存储空间,包括链队头结点和所有数据结点的存储空间。
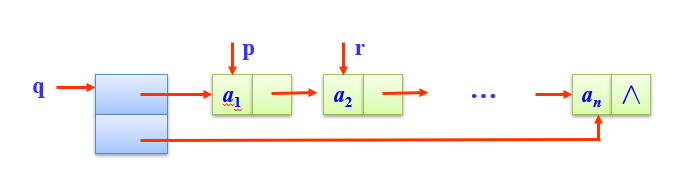
void DestroyQueue(LinkQuNode *&q)
{ DataNode *p=q->front,*r; //p指向队头数据结点
if (p!=NULL) //释放数据结点占用空间
{ r=p->next;
while (r!=NULL)
{ free(p);
p=r;r=p->next;
}
}
free(p); free(q); //释放链队结点占用空间
}
- 判断队列是否为空QueueEmpty(q)
若链队结点的rear域值为NULL,表示队列为空,返回true;否则返回false。
bool QueueEmpty(LinkQuNode *q)
{
return(q->rear==NULL);
}
- 进队列**enQueue(q,e) **
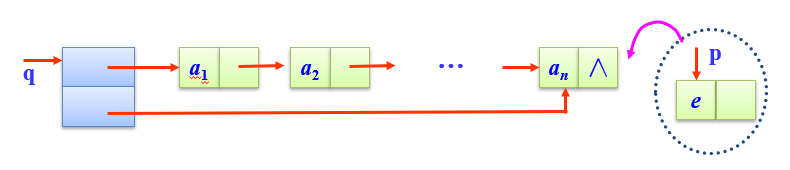
考虑情况:
- 原队列为空
- 原队列不为空
void enQueue(LinkQuNode *&q,ElemType e)
{ DataNode *p;
p=(DataNode *)malloc(sizeof(DataNode));
p->data=e;
p->next=NULL;
if (q->rear==NULL) //若链队为空,新结点是队首结点又是队尾结点
q->front=q->rear=p;
else
{ q->rear->next=p; //将*p结点链到队尾,并将rear指向它
q->rear=p;
}
}
- 出队deQueue(q,e)
考虑情况:- 原队列为空
- 原队列只有一个结点
- 其他情况
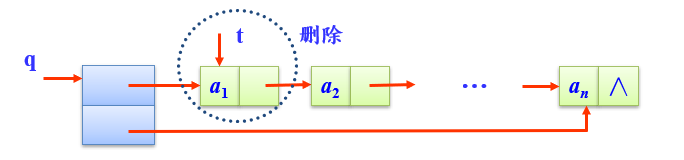
bool deQueue(LinkQuNode *&q,ElemType &e)
{ DataNode *t;
if (q->rear==NULL) return false; //队列为空
t=q->front; //t指向第一个数据结点
if (q->front==q->rear) //队列中只有一个结点时
q->front=q->rear=NULL;
else //队列中有多个结点时
q->front=q->front->next;
e=t->data;
free(t);
return true;
}
4.队列应用
- 用队列求解迷宫问题
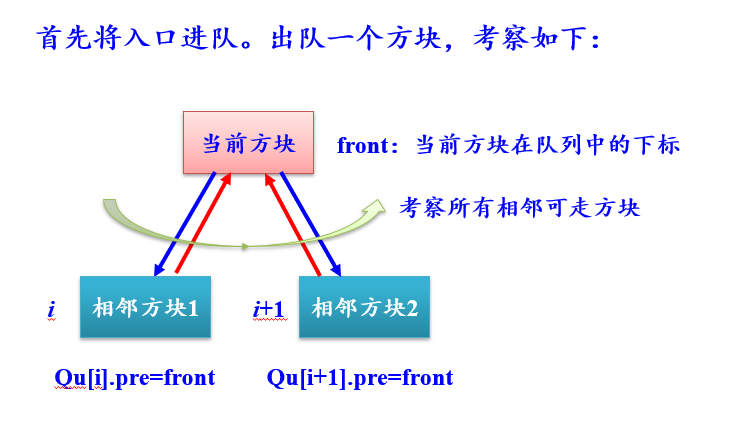
因此,所有的搜索过的方块都在队列中,最后通过队列找出从出口到入口的一条迷宫路径。
1.2.谈谈你对栈和队列的认识及学习体会。
认识
- 这两周我们主要学习了栈和队列的基本操作和应用,同时也开始学习一些库函数的运用。在我看来,栈与队列的本身并不难,关键在于栈是先进后出表,而队列是先进先出表。
- 栈可以分为顺序栈和链栈,相对于顺序栈来说,链栈不存在栈满上溢出的情况,这点与之前的顺序表与链表直接的关系类似。对于栈
stack库函数来说,我们要熟练运用出栈,入栈等运用,同时出栈前一定要先判断栈是否为空,如果为空则不能进行出栈操作; - 同理,对于队列,再使用
queue库函数的时候,也许注意队空和队满的情况;而再一些特殊队列,如循环队列,我们除了注意队空和队满的情况,也应该留心front和rear指针所指的初始位置。 - 总之,在我看来,栈和队列虽然看起来并不是那么难以理解,但是在运用的时候还需要更加细心,对于各类库函数的操作应该更加熟练,才可以更好的运用栈和队列。
体会
这两周依然还是网课的模式。在这期间,我们学习了栈与队列的基本操作和应用。起初学习的时候,通过画图以及类比于数组的学习方法,更加有助于我们的理解。再后来我我们学习了c++库函数的调用,感觉真的是太方便了,不需要额外自己去编写出栈入栈等函数,使整个代码变得简洁易懂了起来。但是在完成pta题集的时候还是会遇到一些难题,可能是我平时对于栈与队列的操作以及函数的调用还不太熟练。这两周,感觉课业开始逐渐重了起来,各科作业堆积在一起,同时,在家里总是感觉没什么干劲(可能是我不太够自律吧)。。。目前来看,还不知道什么时候能开学,我们还需要再家里待上一段时间,因此要警醒自己,不能再这么放任下去了。熟练的操作都是平时大量的练习和理解造就的,此外,对于的预习和课后的测试我们也应该要重视,既然作业很多,那么就更不能放过任何一个可以复习的机会,这样才能有效的巩固所学的知识。加油!!!

2.PTA实验作业
2.1 PTA题目1
2019-栈和队列
7-5 表达式转换 (25分)
算术表达式有前缀表示法、中缀表示法和后缀表示法等形式。日常使用的算术表达式是采用中缀表示法,即二元运算符位于两个运算数中间。请设计程序将中缀表达式转换为后缀表达式。
2.1.1 代码截图
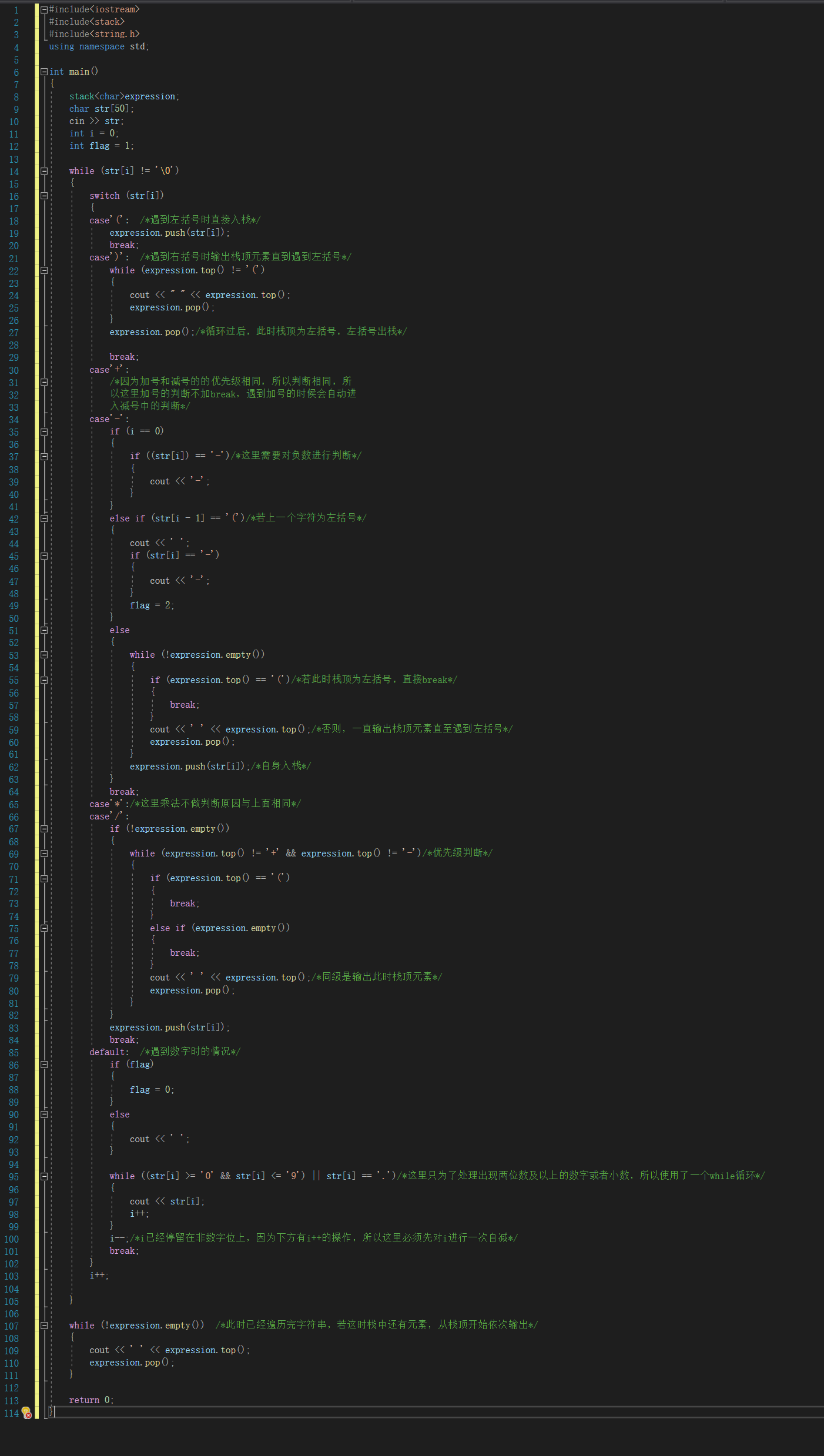
2.1.2 PTA提交列表及说明

Q1:编译错误
A1:这个是在打代码的时候有一行忘记加了分号。
Q2:部分正确
A2:第一个部分正确是漏掉了对第一个数字为负数和‘(’后数字为负数的的情况,以及一些编写上的错误;第二个部分正确是在遇到右括号的时候出现了判断失误,一开始写的只是一个if判断
语句,后面发现了之后改为while判断语句就正确了。
2.2 PTA题目2
2019-栈和队列
7-6 jmu-报数游戏 (15分)
报数游戏是这样的:有n个人围成一圈,按顺序从1到n编好号。从第一个人开始报数,报到m(m<n)的人退出圈子;下一个人从1开始报数,报到m的人退出圈子。如此下去,直到留下最后一个
人。其中n是初始人数;m是游戏规定的退出位次(保证为小于n的正整数)。要求用队列结构完成。输出数字间以空格分隔,但结尾不能有多余空格。
2.2.1 代码截图
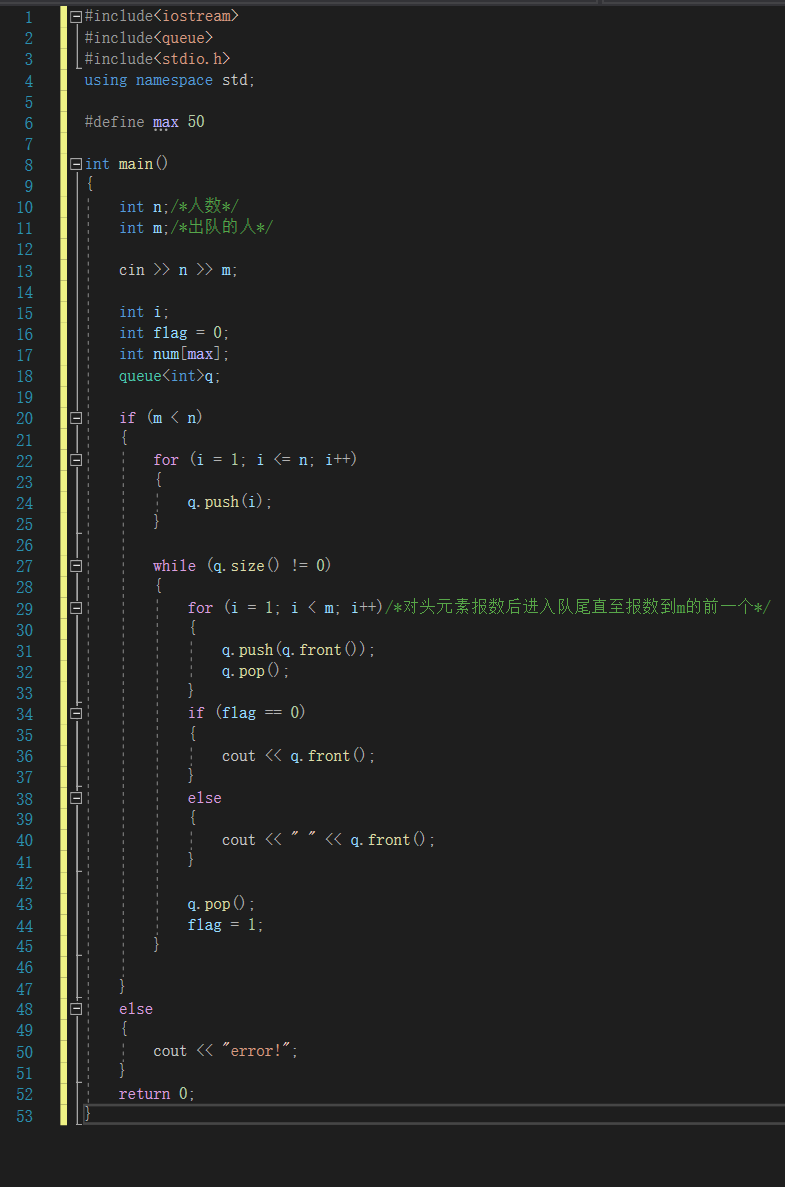
2.2.2 PTA提交列表及说明

Q1:部分正确
A1:在判断一轮之后下一个位置的判断出现了错误,于是我换成了现在的写法。
2.3 PTA题目3
2019-栈和队列
7-4 符号配对 (20分)
请编写程序检查C语言源程序中下列符号是否配对:/*与*/、(与)、[与]、{与}。
2.3.1 代码截图
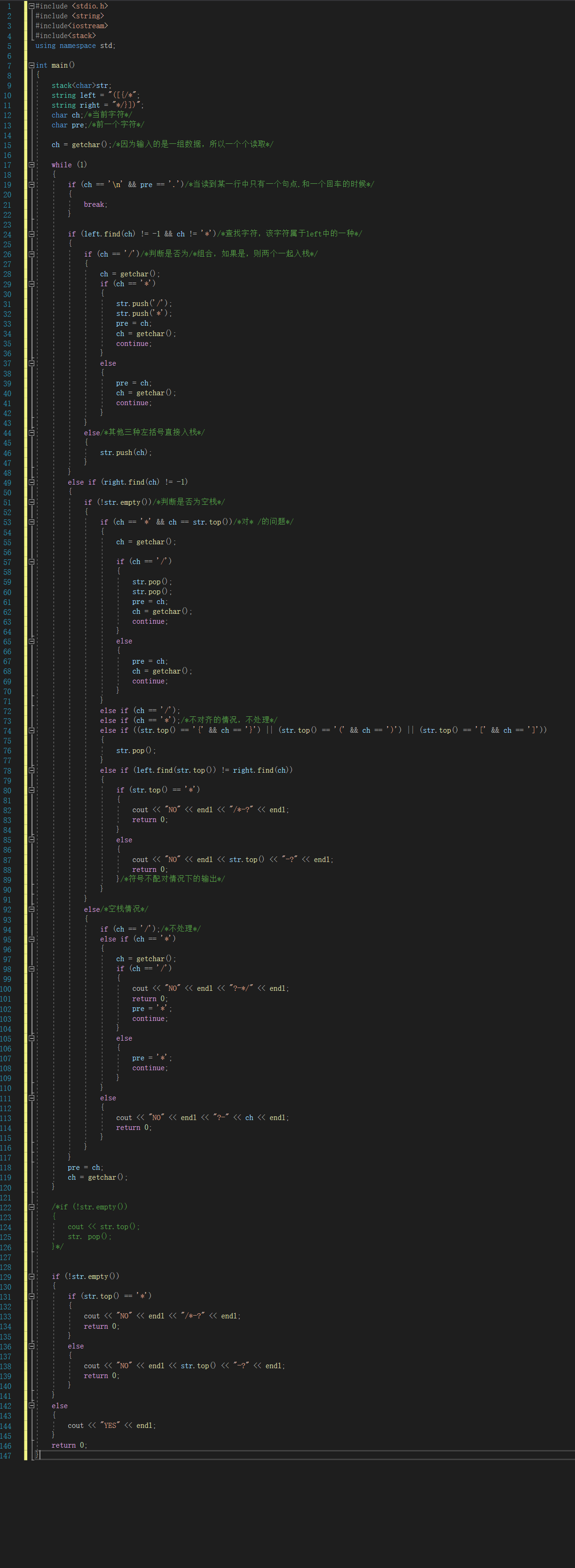
2.3.2 PTA提交列表及说明

Q1: 编译错误
A1:这个纯属失误,pta里面的语言是C语言,而我使用的是C++,忘记修改,所以错误
Q2:部分正确
A2:其实两次部分正确都是出在这行else if ((str.top() == '{' && ch == '}') || (str.top() == '(' && ch == ')') || (str.top() == '[' && ch == ']'))代码上。一开始
我写的是用```find()```函数返回值相等来进入这个分支,后来发现返回值不一定相等;同时,在遇到属于字符串内但不同的左右对称元素是也有可能相等,因此造成测试点都过不去。之后就
改成了这句一一对应判断,就解决了这个问题。
PS:这道题目在写的过程中遇到了不少麻烦,因为多了一个/**/的符号判断,会使代码变得复杂一些。一开始我是想根据老师的讲解,利用map或者是把符号转化为数字进行判断,在运用map的时候遇到了一些问题,在网上搜索的时候无意间看见了find()函数 以及查找的写法,于是我借鉴了网上对于find()函数的运用,重新整理了一下思路,改成了现在的代码...
3.阅读代码:
3.1 题目及解题代码
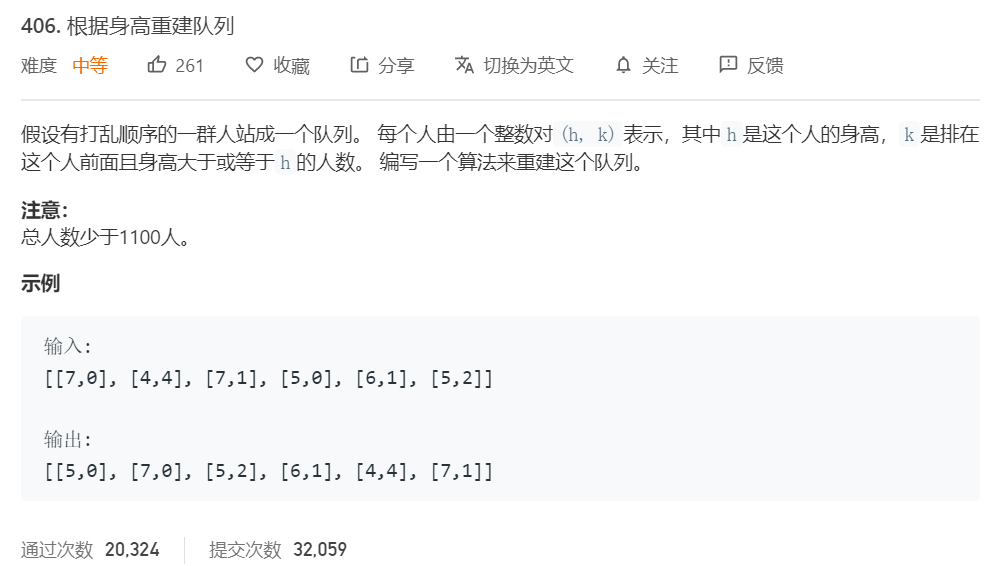
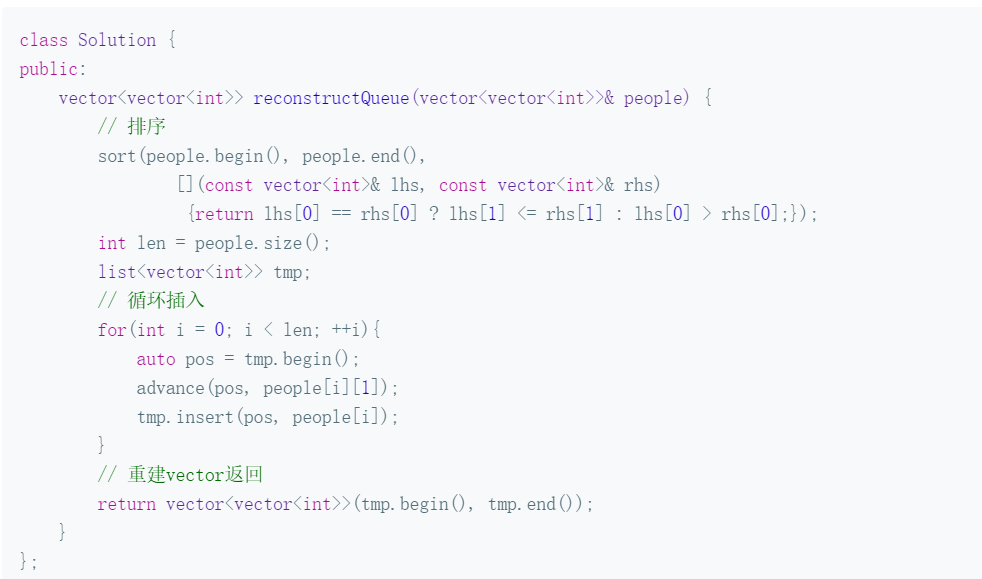
3.1.1 该题的设计思路
核心思路:
- 先排身高更高的,这是要防止后排入人员影响先排入人员位置
- 每次排入新人员
[h,k]时,已处于队列的人身高都>=h,所以新排入位置就是people[k]
时间复杂度:O(N)。 理由:循环地从头读取people,根据people[i][1]也就是k,插入list
空间复杂度:O(N)。 理由:这里将完成所有插入操作的list重建为vector返回
3.1.2 该题的伪代码
class Solution {
public:
先将people按照身高降序排序,
又由于每次插入的位置是k,所以相同身高需要按k升序排序,否则插入位置会越界
确定循环次数
新建容器tmp用来存放数据
// 循环插入
for i = 0 to len
使用advance()找到应插入位置
插入数据
end for
// 重建vector返回
将完成所有插入操作的list重建为vector返回
}
};
3.1.3 运行结果

3.1.4分析该题目解题优势及难点。
- 优势:
- 并没有直接使用
vector,而是将完成所有插入操作的list重建为vector,这样的操作使得整个代码的运行效率大大提高 - 先利用了sort函数进行排序,大大减少了后续代码的执行的难度
- 并没有直接使用
- 难点:
- 每次排入新人员[h,k]时,如何确定新排入的位置
- 相同身高需要按k升序排序,否则插入的位置会越界
3.2 题目及解题代码
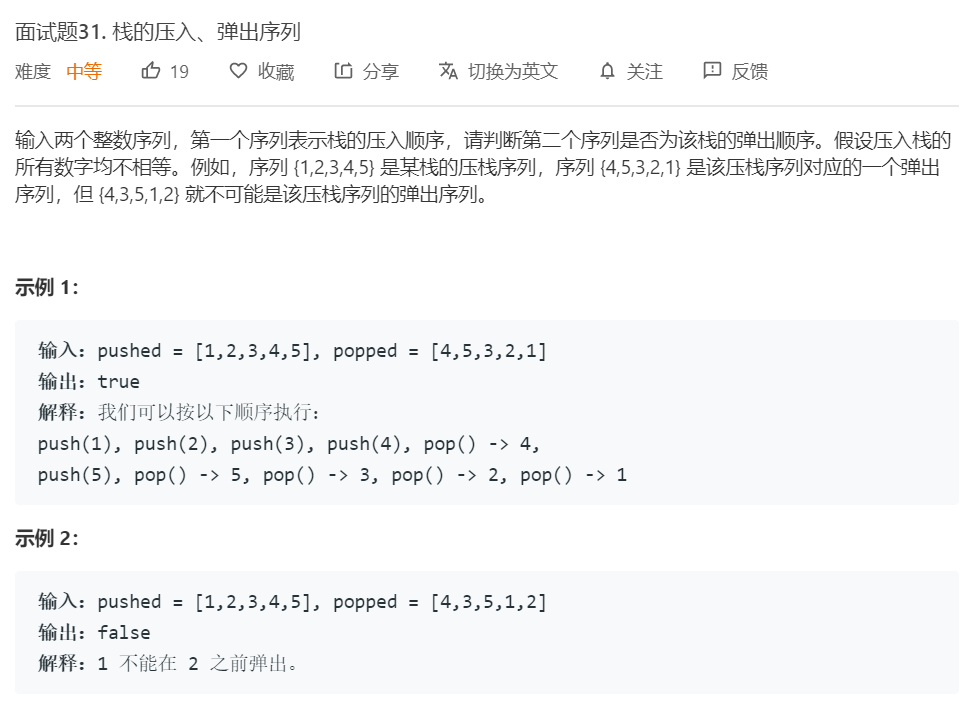

3.2.1 该题的设计思路
解题思路:
- 我们使用一个栈
st,将pushed数组中的每个数依次入栈,同时判断这个数是不是popped数组中下一个要pop的值,如果是就把它pop出来。最后检查栈是否为空。 - 时间复杂度:O(N)。将所以元素一遍入栈,一遍出栈,需要 O(2N)。
- 空间复杂度:O(N)。使用了辅助栈 st。
3.2.2 该题的伪代码
class Solution {
public:
bool validateStackSequences(vector<int>& pushed, vector<int>& popped) {
开辟一个栈stack<int> st;
int n = popped.size();
int j = 0;
for i = 0 to pushed.size()
pushed[i]进栈;
while(st不为空 且 j < n 且 栈顶元素等于popped[j]){
栈顶元素出栈;
j自增;
}
end for
返回
}
};
3.2.3 运行结果

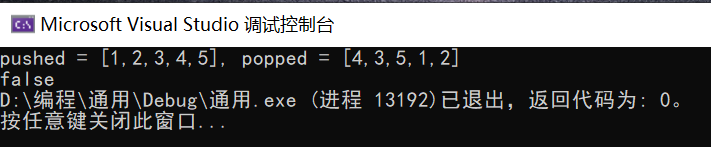
3.2.4分析该题目解题优势及难点。
- 优势:代码精简易懂,思路简单明了,在每个数入栈的时候就进行一次判断,使代码的可读性更高。
- 难点:这道题的难点在于贪心算法在此题的应用。这道题利用贪心算法,实现了如果栈顶元素等于 popped 序列中下一个要 pop 的值,则应立刻将该值 pop 出来这一功能。但是如何在代码中实现以及防止越界和空栈的问题在我看来使这道题的难点。